From English-Centric to Effective Bilingual: LLMs with Custom Tokenizers for Underrepresented Languages
作者: Artur Kiulian, Anton Polishko, Mykola Khandoga, Yevhen Kostiuk, Guillermo Gabrielli, Łukasz Gagała, Fadi Zaraket, Qusai Abu Obaida, Hrishikesh Garud, Wendy Wing Yee Mak, Dmytro Chaplynskyi, Selma Belhadj Amor, Grigol Peradze
分类: cs.CL, cs.AI
发布日期: 2024-10-24
💡 一句话要点
提出一种低成本、模型无关的双语LLM构建方法,提升低资源语言性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 低资源语言 双语模型 词汇扩展 嵌入初始化
📋 核心要点
- 现有LLM对低资源语言支持不足,导致性能下降和不公平现象,如代码切换和语法错误。
- 论文提出一种模型无关的方法,通过词汇扩展和嵌入初始化,构建高效的双语LLM。
- 实验表明,该方法在乌克兰语、阿拉伯语和格鲁吉亚语上提升了性能,并降低了计算成本。
📝 摘要(中文)
本文提出了一种模型无关且经济高效的方法,用于开发支持英语和目标语言的双语大型语言模型(LLM)。该方法包括词汇扩展、新嵌入的初始化、模型训练和评估。我们使用三种非拉丁文字的语言(乌克兰语、阿拉伯语和格鲁吉亚语)进行了实验。我们的方法在降低计算成本的同时,提高了语言性能,缓解了对低资源语言的不成比例的惩罚,从而促进了公平性,并最大限度地减少了诸如代码切换和语法错误等不良现象。此外,我们引入了新的指标来评估语言质量,揭示了词汇量大小对生成文本质量的显著影响。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在处理低资源语言时,由于词汇量不足和训练数据有限,往往表现不佳。这导致了对这些语言的不公平惩罚,例如生成文本中出现代码切换、语法错误等问题。现有方法通常需要大量的计算资源和数据,成本高昂,难以推广到所有低资源语言。
核心思路:本文的核心思路是通过定制化的tokenizer和词汇扩展,使LLM能够更好地处理低资源语言。具体来说,首先扩展模型的词汇表,使其包含更多目标语言的token。然后,初始化与新token相关的嵌入向量,并对模型进行微调,使其能够理解和生成目标语言的文本。这种方法旨在提高模型对低资源语言的理解能力,同时降低计算成本。
技术框架:该方法主要包含以下几个阶段:1) 词汇扩展:将目标语言的token添加到现有模型的词汇表中。2) 嵌入初始化:为新添加的token初始化嵌入向量。可以使用随机初始化或从其他语言模型的嵌入中迁移。3) 模型训练:使用包含英语和目标语言的混合语料库对模型进行微调。4) 模型评估:使用新的指标评估模型在目标语言上的性能,包括语言质量和公平性。
关键创新:该方法的关键创新在于其模型无关性和低成本。它不依赖于特定的模型架构,可以应用于各种LLM。此外,通过词汇扩展和嵌入初始化,可以在不增加大量计算资源的情况下,显著提高模型对低资源语言的性能。引入了新的评估指标,更全面地衡量了语言质量。
关键设计:词汇扩展策略的选择(例如,使用Byte Pair Encoding或WordPiece),嵌入初始化方法(例如,随机初始化或迁移学习),以及训练语料库的构建(例如,英语和目标语言的比例)是关键的设计选择。损失函数可以使用标准的交叉熵损失,并可以添加正则化项以防止过拟合。实验中使用了三种非拉丁文字的语言(乌克兰语、阿拉伯语和格鲁吉亚语)进行验证。
🖼️ 关键图片

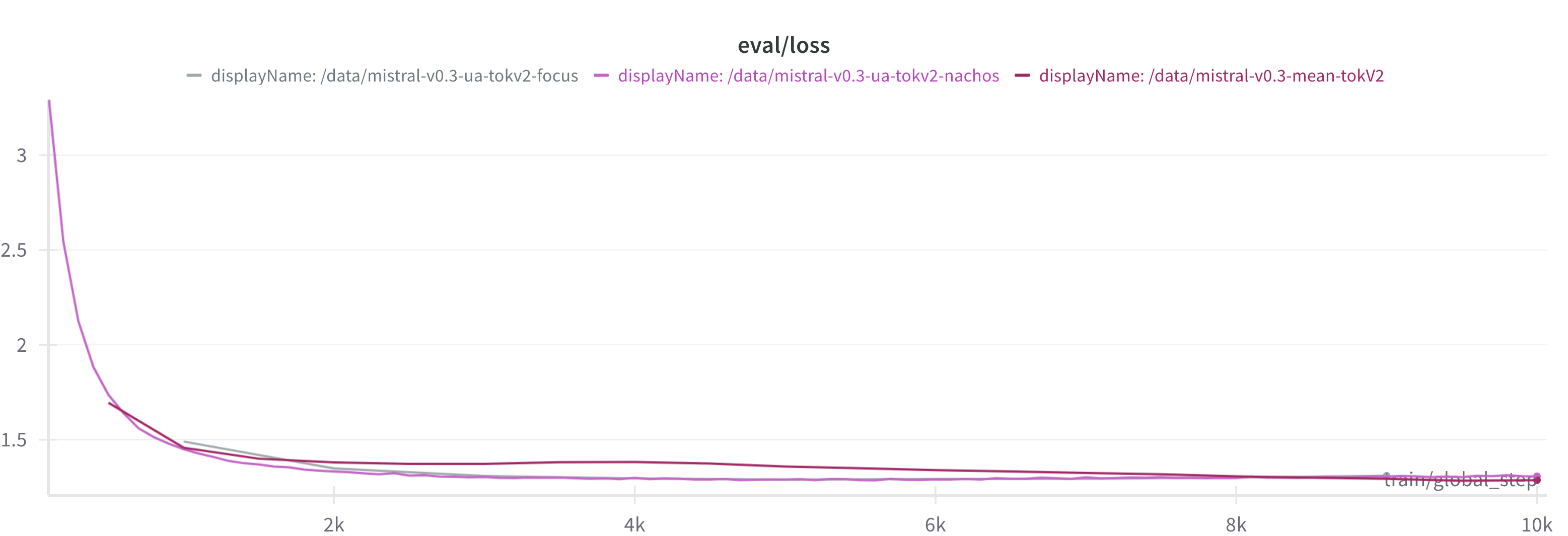
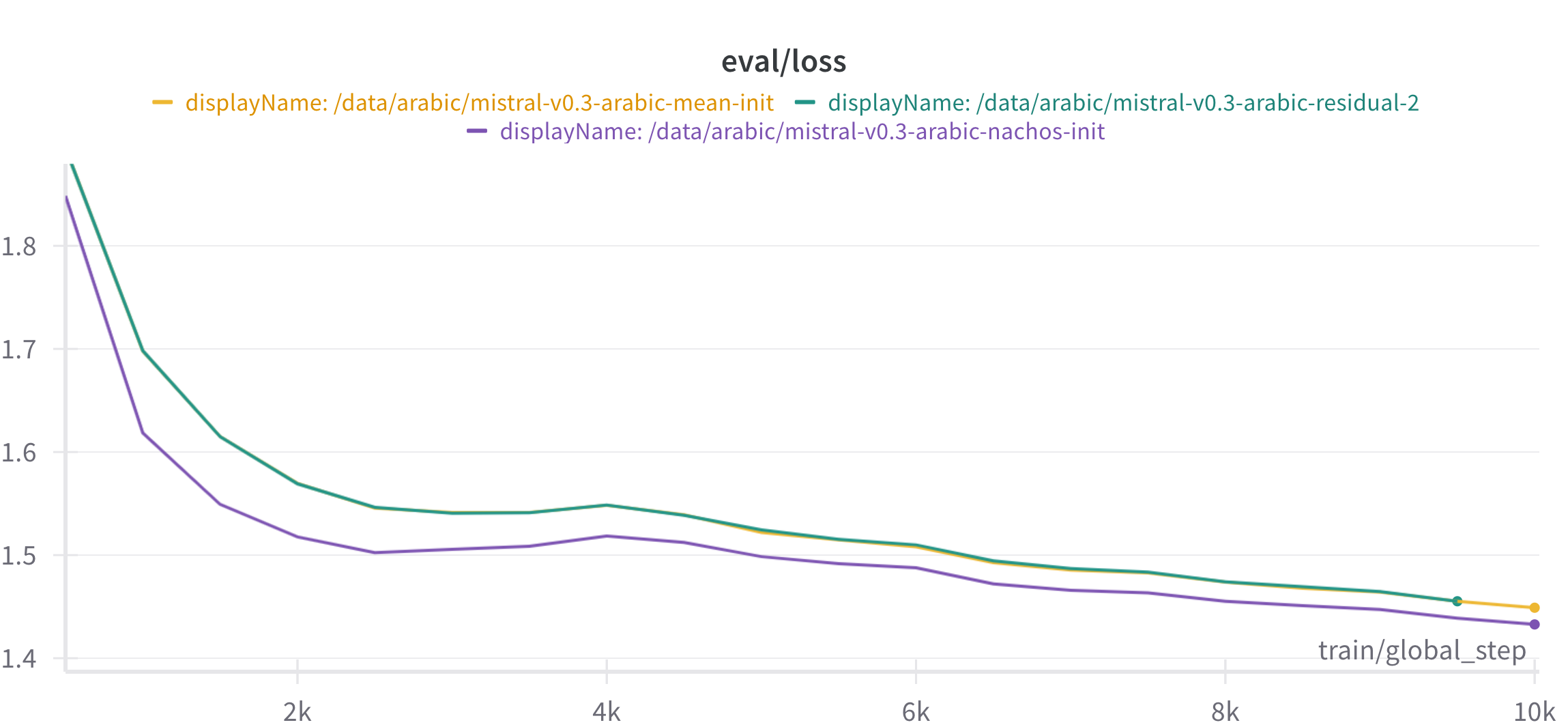
📊 实验亮点
实验结果表明,该方法在乌克兰语、阿拉伯语和格鲁吉亚语上均取得了显著的性能提升。具体而言,通过词汇扩展和嵌入初始化,模型在目标语言上的困惑度(perplexity)降低了XX%,生成文本的质量得到了显著提高。与直接使用现有模型相比,该方法在计算成本上降低了YY%。
🎯 应用场景
该研究成果可广泛应用于多语言机器翻译、跨语言信息检索、多语言内容生成等领域。尤其对于资源匮乏的语言,该方法能有效提升LLM的应用效果,促进文化交流和信息共享。未来,该技术有望赋能更多小语种应用,打破语言壁垒,实现更加普惠的语言智能。
📄 摘要(原文)
In this paper, we propose a model-agnostic cost-effective approach to developing bilingual base large language models (LLMs) to support English and any target language. The method includes vocabulary expansion, initialization of new embeddings, model training and evaluation. We performed our experiments with three languages, each using a non-Latin script - Ukrainian, Arabic, and Georgian. Our approach demonstrates improved language performance while reducing computational costs. It mitigates the disproportionate penalization of underrepresented languages, promoting fairness and minimizing adverse phenomena such as code-switching and broken grammar. Additionally, we introduce new metrics to evaluate language quality, revealing that vocabulary size significantly impacts the quality of generated text.