ToolFlow: Boosting LLM Tool-Calling Through Natural and Coherent Dialogue Synthesis
作者: Zezhong Wang, Xingshan Zeng, Weiwen Liu, Liangyou Li, Yasheng Wang, Lifeng Shang, Xin Jiang, Qun Liu, Kam-Fai Wong
分类: cs.CL
发布日期: 2024-10-24 (更新: 2025-03-17)
备注: Accepted by NAACL 2025
💡 一句话要点
ToolFlow:通过自然连贯的对话合成,提升LLM的工具调用能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 工具调用 大型语言模型 数据合成 监督微调 对话生成 图采样 多智能体
📋 核心要点
- 现有LLM工具调用数据合成方法随机采样工具,导致工具组合缺乏相关性,降低数据多样性。
- ToolFlow提出基于图的采样策略和计划生成策略,提升工具组合的相关性和对话的连贯性。
- 实验结果表明,使用ToolFlow合成数据微调的LLaMA-3.1-8B模型,工具调用性能可媲美甚至超越GPT-4。
📝 摘要(中文)
监督微调(SFT)是增强大型语言模型(LLM)工具调用能力的常用方法,而训练数据通常是合成的。目前的数据合成过程通常涉及采样一组工具,根据这些工具制定需求,并生成调用语句。然而,随机采样的工具缺乏相关性,难以组合,从而降低了数据的多样性。此外,目前的工作忽略了对话轮次之间的连贯性,导致合成数据与真实场景之间存在差距。为了解决这些问题,我们提出了一种基于图的采样策略,以采样更相关的工具组合,以及一种计划生成策略,以创建指导连贯对话合成的计划。我们将这两种策略集成在一起,并允许多个代理交互式地合成对话数据,从而产生了我们的工具调用数据合成管道ToolFlow。数据质量评估表明,我们合成的对话的自然性和连贯性得到了改善。最后,我们使用ToolFlow生成的8,000个合成对话在LLaMA-3.1-8B上应用SFT。结果表明,该模型实现了与GPT-4相当甚至超过GPT-4的工具调用性能,同时保持了强大的通用能力。
🔬 方法详解
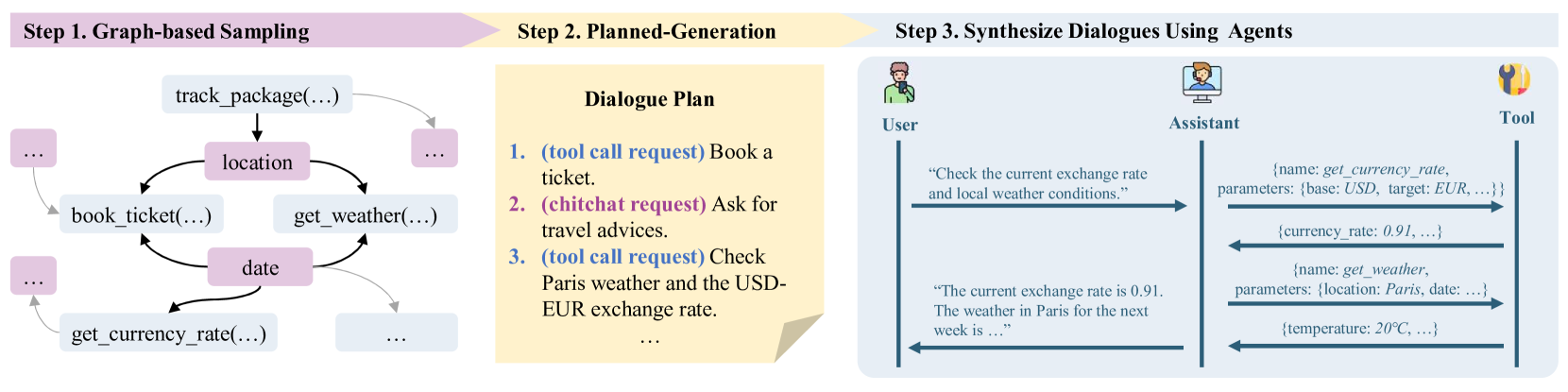
问题定义:现有LLM工具调用能力的提升依赖于监督微调,而训练数据通常是合成的。然而,现有数据合成方法存在两个主要问题:一是随机采样的工具之间缺乏关联性,导致数据多样性不足;二是忽略了对话轮次之间的连贯性,使得合成数据与真实场景存在较大差距。
核心思路:ToolFlow的核心思路是通过更智能的工具采样和对话生成策略,来合成更自然、更连贯的工具调用对话数据。具体来说,它通过基于图的采样策略来选择相关的工具组合,并通过计划生成策略来保证对话的连贯性。
技术框架:ToolFlow包含以下主要模块:1) 基于图的工具采样:构建工具关系图,并使用图算法采样相关的工具组合。2) 计划生成:生成对话计划,明确每个对话轮次的目标和内容。3) 多智能体对话合成:多个智能体根据对话计划,交互式地生成对话数据。4) 数据质量评估:评估合成数据的自然性和连贯性。
关键创新:ToolFlow的关键创新在于:1) 提出了基于图的工具采样策略,能够选择更相关的工具组合,从而提高数据的多样性。2) 提出了计划生成策略,能够保证对话轮次之间的连贯性,使得合成数据更接近真实场景。3) 采用了多智能体交互式对话合成方法,能够生成更自然、更丰富的对话数据。
关键设计:在基于图的工具采样中,工具关系图的构建方式以及图算法的选择是关键。在计划生成中,对话计划的粒度和详细程度会影响对话的质量。在多智能体对话合成中,智能体的角色分配和交互方式是关键。
🖼️ 关键图片


📊 实验亮点
使用ToolFlow生成的8,000个合成对话微调LLaMA-3.1-8B模型后,该模型在工具调用性能上达到了与GPT-4相当甚至超越GPT-4的水平,同时保持了强大的通用能力。这表明ToolFlow能够有效地提升LLM的工具调用能力。
🎯 应用场景
ToolFlow可用于合成高质量的工具调用对话数据,从而提升LLM在各种实际应用场景中的工具调用能力,例如智能助手、自动化流程、智能客服等。通过ToolFlow,可以降低LLM工具调用能力开发的成本,并加速LLM在各行业的落地。
📄 摘要(原文)
Supervised fine-tuning (SFT) is a common method to enhance the tool calling capabilities of Large Language Models (LLMs), with the training data often being synthesized. The current data synthesis process generally involves sampling a set of tools, formulating a requirement based on these tools, and generating the call statements. However, tools sampled randomly lack relevance, making them difficult to combine and thus reducing the diversity of the data. Additionally, current work overlooks the coherence between turns of dialogues, leading to a gap between the synthesized data and real-world scenarios. To address these issues, we propose a Graph-based Sampling strategy to sample more relevant tool combinations, and a Planned-generation strategy to create plans that guide the synthesis of coherent dialogues. We integrate these two strategies and enable multiple agents to synthesize the dialogue data interactively, resulting in our tool-calling data synthesis pipeline ToolFlow. Data quality assessments demonstrate improvements in the naturalness and coherence of our synthesized dialogues. Finally, we apply SFT on LLaMA-3.1-8B using 8,000 synthetic dialogues generated with ToolFlow. Results show that the model achieves tool-calling performance comparable to or even surpassing GPT-4, while maintaining strong general capabilities.