LEGO: Language Model Building Blocks
作者: Shrenik Bhansali, Alwin Jin, Tyler Lizzo, Larry Heck
分类: cs.CL, cs.LG
发布日期: 2024-10-23
💡 一句话要点
LEGO:从大型语言模型中提取并重组小型语言模型构建块
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 小型语言模型 模型剪枝 联邦学习 模型聚合 数据隐私 模型异构性
📋 核心要点
- 大型语言模型成本高昂,而小型语言模型缺乏鲁棒性和泛化能力,难以兼顾性能和效率。
- LEGO通过剪枝LLM提取SLM构建块,并利用联邦学习和新颖的聚合方案重构LLM,实现高效微调和推理。
- 实验证明LEGO能够实现模型异构性,减轻数据异构性影响,同时保持LLM的鲁棒性。
📝 摘要(中文)
大型语言模型(LLM)在自然语言处理(NLP)中至关重要,但在数据收集、预训练、微调和推理方面成本高昂。特定任务的小型语言模型(SLM)提供了一种更经济的替代方案,但缺乏鲁棒性和泛化能力。本文提出了一种名为LEGO的新技术,用于从LLM中提取SLM并重新组合它们。通过使用最先进的LLM剪枝策略,我们可以创建特定任务和用户特定的SLM构建块,这些构建块对于微调和推理是高效的,同时也能保护用户数据隐私。LEGO利用联邦学习和一种新颖的LLM重构聚合方案,在不增加高成本的情况下保持鲁棒性,并保护用户数据隐私。实验结果表明了LEGO的多功能性,展示了其实现模型异构性和减轻数据异构性影响的能力,同时保持LLM的鲁棒性。
🔬 方法详解
问题定义:现有大型语言模型(LLM)在计算资源和数据需求方面成本高昂,限制了其在资源受限环境中的应用。而针对特定任务的小型语言模型(SLM)虽然效率更高,但通常泛化能力较差,难以适应不同的任务和用户需求。此外,直接在用户数据上训练模型存在隐私泄露的风险。
核心思路:LEGO的核心思想是将LLM分解为多个可重用的SLM构建块,每个构建块针对特定的任务或用户。通过剪枝LLM,提取出这些SLM构建块,并利用联邦学习和一种新颖的聚合方案,将这些构建块重新组合成一个鲁棒的LLM。这种方法既能降低计算成本,又能提高模型的泛化能力,同时保护用户数据隐私。
技术框架:LEGO的技术框架主要包括以下几个阶段:1) LLM剪枝:使用先进的剪枝策略,从LLM中提取出针对特定任务或用户的SLM构建块。2) 联邦学习:利用联邦学习框架,在多个客户端上并行训练SLM构建块,每个客户端使用自己的本地数据。3) 聚合方案:提出一种新颖的聚合方案,将各个客户端训练好的SLM构建块聚合起来,重构出一个鲁棒的LLM。4) 模型部署:将重构后的LLM部署到目标环境中,用于推理或微调。
关键创新:LEGO的关键创新在于其将LLM分解为可重用的SLM构建块,并利用联邦学习和新颖的聚合方案进行模型重构。与传统的模型压缩方法相比,LEGO能够更好地保持模型的泛化能力和鲁棒性。此外,LEGO还能够实现模型异构性,即不同的客户端可以使用不同的SLM构建块,从而更好地适应不同的任务和用户需求。
关键设计:LEGO的关键设计包括:1) 剪枝策略:选择合适的剪枝策略,以确保提取出的SLM构建块具有较高的性能。2) 联邦学习框架:选择合适的联邦学习框架,以确保训练过程的效率和安全性。3) 聚合方案:设计一种有效的聚合方案,以确保重构后的LLM具有较高的鲁棒性和泛化能力。具体的参数设置、损失函数、网络结构等技术细节在论文中进行了详细描述。
🖼️ 关键图片


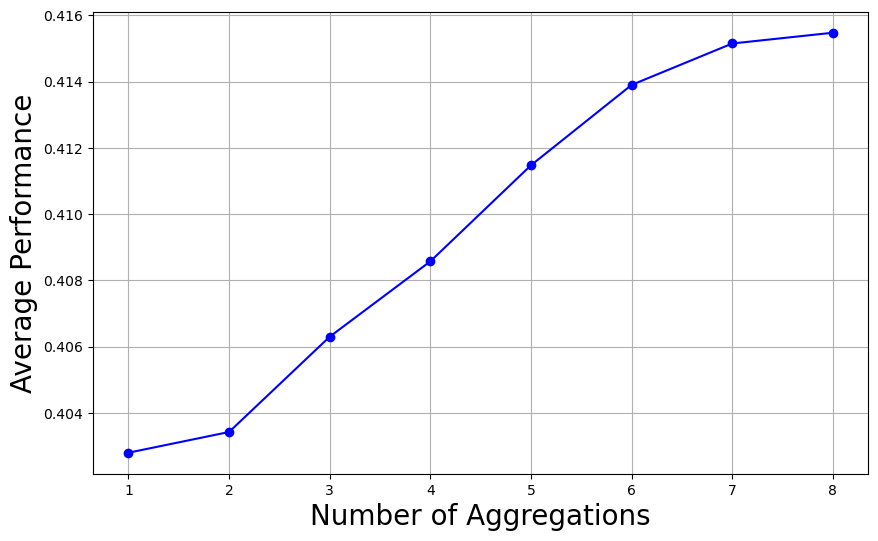
📊 实验亮点
论文通过实验验证了LEGO的有效性,表明其能够在保持LLM鲁棒性的同时,实现模型异构性和减轻数据异构性的影响。具体的性能数据和对比基线在论文中进行了详细的展示,证明了LEGO相对于传统方法的优势。
🎯 应用场景
LEGO技术可应用于各种自然语言处理任务,尤其是在资源受限或数据隐私敏感的场景下。例如,可以在移动设备上部署个性化的语言模型,或者在医疗领域构建保护患者隐私的文本分析系统。LEGO还为模型异构性提供了可能,允许针对不同用户或任务定制模型。
📄 摘要(原文)
Large language models (LLMs) are essential in natural language processing (NLP) but are costly in data collection, pre-training, fine-tuning, and inference. Task-specific small language models (SLMs) offer a cheaper alternative but lack robustness and generalization. This paper proposes LEGO, a novel technique to extract SLMs from an LLM and recombine them. Using state-of-the-art LLM pruning strategies, we can create task- and user-specific SLM building blocks that are efficient for fine-tuning and inference while also preserving user data privacy. LEGO utilizes Federated Learning and a novel aggregation scheme for the LLM reconstruction, maintaining robustness without high costs and preserving user data privacy. We experimentally demonstrate the versatility of LEGO, showing its ability to enable model heterogeneity and mitigate the effects of data heterogeneity while maintaining LLM robustness.