Towards Understanding the Fragility of Multilingual LLMs against Fine-Tuning Attacks
作者: Samuele Poppi, Zheng-Xin Yong, Yifei He, Bobbie Chern, Han Zhao, Aobo Yang, Jianfeng Chi
分类: cs.CL, cs.AI, cs.CR, cs.LG
发布日期: 2024-10-23 (更新: 2025-02-27)
备注: 15 pages, 6 figures, 7 tables
💡 一句话要点
揭示多语言LLM在微调攻击下的脆弱性,提出安全信息定位方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言LLM 微调攻击 安全对齐 安全信息定位 对抗样本
📋 核心要点
- 现有LLM安全对齐易受对抗性微调攻击,但多语言LLM的脆弱性尚不明确。
- 提出安全信息定位(SIL)方法,通过识别模型参数空间中与安全相关的信息来理解攻击。
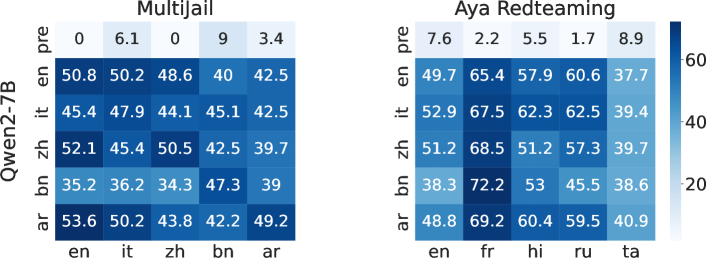
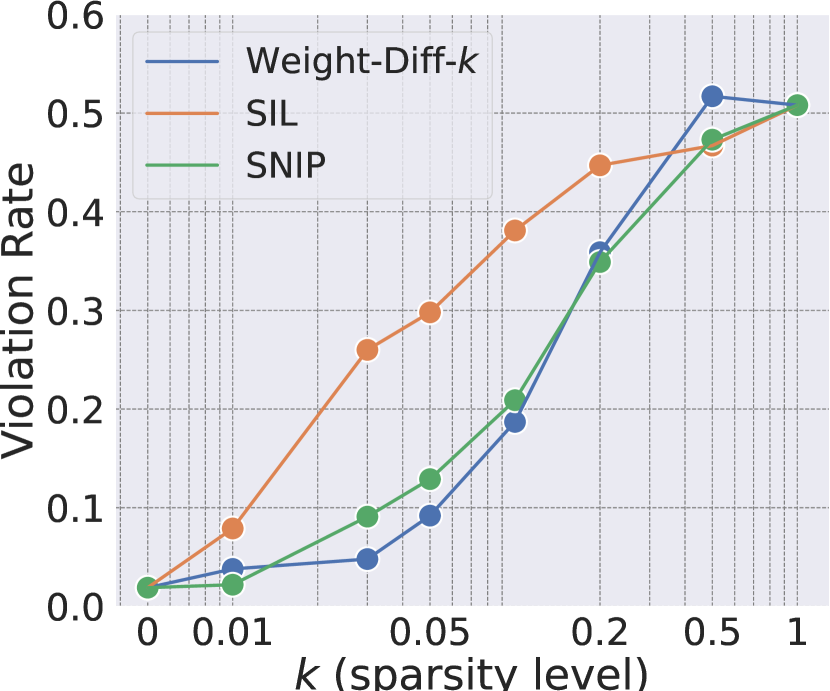
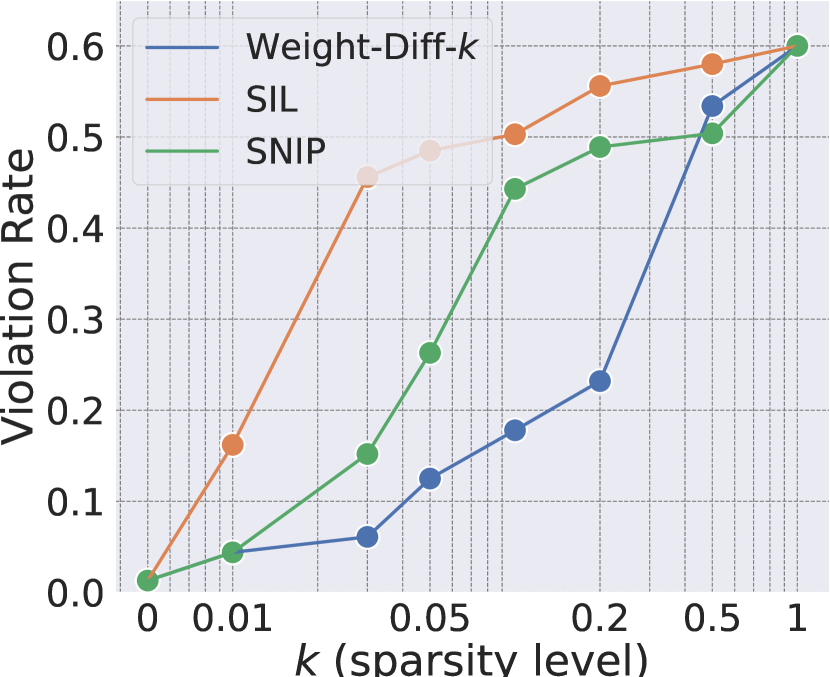
- 实验表明仅需修改20%的权重参数即可跨语言破坏安全对齐,验证了安全信息的语言无关性。
📝 摘要(中文)
大型语言模型(LLMs)的快速发展引发了对其安全性的广泛关注。最近的研究表明,通过使用少量对抗性选择的指令遵循示例进行微调,可以轻易移除LLMs的安全对齐。本文进一步研究了多语言LLMs中的微调攻击。首先,我们发现了微调攻击的跨语言泛化能力:使用一种语言中的少量对抗性指令遵循示例,多语言LLMs也很容易被破坏(例如,多语言LLMs无法拒绝其他语言中的有害提示)。受此发现的启发,我们假设与安全相关的信息是语言无关的,并提出了一种名为安全信息定位(SIL)的新方法,以识别模型参数空间中与安全相关的信息。通过SIL,我们验证了这一假设,并发现仅更改微调攻击中20%的权重参数就可以破坏所有语言的安全对齐。此外,我们为冻结安全相关参数无法阻止微调攻击的替代路径假设提供了证据,并证明我们的攻击向量仍然可以破解适应新语言的LLMs。
🔬 方法详解
问题定义:现有的LLM安全对齐方法容易受到微调攻击的影响,即通过少量对抗样本的微调就可以破坏模型的安全机制。尤其是在多语言LLM中,攻击者可能利用一种语言的对抗样本来破坏模型在其他语言中的安全性。因此,如何理解和防御多语言LLM中的微调攻击,是一个重要的研究问题。
核心思路:论文的核心思路是,假设LLM中与安全相关的信息是语言无关的,即无论使用哪种语言的对抗样本进行微调,攻击都会影响到模型中相同的参数区域。基于这个假设,论文提出了一种安全信息定位(SIL)方法,用于识别模型参数空间中与安全相关的信息。
技术框架:SIL方法主要包含以下几个步骤:1) 使用对抗样本对多语言LLM进行微调攻击;2) 分析微调前后模型参数的变化,识别出对攻击影响最大的参数子集;3) 通过实验验证这些参数子集对模型安全性的影响,例如,冻结这些参数或仅修改这些参数,观察模型的安全性能变化。
关键创新:论文的关键创新在于提出了安全信息定位(SIL)方法,该方法能够有效地识别多语言LLM中与安全相关的信息,并验证了这些信息具有语言无关性。此外,论文还提供了证据支持替代路径假设,解释了为什么冻结安全相关参数不能完全阻止微调攻击。
关键设计:SIL方法的关键设计包括:1) 使用对抗样本生成方法,例如,使用梯度下降或遗传算法生成能够绕过LLM安全机制的指令;2) 使用参数重要性评估方法,例如,计算每个参数对模型输出的影响,或者使用剪枝算法来识别不重要的参数;3) 设计实验来验证识别出的安全相关参数的有效性,例如,冻结这些参数,观察模型在对抗攻击下的表现。
🖼️ 关键图片
📊 实验亮点
实验结果表明,仅修改20%的权重参数就可以跨语言破坏多语言LLM的安全对齐,验证了安全信息的语言无关性。此外,论文还证明了即使冻结安全相关参数,攻击者仍然可以通过其他路径绕过安全机制。该研究还表明,攻击向量可以泛化到适应新语言的LLM。
🎯 应用场景
该研究成果可应用于提升多语言LLM的安全性,例如,通过冻结或加强安全相关参数的保护,可以提高模型抵抗微调攻击的能力。此外,该研究还可以帮助开发者更好地理解LLM的内部机制,从而设计更安全、更可靠的LLM系统。该研究对于构建负责任的人工智能系统具有重要意义。
📄 摘要(原文)
Recent advancements in Large Language Models (LLMs) have sparked widespread concerns about their safety. Recent work demonstrates that safety alignment of LLMs can be easily removed by fine-tuning with a few adversarially chosen instruction-following examples, i.e., fine-tuning attacks. We take a further step to understand fine-tuning attacks in multilingual LLMs. We first discover cross-lingual generalization of fine-tuning attacks: using a few adversarially chosen instruction-following examples in one language, multilingual LLMs can also be easily compromised (e.g., multilingual LLMs fail to refuse harmful prompts in other languages). Motivated by this finding, we hypothesize that safety-related information is language-agnostic and propose a new method termed Safety Information Localization (SIL) to identify the safety-related information in the model parameter space. Through SIL, we validate this hypothesis and find that only changing 20% of weight parameters in fine-tuning attacks can break safety alignment across all languages. Furthermore, we provide evidence to the alternative pathways hypothesis for why freezing safety-related parameters does not prevent fine-tuning attacks, and we demonstrate that our attack vector can still jailbreak LLMs adapted to new languages.