CogSteer: Cognition-Inspired Selective Layer Intervention for Efficiently Steering Large Language Models
作者: Xintong Wang, Jingheng Pan, Liang Ding, Longyue Wang, Longqin Jiang, Xingshan Li, Chris Biemann
分类: cs.CL, cs.AI
发布日期: 2024-10-23 (更新: 2025-05-31)
备注: Accepted to Findings of ACL 2025
💡 一句话要点
CogSteer:受认知启发的选择性层干预,高效引导大型语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 可解释性 认知启发 选择性层干预 参数高效微调 安全引导 对比学习
📋 核心要点
- 大型语言模型缺乏可解释性,难以针对特定应用进行有效引导,限制了其应用范围。
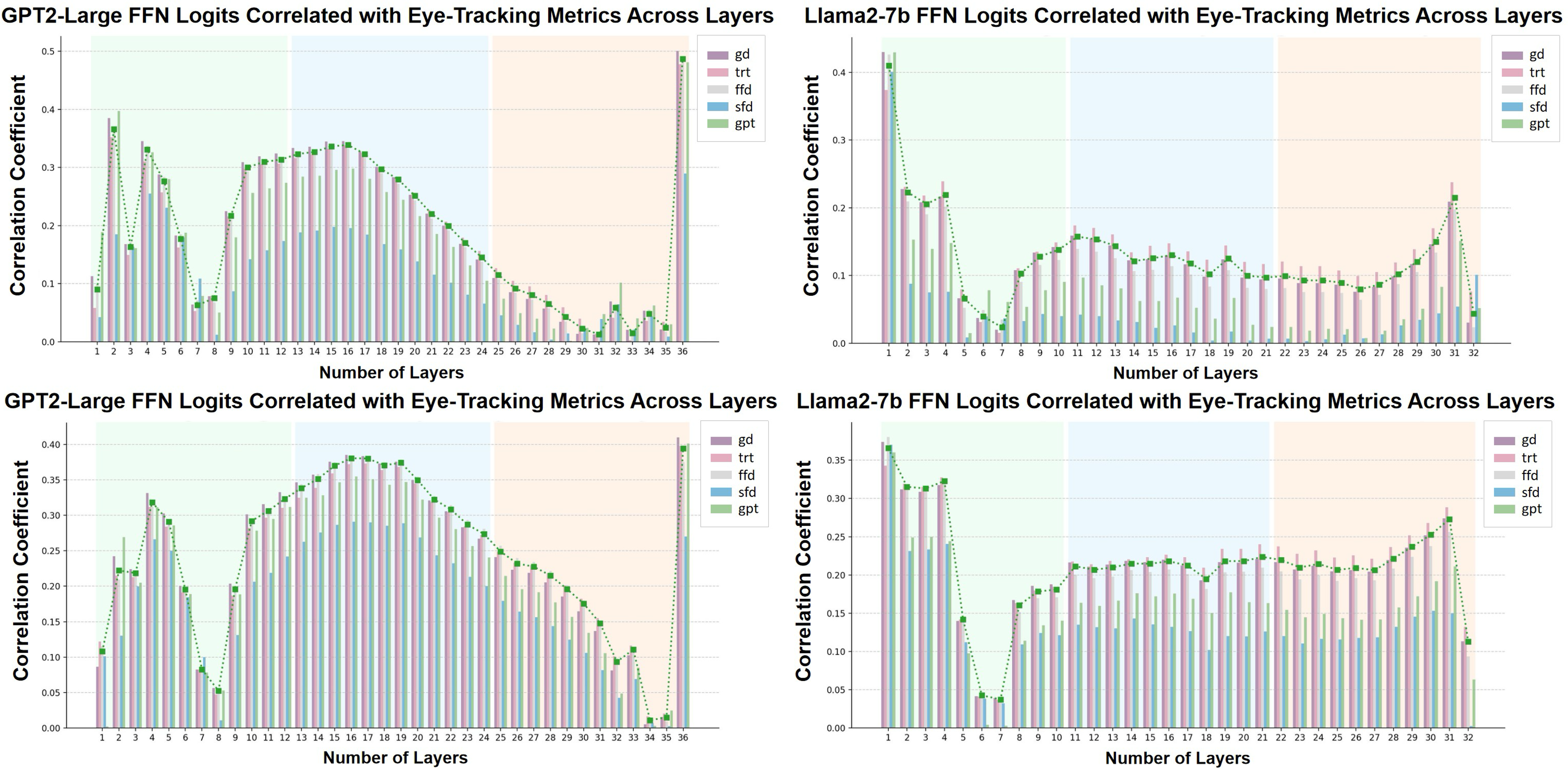
- CogSteer从认知角度出发,通过分析人类认知与LLM表征的关联,选择最佳层进行干预。
- 实验表明,CogSteer在多个任务和模型上均表现出有效性和效率,并提升了模型安全性。
📝 摘要(中文)
大型语言模型(LLMs)通过在大量数据上的预训练实现了卓越的性能,从而能够有效地适应各种下游任务。然而,其底层机制缺乏可解释性,限制了有效引导LLMs用于特定应用的能力。本文从认知角度出发,利用眼动追踪指标研究LLMs的内在机制。具体而言,我们分析了人类认知指标与LLM表征之间的层间相关性。基于这些见解,我们提出了一种启发式方法来选择最佳引导层,以调节LLM的语义。为此,我们引入了一种高效的选择性层干预方法,该方法基于参数高效微调方法,这些方法通常调整所有层或仅调整最后一层。此外,我们提出了一种隐式层对比干预,在推理过程中引导LLMs远离有害输出。在GPT-2、Llama2-7B和Mistral-7B上进行的自然语言理解、推理和生成任务的大量实验证明了我们方法的有效性和效率。作为一个与模型无关的框架,它增强了LLMs的可解释性,同时提高了安全部署的效率。
🔬 方法详解
问题定义:现有大型语言模型缺乏可解释性,难以针对特定任务进行有效引导。传统的微调方法要么调整所有层,计算成本高昂,要么只调整最后一层,效果有限。此外,模型可能生成有害内容,需要安全引导机制。
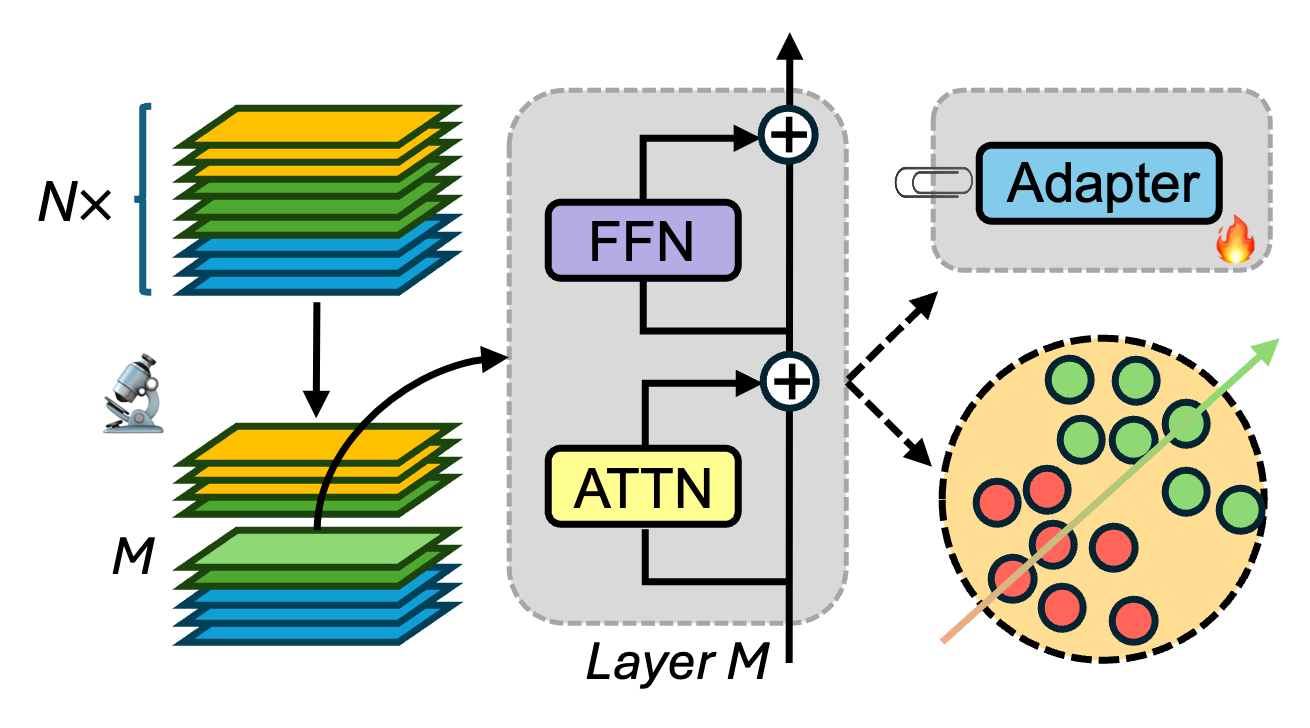
核心思路:CogSteer的核心思想是模拟人类认知过程,通过分析人类认知指标(如眼动追踪数据)与LLM内部表征的关联,确定对特定任务影响最大的层。然后,只对这些关键层进行干预,从而实现高效且可解释的模型引导。
技术框架:CogSteer包含两个主要阶段:1) 选择性层干预:首先,利用人类认知数据分析LLM各层的相关性,选择最佳干预层。然后,采用参数高效微调方法(如LoRA)对选定的层进行微调。2) 隐式层对比干预:在推理阶段,通过对比不同层的输出,引导模型远离有害输出。该框架是模型无关的,可以应用于不同的LLM。
关键创新:CogSteer的关键创新在于:1) 认知启发:利用人类认知数据指导模型干预,增强了模型的可解释性。2) 选择性层干预:只对关键层进行干预,提高了效率。3) 隐式层对比干预:在推理阶段进行安全引导,降低了有害内容生成的风险。
关键设计:在选择性层干预中,使用启发式方法选择最佳干预层,例如选择与人类认知指标相关性最高的层。在隐式层对比干预中,设计对比损失函数,鼓励模型生成安全的输出。具体的参数设置和损失函数选择取决于具体的任务和模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CogSteer在自然语言理解、推理和生成任务上均取得了显著的性能提升。例如,在Llama2-7B和Mistral-7B上,CogSteer在多个基准测试中均优于传统的微调方法,并且计算成本更低。此外,CogSteer有效地降低了模型生成有害内容的风险,提高了模型的安全性。
🎯 应用场景
CogSteer可应用于各种需要安全可靠的大型语言模型应用场景,例如智能客服、内容生成、教育辅导等。通过提高模型的可解释性和安全性,可以降低模型误用和滥用的风险,促进LLM在实际场景中的广泛应用。未来,该方法可以进一步扩展到其他模态的模型,例如图像和语音。
📄 摘要(原文)
Large Language Models (LLMs) achieve remarkable performance through pretraining on extensive data. This enables efficient adaptation to diverse downstream tasks. However, the lack of interpretability in their underlying mechanisms limits the ability to effectively steer LLMs for specific applications. In this work, we investigate the intrinsic mechanisms of LLMs from a cognitive perspective using eye movement measures. Specifically, we analyze the layer-wise correlation between human cognitive indicators and LLM representations. Building on these insights, we propose a heuristic approach for selecting the optimal steering layer to modulate LLM semantics. To this end, we introduce an efficient selective layer intervention based on prominent parameter-efficient fine-tuning methods, which conventionally adjust either all layers or only the final layer. Additionally, we present an implicit layer contrastive intervention during inference to steer LLMs away from toxic outputs. Extensive experiments on natural language understanding, reasoning, and generation tasks, conducted on GPT-2, Llama2-7B, and Mistral-7B, demonstrate the effectiveness and efficiency of our approach. As a model-agnostic framework, it enhances the interpretability of LLMs while improving efficiency for safe deployment.