Cross-model Control: Improving Multiple Large Language Models in One-time Training
作者: Jiayi Wu, Hao Sun, Hengyi Cai, Lixin Su, Shuaiqiang Wang, Dawei Yin, Xiang Li, Ming Gao
分类: cs.CL
发布日期: 2024-10-23
备注: Accepted by NeurIPS 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出跨模型控制(CMC),通过一次训练提升多个大语言模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 跨模型控制 指令调优 反学习 知识迁移
📋 核心要点
- 现有大语言模型微调成本高昂,难以将一个模型的优化成果迁移到其他模型。
- 论文提出跨模型控制(CMC)方法,利用小型语言模型学习logit偏移,实现知识迁移。
- 实验表明,CMC在指令调优和反学习任务上有效,能提升多个大语言模型性能。
📝 摘要(中文)
随着不同参数规模和词汇量的大语言模型(LLMs)数量不断增加,它们在满足特定需求或标准(如指令遵循或避免输出敏感信息)方面面临着共同的优化需求。然而,如何复用一个模型的微调结果到其他模型以降低训练成本仍然是一个挑战。为了弥合这一差距,我们引入了跨模型控制(CMC),这是一种通过一个可移植的小型语言模型在一次训练中改进多个LLM的方法。具体来说,我们观察到微调前后logit的偏移在不同模型之间非常相似。基于这一洞察,我们引入了一个参数数量极少的小型语言模型。通过与冻结的模板LLM一起训练,该小型模型获得了改变LLM输出logit的能力。为了使这个小型语言模型适用于具有不同词汇表的模型,我们提出了一种名为PM-MinED的新型token映射策略。我们在指令调优和反学习任务上进行了大量实验,证明了CMC的有效性。我们的代码可在https://github.com/wujwyi/CMC 获取。
🔬 方法详解
问题定义:现有的大语言模型种类繁多,针对特定任务(如指令遵循、信息过滤)的微调需求普遍存在。然而,对每个模型单独进行微调成本高昂,且难以将一个模型的微调成果复用到其他模型上。因此,如何降低微调成本,实现跨模型的知识迁移是一个亟待解决的问题。
核心思路:论文的核心思路是观察到不同大语言模型在微调前后,其logit的偏移量具有相似性。因此,可以通过训练一个小型语言模型来学习这种logit偏移,从而实现对多个大语言模型的控制。该小型模型可以学习如何调整大模型的输出,以满足特定的任务需求,而无需对每个大模型单独进行微调。
技术框架:CMC方法的核心框架包括一个冻结的模板大语言模型和一个可训练的小型语言模型。训练过程中,小型语言模型与模板大语言模型并行工作,小型模型的目标是学习如何调整模板大模型的logit输出,使其更符合目标任务的要求。为了使小型模型能够应用于具有不同词汇表的大模型,论文还提出了一种名为PM-MinED的token映射策略。
关键创新:CMC方法最重要的创新点在于其跨模型控制的思想,即通过训练一个小型模型来控制多个大型模型的行为。这种方法避免了对每个大型模型单独进行微调的需要,大大降低了训练成本。此外,PM-MinED token映射策略使得小型模型能够应用于具有不同词汇表的大模型,进一步提高了方法的通用性。
关键设计:PM-MinED token映射策略的关键在于最小化编辑距离。具体来说,对于目标模型中不存在的token,该策略会将其映射到模板模型中与其编辑距离最小的token上。损失函数的设计目标是使小型模型学习到的logit偏移能够有效地改善大模型的性能,例如,在指令调优任务中,损失函数会鼓励大模型生成更符合指令要求的输出。
🖼️ 关键图片


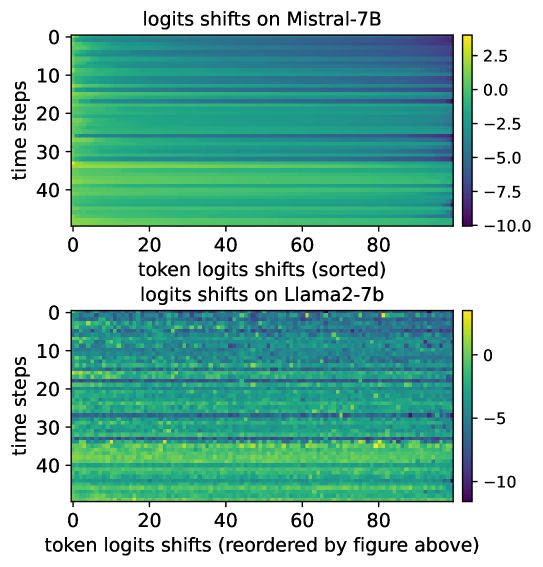
📊 实验亮点
实验结果表明,CMC方法在指令调优和反学习任务上均取得了显著的性能提升。例如,在指令调优任务中,CMC方法能够使多个大语言模型在遵循指令方面的能力得到显著提高,且性能接近甚至超过了对每个模型单独进行微调的结果。在反学习任务中,CMC方法能够有效地使模型忘记特定的知识,避免输出敏感信息。
🎯 应用场景
该研究成果可广泛应用于大语言模型的指令调优、安全对齐、知识编辑等领域。通过一次训练,即可提升多个不同架构、不同参数规模的大语言模型在特定任务上的性能,降低了模型定制和维护的成本。未来,该方法有望推广到更多类型的模型和任务中,加速大语言模型的应用落地。
📄 摘要(原文)
The number of large language models (LLMs) with varying parameter scales and vocabularies is increasing. While they deliver powerful performance, they also face a set of common optimization needs to meet specific requirements or standards, such as instruction following or avoiding the output of sensitive information from the real world. However, how to reuse the fine-tuning outcomes of one model to other models to reduce training costs remains a challenge. To bridge this gap, we introduce Cross-model Control (CMC), a method that improves multiple LLMs in one-time training with a portable tiny language model. Specifically, we have observed that the logit shift before and after fine-tuning is remarkably similar across different models. Based on this insight, we incorporate a tiny language model with a minimal number of parameters. By training alongside a frozen template LLM, the tiny model gains the capability to alter the logits output by the LLMs. To make this tiny language model applicable to models with different vocabularies, we propose a novel token mapping strategy named PM-MinED. We have conducted extensive experiments on instruction tuning and unlearning tasks, demonstrating the effectiveness of CMC. Our code is available at https://github.com/wujwyi/CMC.