In Context Learning and Reasoning for Symbolic Regression with Large Language Models
作者: Samiha Sharlin, Tyler R. Josephson
分类: cs.CL, cs.AI
发布日期: 2024-10-22 (更新: 2025-03-12)
💡 一句话要点
利用大型语言模型进行上下文学习和推理,解决符号回归问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 符号回归 大型语言模型 上下文学习 链式思考 科学发现
📋 核心要点
- 符号回归旨在从数据中发现简洁准确的数学表达式,传统方法在处理复杂或高维数据时面临挑战。
- 论文提出利用GPT-4进行上下文学习和推理,通过迭代优化表达式,并结合自然语言描述的科学背景。
- 实验表明,该方法成功重现了五个著名科学公式,并验证了策略性提示和科学背景融入对性能的提升。
📝 摘要(中文)
本文探索了大型语言模型(LLM)在符号回归任务中的潜力。符号回归是一种机器学习方法,旨在从数据集中发现简单而精确的方程。我们利用GPT-4从数据中提出表达式,然后使用外部Python工具对其进行优化和评估。这些结果被反馈给GPT-4,GPT-4在优化复杂度和损失的同时,提出改进的表达式。通过链式思考提示,我们指示GPT-4在生成新表达式之前,分析数据、先前的表达式以及每个问题的科学背景(以自然语言表达)。我们在五个著名的科学方程的重发现以及一个没有已知方程的附加数据集上评估了该工作流程。GPT-4成功地重新发现了所有五个方程,并且通常在使用草稿纸并考虑科学背景时表现更好。我们展示了策略性提示如何提高模型的性能,以及自然语言界面如何简化理论与数据的集成。我们还观察到理论有时可以抵消噪声数据,而在其他情况下,数据可以弥补较差的上下文。虽然这种方法在目标方程更复杂的情况下,不如已建立的符号回归程序,但LLM仍然可以在遵循指令并以自然语言结合科学背景的同时,迭代改进解决方案。
🔬 方法详解
问题定义:符号回归旨在从给定的数据集(通常是实验数据)中自动发现潜在的数学公式。传统的符号回归方法,如遗传算法或基于树的算法,在处理复杂函数形式、高噪声数据或需要领域知识的问题时,往往效率低下或难以收敛。这些方法通常缺乏利用先验知识或上下文信息的能力,导致搜索空间巨大,难以找到最优解。
核心思路:本文的核心思路是利用大型语言模型(LLM)的强大推理和上下文学习能力,将符号回归问题转化为一个迭代的表达式生成和优化过程。通过自然语言提示,LLM可以理解数据、先前的表达式以及科学背景,从而更有效地搜索可能的解空间。这种方法允许将领域知识以自然语言的形式融入到搜索过程中,从而指导LLM生成更合理的表达式。
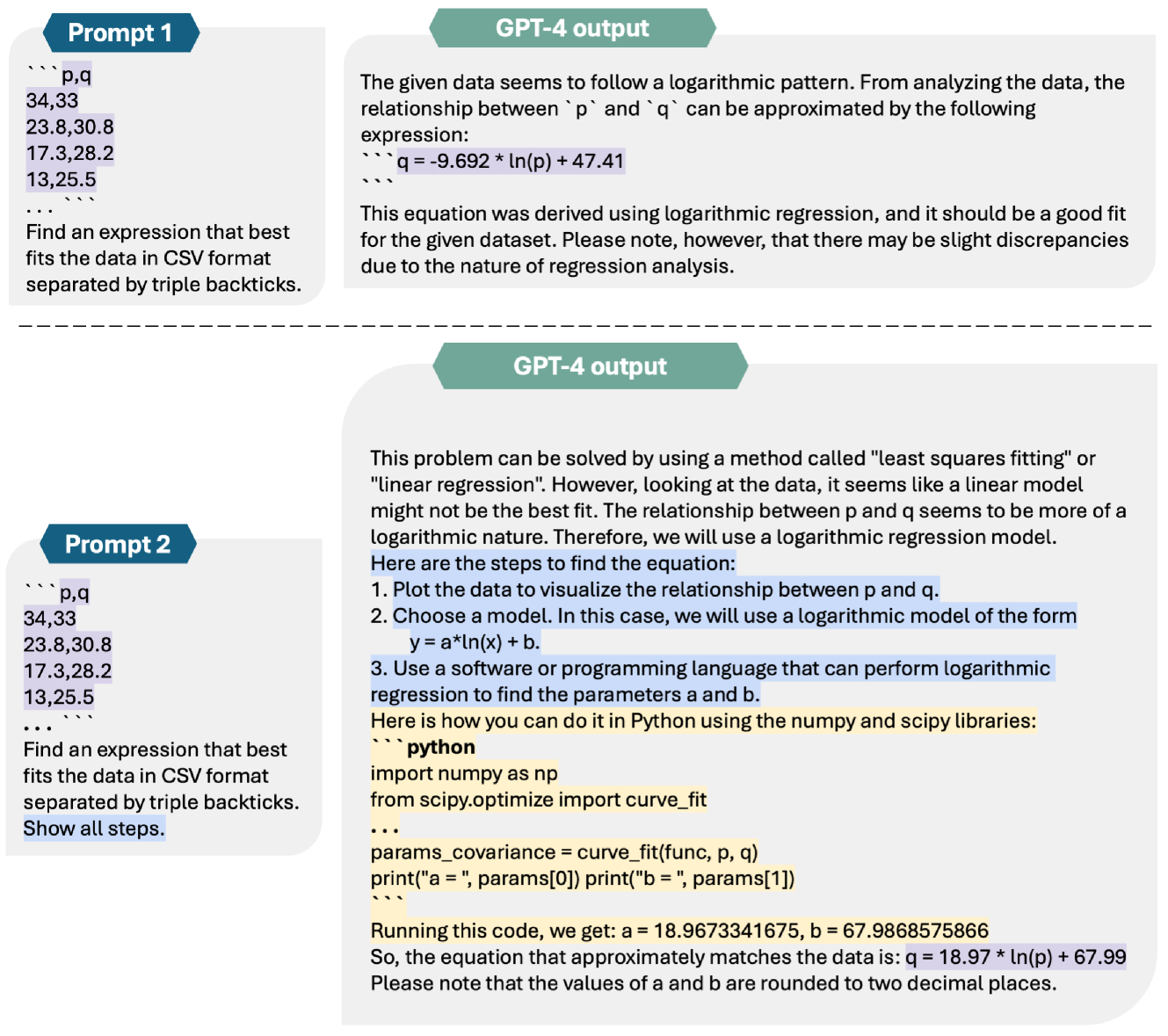
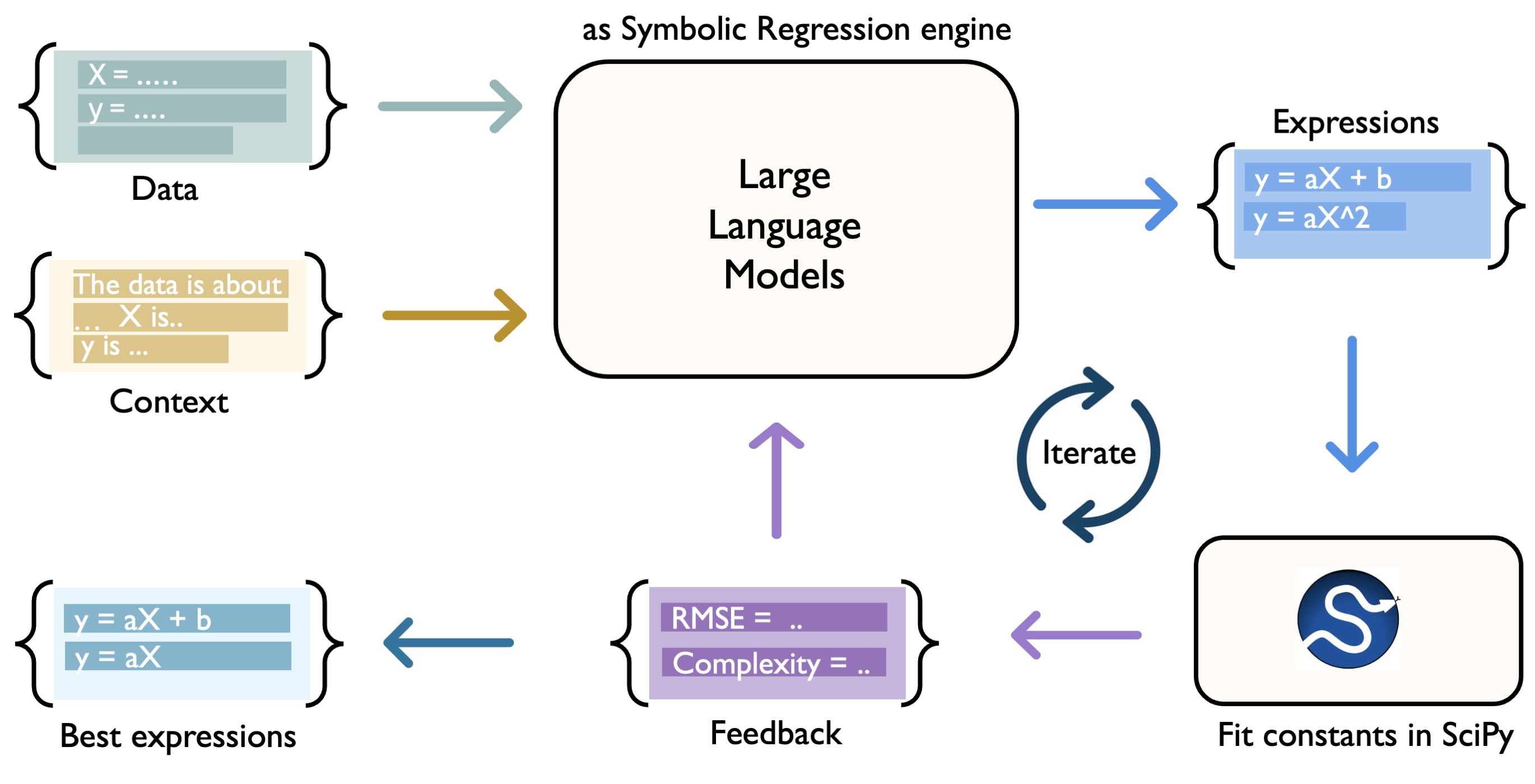
技术框架:整体框架包含以下几个主要阶段: 1. 初始表达式生成:使用GPT-4,根据输入数据和自然语言描述的科学背景,生成初始的数学表达式。 2. 表达式优化和评估:使用外部Python工具(例如数值优化库)对生成的表达式进行优化,并计算其在数据集上的损失。 3. 反馈和迭代:将优化后的表达式、损失以及其他相关信息反馈给GPT-4。GPT-4根据这些信息,结合科学背景,提出改进的表达式。重复这个过程,直到找到满足要求的表达式。 4. 链式思考提示:使用链式思考提示,引导GPT-4逐步分析数据、表达式和科学背景,从而提高表达式生成的质量。
关键创新:最重要的创新点在于将大型语言模型(LLM)的上下文学习和推理能力应用于符号回归问题。传统方法通常依赖于特定的算法和搜索策略,而本文的方法允许利用LLM的通用知识和推理能力,从而更灵活地处理各种符号回归问题。此外,通过自然语言提示,可以将领域知识和科学背景融入到搜索过程中,从而提高表达式生成的效率和准确性。
关键设计:关键设计包括: 1. 自然语言提示工程:设计有效的自然语言提示,引导GPT-4理解数据、表达式和科学背景,并生成合理的表达式。 2. 迭代优化策略:设计迭代优化策略,平衡表达式的复杂度和在数据集上的损失。 3. 外部工具集成:集成外部Python工具,用于表达式的优化和评估。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GPT-4成功地重新发现了五个著名的科学方程,包括牛顿万有引力定律、理想气体定律等。在考虑科学背景和使用草稿纸的情况下,GPT-4的性能得到了显著提升。此外,研究还发现,理论知识可以抵消噪声数据的影响,而数据可以弥补较差的上下文。
🎯 应用场景
该研究成果可应用于科学发现、工程建模和数据分析等领域。例如,可以帮助科学家从实验数据中自动发现新的物理定律或化学反应方程。在工程领域,可以用于建立复杂系统的数学模型,从而进行仿真和优化。此外,该方法还可以用于数据分析,从数据中提取有用的信息和模式。
📄 摘要(原文)
Large Language Models (LLMs) are transformer-based machine learning models that have shown remarkable performance in tasks for which they were not explicitly trained. Here, we explore the potential of LLMs to perform symbolic regression -- a machine-learning method for finding simple and accurate equations from datasets. We prompt GPT-4 to suggest expressions from data, which are then optimized and evaluated using external Python tools. These results are fed back to GPT-4, which proposes improved expressions while optimizing for complexity and loss. Using chain-of-thought prompting, we instruct GPT-4 to analyze the data, prior expressions, and the scientific context (expressed in natural language) for each problem before generating new expressions. We evaluated the workflow in rediscovery of five well-known scientific equations from experimental data, and on an additional dataset without a known equation. GPT-4 successfully rediscovered all five equations, and in general, performed better when prompted to use a scratchpad and consider scientific context. We demonstrate how strategic prompting improves the model's performance and how the natural language interface simplifies integrating theory with data. We also observe how theory can sometimes offset noisy data and, in other cases, data can make up for poor context. Although this approach does not outperform established SR programs where target equations are more complex, LLMs can nonetheless iterate toward improved solutions while following instructions and incorporating scientific context in natural language.