Scalable Influence and Fact Tracing for Large Language Model Pretraining
作者: Tyler A. Chang, Dheeraj Rajagopal, Tolga Bolukbasi, Lucas Dixon, Ian Tenney
分类: cs.CL
发布日期: 2024-10-22 (更新: 2024-12-21)
💡 一句话要点
提出可扩展的影响力与事实追溯方法,用于大规模语言模型预训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 预训练 数据归因 影响力分析 事实追溯
📋 核心要点
- 现有训练数据归因方法难以应用于大规模LLM预训练,限制了模型透明度和数据管理。
- 通过优化梯度方法,结合优化器状态校正、Hessian近似和归一化编码,实现高效的大规模影响力样本检索。
- 实验表明,该方法在识别影响模型预测的样本方面表现最佳,尤其是在模型规模增大时,影响力与事实归因更加一致。
📝 摘要(中文)
训练数据归因(TDA)方法旨在将模型输出追溯到特定的训练样本。将这些方法应用于大型语言模型(LLM)的输出,可以显著提高模型的透明度和数据管理能力。然而,迄今为止,将这些方法应用于LLM预训练的完整规模一直具有挑战性。本文改进了现有的基于梯度的方法,使其能够有效地大规模工作,从而能够从超过1600亿token的预训练语料库中检索80亿参数语言模型的影响性样本,而无需进行子抽样或预过滤。我们的方法结合了几种技术,包括优化器状态校正、特定于任务的Hessian近似和归一化编码,我们发现这些技术对于大规模性能至关重要。在事实追溯任务的定量评估中,我们的方法在识别影响模型预测的样本方面表现最佳,但经典的、与模型无关的检索方法(如BM25)在查找明确包含相关事实的段落方面仍然表现更好。这些结果表明了事实归因和因果影响之间的不一致。随着模型大小和训练token的增加,我们发现影响力与事实归因更加一致。最后,我们检查了我们的方法识别为有影响力的不同类型的样本,发现虽然许多样本直接蕴含特定事实,但其他样本通过加强关系类型、常见实体和名称的先验来支持相同的输出。我们发布了我们的prompt集和模型输出,以及一个基于Web的可视化工具,用于探索80亿参数LLM在事实预测、常识推理、算术和开放式生成方面的影响性样本。
🔬 方法详解
问题定义:现有训练数据归因方法难以应用于大规模LLM预训练,主要痛点在于计算复杂度高,难以处理海量数据,导致无法有效追溯模型输出的根源,限制了模型透明度和可解释性。现有方法通常需要进行子抽样或预过滤,导致信息损失,影响归因的准确性。
核心思路:论文的核心思路是通过优化现有的基于梯度的方法,使其能够有效地处理大规模数据,从而实现对LLM预训练过程的完整追溯。通过结合多种技术,降低计算复杂度,提高归因的准确性,从而更好地理解模型行为。
技术框架:该方法主要包含以下几个阶段:1) 数据准备:准备大规模的预训练语料库。2) 模型训练:训练一个大型语言模型。3) 影响力计算:使用优化的梯度方法计算每个训练样本对模型输出的影响力。4) 结果分析:分析有影响力的样本,理解其对模型行为的影响。该框架无需子抽样或预过滤,能够处理完整的预训练数据集。
关键创新:最重要的技术创新点在于对现有梯度方法的优化,使其能够有效地处理大规模数据。具体包括:1) 优化器状态校正:校正优化器状态,提高梯度计算的准确性。2) 任务特定的Hessian近似:使用任务特定的Hessian近似,降低计算复杂度。3) 归一化编码:使用归一化编码,提高模型的泛化能力。这些技术使得该方法能够在不损失准确性的前提下,处理大规模数据。
关键设计:在优化器状态校正方面,论文可能采用了动量校正或自适应学习率调整等技术。在Hessian近似方面,可能使用了Fisher信息矩阵或K-FAC等方法。归一化编码可能采用了Layer Normalization或Weight Normalization等技术。具体的参数设置和损失函数选择可能需要根据具体的任务和数据集进行调整。
🖼️ 关键图片
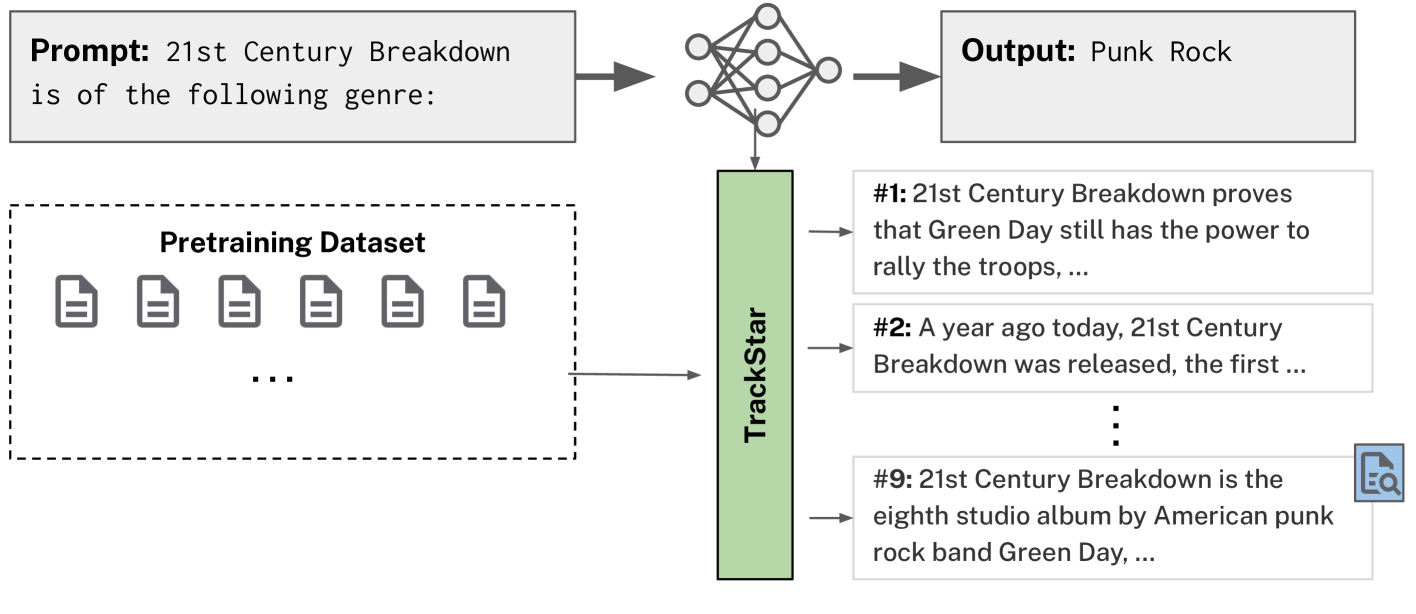


📊 实验亮点
实验结果表明,该方法在事实追溯任务中表现最佳,能够有效识别影响模型预测的样本。与传统的BM25等检索方法相比,该方法在识别因果影响方面更具优势。随着模型规模和训练token的增加,影响力与事实归因更加一致,表明该方法具有良好的可扩展性。
🎯 应用场景
该研究成果可应用于提升大型语言模型的透明度和可解释性,帮助理解模型行为,改进数据管理策略。通过追溯模型输出的根源,可以识别并纠正训练数据中的偏差和错误,提高模型的可靠性和安全性。此外,该方法还可以用于评估不同训练数据对模型性能的影响,从而优化训练过程。
📄 摘要(原文)
Training data attribution (TDA) methods aim to attribute model outputs back to specific training examples, and the application of these methods to large language model (LLM) outputs could significantly advance model transparency and data curation. However, it has been challenging to date to apply these methods to the full scale of LLM pretraining. In this paper, we refine existing gradient-based methods to work effectively at scale, allowing us to retrieve influential examples for an 8B-parameter language model from a pretraining corpus of over 160B tokens with no need for subsampling or pre-filtering. Our method combines several techniques, including optimizer state correction, a task-specific Hessian approximation, and normalized encodings, which we find to be critical for performance at scale. In quantitative evaluations on a fact tracing task, our method performs best at identifying examples that influence model predictions, but classical, model-agnostic retrieval methods such as BM25 still perform better at finding passages which explicitly contain relevant facts. These results demonstrate a misalignment between factual attribution and causal influence. With increasing model size and training tokens, we find that influence more closely aligns with factual attribution. Finally, we examine different types of examples identified as influential by our method, finding that while many directly entail a particular fact, others support the same output by reinforcing priors on relation types, common entities, and names. We release our prompt set and model outputs, along with a web-based visualization tool to explore influential examples for factual predictions, commonsense reasoning, arithmetic, and open-ended generation for an 8B-parameter LLM.