Enhancing Answer Attribution for Faithful Text Generation with Large Language Models
作者: Juraj Vladika, Luca Mülln, Florian Matthes
分类: cs.CL, cs.IR
发布日期: 2024-10-22
备注: Accepted to KDIR 2024 (part of IC3K 2024)
💡 一句话要点
提出改进的答案归因方法,提升大型语言模型生成文本的可信度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 答案归因 大型语言模型 文本生成 证据检索 可信度 自然语言处理 知识库 问答系统
📋 核心要点
- 现有答案归因方法在答案分割和证据检索方面存在不足,难以准确追溯LLM生成文本的来源。
- 论文提出新的方法,旨在生成更独立和上下文相关的声明,从而改善检索和归因效果。
- 实验结果表明,新方法能够有效提升答案归因组件的性能,增强LLM生成文本的可信度。
📝 摘要(中文)
近年来,大型语言模型(LLMs)日益普及,改变了用户与基于人工智能的对话系统交互和提问的方式。提高LLM生成答案可信度的一个重要方面是能够将回复中的各个声明追溯到支持它们的来源,这个过程被称为答案归因。虽然最近的工作已经开始探索LLM中的答案归因任务,但仍然存在一些挑战。在这项工作中,我们首先进行案例研究,分析现有答案归因方法的有效性,重点关注答案分割和证据检索的子任务。基于观察到的缺点,我们提出了新的方法,以产生更独立和上下文相关的声明,从而实现更好的检索和归因。对新方法进行了评估,结果表明提高了答案归因组件的性能。最后,我们对该任务进行了讨论并概述了未来的方向。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)生成文本时,答案归因不准确的问题。现有方法在答案分割和证据检索这两个关键子任务上表现不足,导致无法有效追溯LLM生成文本中各个claim的来源,降低了生成文本的可信度。现有方法难以生成独立且上下文相关的声明,影响了后续的检索和归因效果。
核心思路:论文的核心思路是通过改进答案分割和证据检索的方法,生成更独立且上下文相关的声明,从而提升答案归因的准确性。通过更清晰的分割,每个claim能够更准确地对应到支持它的证据。通过增强claim的上下文信息,可以提高证据检索的效率和准确性。
技术框架:论文首先对现有答案归因方法进行案例研究,分析其在答案分割和证据检索方面的不足。然后,基于分析结果,提出新的答案分割和证据检索方法。具体的技术框架细节未知,但可以推断其包含以下模块:1. 答案分割模块:负责将LLM生成的答案分割成独立的claim。2. 证据检索模块:负责根据分割后的claim,从外部知识库中检索相关的证据。3. 归因模块:负责将claim与其对应的证据进行关联。
关键创新:论文的关键创新在于提出了新的答案分割和证据检索方法,旨在生成更独立且上下文相关的声明。与现有方法相比,新方法可能采用了更先进的自然语言处理技术,例如更精细的语义分析、更有效的上下文建模等,从而提高了答案分割和证据检索的准确性。具体的技术细节未知。
关键设计:由于论文细节未知,无法提供关键设计细节。但可以推测,关键设计可能包括:1. 新的答案分割算法,例如基于语义角色标注或依存句法分析的分割方法。2. 新的证据检索模型,例如基于Transformer的跨模态检索模型。3. 损失函数的设计,例如采用对比学习或三元组损失来优化证据检索模型。
🖼️ 关键图片
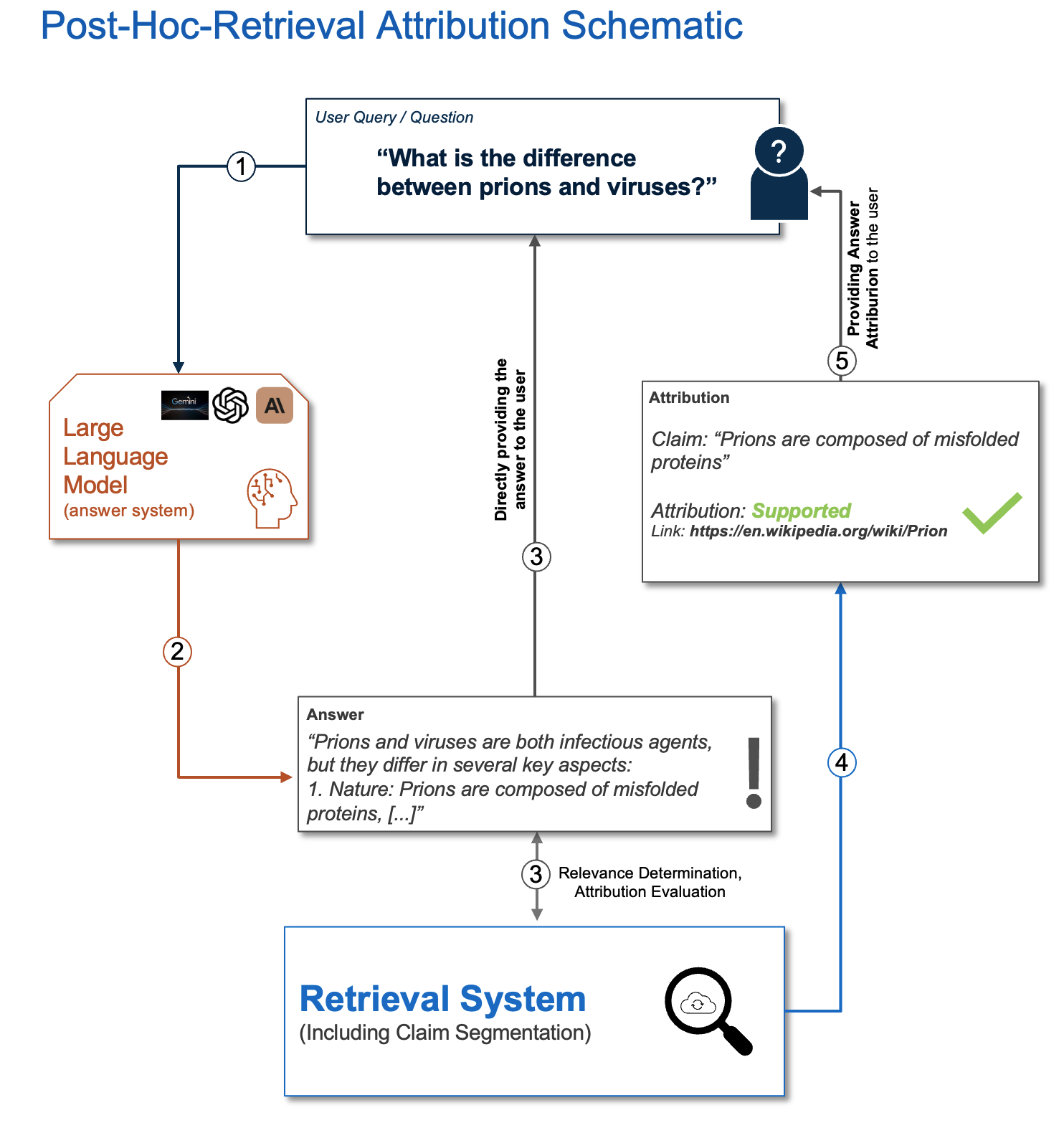


📊 实验亮点
论文通过实验验证了新方法的有效性,结果表明,新方法能够显著提高答案归因组件的性能。具体的性能数据、对比基线和提升幅度未知,但摘要中明确指出新方法在答案归因方面取得了改进。未来的研究可以进一步探索新方法在不同数据集和不同LLM上的泛化能力。
🎯 应用场景
该研究成果可应用于各种基于大型语言模型的问答系统、对话系统和文本生成系统,提高生成文本的可信度和透明度。通过准确的答案归因,用户可以验证LLM生成文本的真实性,从而增强对AI系统的信任。该技术还有助于减少LLM生成虚假信息或错误信息的风险,促进AI技术的健康发展。
📄 摘要(原文)
The increasing popularity of Large Language Models (LLMs) in recent years has changed the way users interact with and pose questions to AI-based conversational systems. An essential aspect for increasing the trustworthiness of generated LLM answers is the ability to trace the individual claims from responses back to relevant sources that support them, the process known as answer attribution. While recent work has started exploring the task of answer attribution in LLMs, some challenges still remain. In this work, we first perform a case study analyzing the effectiveness of existing answer attribution methods, with a focus on subtasks of answer segmentation and evidence retrieval. Based on the observed shortcomings, we propose new methods for producing more independent and contextualized claims for better retrieval and attribution. The new methods are evaluated and shown to improve the performance of answer attribution components. We end with a discussion and outline of future directions for the task.