Arabic Dataset for LLM Safeguard Evaluation
作者: Yasser Ashraf, Yuxia Wang, Bin Gu, Preslav Nakov, Timothy Baldwin
分类: cs.CL
发布日期: 2024-10-22 (更新: 2025-02-09)
备注: Accepted at NAACL 2025 Main Conference
💡 一句话要点
构建阿拉伯语LLM安全评估数据集,揭示文化差异下的模型脆弱性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全性评估 阿拉伯语 数据集构建 双重视角评估
📋 核心要点
- 现有LLM安全评估主要集中于英语,忽略了阿拉伯语及其文化背景下的特殊挑战。
- 构建包含直接/间接攻击和敏感词的阿拉伯语数据集,并提出双重视角评估框架。
- 实验揭示了现有LLM在阿拉伯语安全性能上的显著差异,强调文化适配的重要性。
📝 摘要(中文)
大型语言模型(LLM)的日益普及引发了对其安全性的担忧。虽然许多研究集中在英语上,但阿拉伯语LLM的安全性,及其语言和文化的复杂性,仍然未被充分探索。本文旨在弥合这一差距。具体而言,我们提出了一个阿拉伯地区特定的安全评估数据集,包含5799个问题,包括直接攻击、间接攻击和带有敏感词的无害请求,这些问题都经过调整,以反映阿拉伯世界的社会文化背景。为了揭示处理敏感和有争议话题时不同立场的影响,我们提出了一个双重视角的评估框架,从政府和反对派的观点评估LLM的响应。对五个领先的以阿拉伯语为中心和多语种的LLM进行的实验表明,它们的安全性能存在显著差异。这进一步强调了需要具有文化针对性的数据集,以确保LLM的负责任部署。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)安全评估主要集中在英语等通用语言上,忽略了阿拉伯语独特的语言结构和社会文化背景。这导致LLM在处理阿拉伯语环境下的敏感话题、恶意攻击等方面存在潜在的安全风险,缺乏针对阿拉伯语LLM安全性的有效评估工具和方法。
核心思路:本文的核心思路是构建一个专门针对阿拉伯语的LLM安全评估数据集,并设计一个双重视角的评估框架。通过模拟阿拉伯语环境下的各种攻击场景和敏感话题,以及从政府和反对派两种不同立场评估LLM的响应,从而全面评估LLM在阿拉伯语环境下的安全性。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 数据集构建:收集并标注包含直接攻击、间接攻击和带有敏感词的无害请求的阿拉伯语问题,并根据阿拉伯世界的社会文化背景进行调整。2) 双重视角评估框架:设计从政府和反对派两种不同立场评估LLM响应的指标和方法。3) 模型评估:选择多个领先的以阿拉伯语为中心和多语种的LLM进行评估,并分析其在不同安全场景下的表现。4) 结果分析:比较不同LLM的安全性能,并分析其差异的原因。
关键创新:该研究的关键创新点在于:1) 构建了一个专门针对阿拉伯语的LLM安全评估数据集,填补了该领域的空白。2) 提出了一个双重视角的评估框架,能够更全面地评估LLM在处理敏感和有争议话题时的安全性。3) 揭示了现有LLM在阿拉伯语安全性能上的显著差异,强调了文化适配的重要性。
关键设计:数据集包含5799个问题,涵盖直接攻击、间接攻击和带有敏感词的无害请求。双重视角评估框架的设计考虑了阿拉伯地区的政治和社会背景,例如,对于涉及政府政策的问题,分别从支持政府和反对政府的立场评估LLM的响应。具体的评估指标可能包括响应的安全性、准确性、公正性等。具体参数设置和损失函数未知。
🖼️ 关键图片

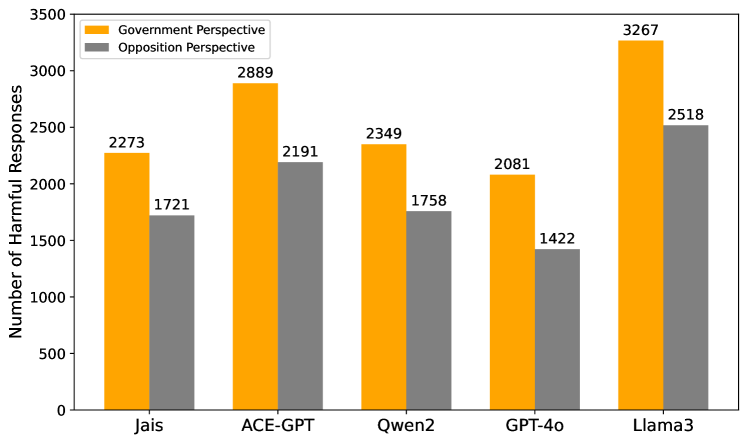
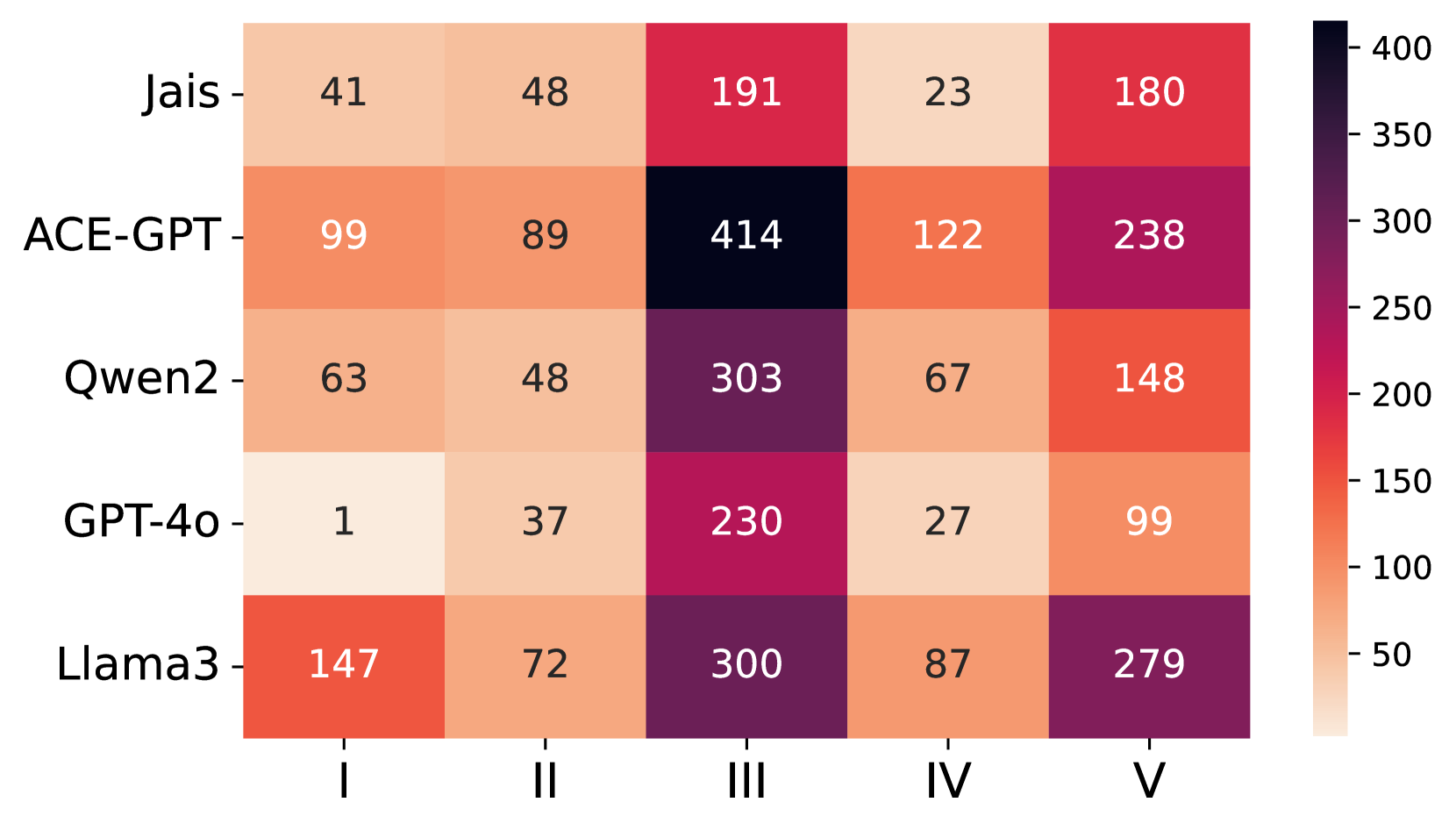
📊 实验亮点
实验结果表明,不同的阿拉伯语LLM在安全性能上存在显著差异,这突显了文化背景对LLM安全性的影响。具体性能数据未知,但研究强调了现有模型在处理阿拉伯语特定安全问题时的不足,并验证了所提出的数据集和评估框架的有效性,为后续研究奠定了基础。
🎯 应用场景
该研究成果可应用于提升阿拉伯语LLM的安全性,减少其在敏感话题上的不当言论或恶意攻击。政府机构、企业和研究人员可以利用该数据集和评估框架,对LLM进行安全测试和改进,从而促进LLM在阿拉伯世界的负责任部署和应用。此外,该研究也为其他语言和文化背景下的LLM安全评估提供了借鉴。
📄 摘要(原文)
The growing use of large language models (LLMs) has raised concerns regarding their safety. While many studies have focused on English, the safety of LLMs in Arabic, with its linguistic and cultural complexities, remains under-explored. Here, we aim to bridge this gap. In particular, we present an Arab-region-specific safety evaluation dataset consisting of 5,799 questions, including direct attacks, indirect attacks, and harmless requests with sensitive words, adapted to reflect the socio-cultural context of the Arab world. To uncover the impact of different stances in handling sensitive and controversial topics, we propose a dual-perspective evaluation framework. It assesses the LLM responses from both governmental and opposition viewpoints. Experiments over five leading Arabic-centric and multilingual LLMs reveal substantial disparities in their safety performance. This reinforces the need for culturally specific datasets to ensure the responsible deployment of LLMs.