ETHIC: Evaluating Large Language Models on Long-Context Tasks with High Information Coverage
作者: Taewhoo Lee, Chanwoong Yoon, Kyochul Jang, Donghyeon Lee, Minju Song, Hyunjae Kim, Jaewoo Kang
分类: cs.CL
发布日期: 2024-10-22 (更新: 2025-02-27)
备注: NAACL 2025
🔗 代码/项目: GITHUB
💡 一句话要点
ETHIC:提出高信息覆盖率的长文本评估基准,揭示LLM在长上下文利用上的不足。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本理解 大型语言模型 评估基准 信息覆盖率 上下文学习
📋 核心要点
- 现有长文本LLM评估方法(如大海捞针)的信息覆盖率低,无法有效评估模型对上下文的充分利用。
- 提出ETHIC基准,通过高信息覆盖率的测试实例,更全面地评估LLM对长上下文的利用能力。
- 实验表明,现有LLM在ETHIC基准上性能显著下降,揭示了长上下文管理方面的挑战。
📝 摘要(中文)
随着大型语言模型(LLM)处理超长文本能力的发展,亟需一个专门的评估基准来评估其长上下文能力。然而,现有的方法,如大海捞针测试,并不能有效地评估这些模型是否充分利用了上下文信息,这引发了对当前评估技术可靠性的担忧。为了彻底检查现有基准的有效性,我们引入了一种名为信息覆盖率(IC)的新指标,该指标量化了回答查询所需的输入上下文的比例。我们的研究结果表明,当前的基准表现出较低的IC;虽然输入上下文可能很广泛,但实际可用的上下文通常是有限的。为了解决这个问题,我们提出了ETHIC,这是一个旨在评估LLM利用整个上下文能力的新的基准。我们的基准包括1,986个测试实例,涵盖书籍、辩论、医学和法律四个领域,具有较高的IC分数。我们的评估揭示了当代LLM的显著性能下降,突出了管理长上下文的关键挑战。我们的基准可在https://github.com/dmis-lab/ETHIC上找到。
🔬 方法详解
问题定义:论文旨在解决现有长文本LLM评估基准信息覆盖率低的问题。现有方法,例如“大海捞针”测试,虽然可以评估模型是否能找到特定信息,但无法衡量模型对整个上下文的利用程度。这种低信息覆盖率使得评估结果的可靠性受到质疑,无法真实反映模型在实际应用中的长文本处理能力。
核心思路:论文的核心思路是设计一个高信息覆盖率的评估基准,即ETHIC。该基准中的每个测试实例都需要模型利用大部分或全部的上下文信息才能正确回答问题。通过这种方式,可以更准确地评估模型是否真正理解并利用了长文本中的信息,而不仅仅是检索特定片段。
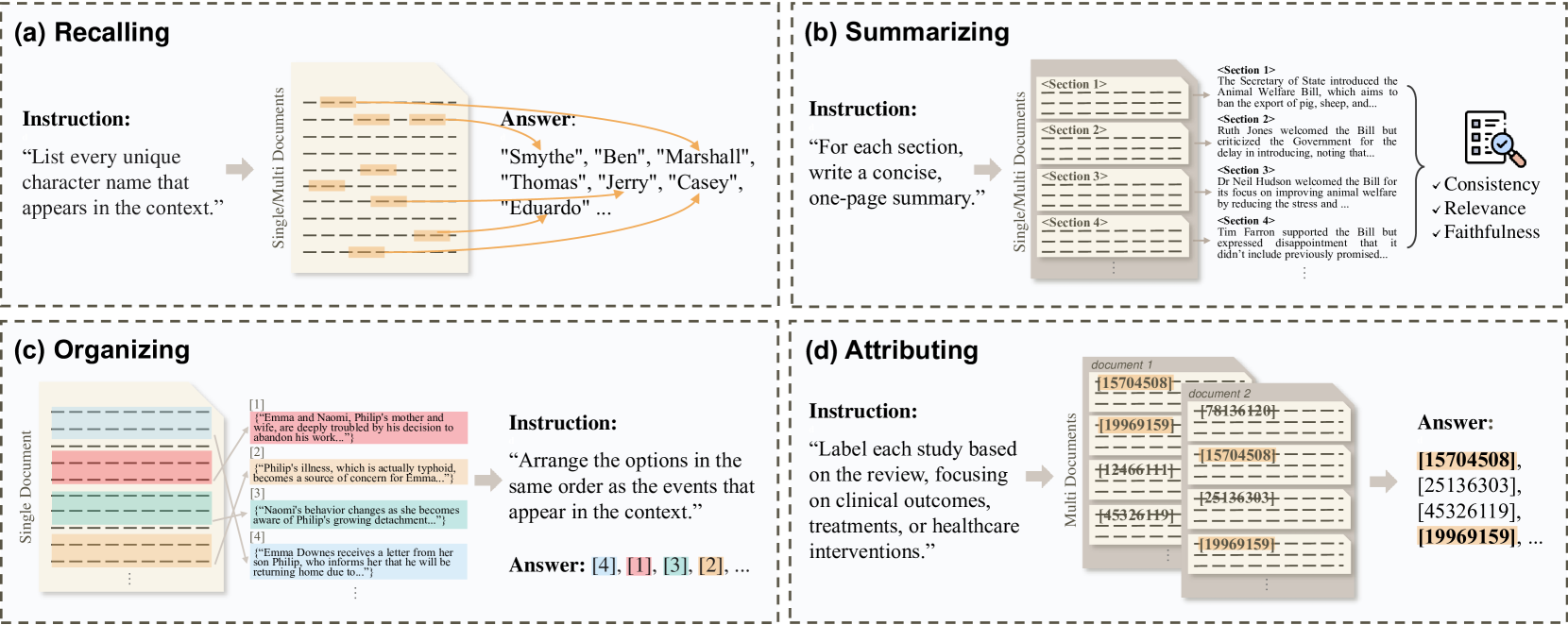
技术框架:ETHIC基准包含1986个测试实例,涵盖书籍、辩论、医学和法律四个领域。每个领域都设计了需要利用长上下文信息才能回答的问题。整体流程是:1)构建包含长文本的测试实例;2)设计需要利用上下文信息才能回答的问题;3)使用LLM进行推理;4)评估模型回答的准确性。
关键创新:ETHIC基准的关键创新在于其高信息覆盖率(IC)的设计。与现有基准相比,ETHIC要求模型必须理解并利用大部分上下文信息才能正确回答问题,从而更全面地评估模型对长文本的理解和推理能力。此外,ETHIC涵盖了多个领域,增加了评估的全面性和泛化性。
关键设计:ETHIC的关键设计在于测试实例的构建。每个实例都包含一个长文本和一个问题,问题需要模型综合利用文本中的多个信息点才能回答。为了保证高信息覆盖率,问题设计时会尽量覆盖文本中的关键信息,并避免可以通过简单检索就能回答的问题。具体参数设置和损失函数未知,因为论文主要关注基准的构建和评估,而非模型的训练。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有的LLM在ETHIC基准上的性能显著下降,这表明这些模型在处理高信息覆盖率的长文本时存在挑战。具体性能数据未知,但论文强调了性能下降的普遍性,突出了现有模型在长上下文管理方面的不足。ETHIC基准的提出为未来LLM的改进提供了重要的评估工具。
🎯 应用场景
该研究成果可应用于评估和改进各种需要处理长文本的LLM应用,例如:长篇文档摘要、法律文本分析、医学报告解读、以及需要深入理解上下文的对话系统。ETHIC基准的提出有助于推动LLM在长文本处理方面的研究和发展,提升LLM在实际应用中的性能和可靠性。
📄 摘要(原文)
Recent advancements in large language models (LLM) capable of processing extremely long texts highlight the need for a dedicated evaluation benchmark to assess their long-context capabilities. However, existing methods, like the needle-in-a-haystack test, do not effectively assess whether these models fully utilize contextual information, raising concerns about the reliability of current evaluation techniques. To thoroughly examine the effectiveness of existing benchmarks, we introduce a new metric called information coverage (IC), which quantifies the proportion of the input context necessary for answering queries. Our findings indicate that current benchmarks exhibit low IC; although the input context may be extensive, the actual usable context is often limited. To address this, we present ETHIC, a novel benchmark designed to assess LLMs' ability to leverage the entire context. Our benchmark comprises 1,986 test instances spanning four long-context tasks with high IC scores in the domains of books, debates, medicine, and law. Our evaluations reveal significant performance drops in contemporary LLMs, highlighting a critical challenge in managing long contexts. Our benchmark is available at https://github.com/dmis-lab/ETHIC.