RULEBREAKERS: Challenging LLMs at the Crossroads between Formal Logic and Human-like Reasoning
作者: Jason Chan, Robert Gaizauskas, Zhixue Zhao
分类: cs.CL
发布日期: 2024-10-21 (更新: 2025-08-15)
备注: Accepted by ICML 2025
💡 一句话要点
提出RULEBREAKERS数据集,揭示LLM在形式逻辑与类人推理的交叉点上的局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 形式逻辑 常识推理 数据集 类人推理
📋 核心要点
- 现有方法依赖形式逻辑进行推理,但在常识和事实知识下,可能得出与人类直觉相悖的结论。
- 论文创建RULEBREAKERS数据集,用于评估LLM在形式逻辑和类人推理交叉点上的表现,特别是识别和处理“规则破坏者”的能力。
- 实验表明,包括GPT-4o在内的大多数LLM在RULEBREAKERS上表现平庸,过度依赖形式逻辑,未能有效利用世界知识。
📝 摘要(中文)
形式逻辑通过将自然语言句子表示为符号形式并应用规则来推导结论,使计算机能够进行推理。然而,在我们的研究中,我们将其定义为“规则破坏者”场景,这种方法可能导致人类通常不会根据常识和事实知识推断或接受的结论。受到认知科学研究的启发,我们创建了RULEBREAKERS,这是第一个严格评估大型语言模型(LLM)以类人方式识别和响应规则破坏者(相对于非规则破坏者)的能力的数据集。对七个LLM的评估表明,包括GPT-4o在内的大多数模型在RULEBREAKERS上取得了平庸的准确性,并且表现出过度僵化地应用逻辑规则的倾向,这与典型的人类推理者的预期不同。进一步的分析表明,这种明显的失败可能与模型对世界知识的利用不足及其注意力分布模式有关。在揭示当前LLM的局限性的同时,我们的研究也为越来越多的近期研究提供了及时的平衡,这些研究提出了依赖形式逻辑来提高LLM的通用推理能力的方法,突出了它们进一步增加LLM与类人推理之间差异的风险。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在形式逻辑推理和类人常识推理之间存在的差异问题。现有方法过度依赖形式逻辑,导致在某些情况下,LLM会得出与人类直觉和常识相悖的结论,即“规则破坏者”场景。这种现象表明LLM在理解和应用常识知识方面存在不足,限制了其在实际应用中的可靠性。
核心思路:论文的核心思路是构建一个专门的数据集RULEBREAKERS,用于系统性地评估LLM在处理“规则破坏者”场景时的能力。通过分析LLM在识别和响应这些场景时的表现,揭示其在形式逻辑推理和类人推理之间的权衡,并探究其潜在的局限性。这种方法旨在促进对LLM推理机制的更深入理解,并为改进LLM的推理能力提供指导。
技术框架:论文主要围绕RULEBREAKERS数据集的构建和LLM的评估展开。数据集包含一系列“规则破坏者”和“非规则破坏者”场景,每个场景都包含一段文本描述和一个需要判断的结论。研究人员使用该数据集对七个LLM进行了评估,包括GPT-4o等先进模型。评估指标主要关注LLM在识别和响应“规则破坏者”场景时的准确性。此外,论文还分析了LLM的注意力分布模式,以探究其推理过程中的潜在问题。
关键创新:论文的关键创新在于提出了RULEBREAKERS数据集,这是首个专门用于评估LLM在形式逻辑和类人推理交叉点上的表现的数据集。与现有数据集相比,RULEBREAKERS更加关注LLM在处理“规则破坏者”场景时的能力,能够更有效地揭示LLM在推理方面的局限性。此外,论文还通过分析LLM的注意力分布模式,为理解其推理过程提供了新的视角。
关键设计:RULEBREAKERS数据集的设计关键在于场景的构建,需要确保场景既包含明确的逻辑规则,又包含可能与逻辑规则相悖的常识或事实知识。数据集的构建过程需要仔细考虑各种因素,例如场景的复杂性、常识知识的适用性以及结论的合理性。此外,论文还采用了多种评估指标,以全面评估LLM在识别和响应“规则破坏者”场景时的能力。注意力分布分析则采用了标准的可视化技术,以揭示LLM在推理过程中关注的关键信息。
🖼️ 关键图片


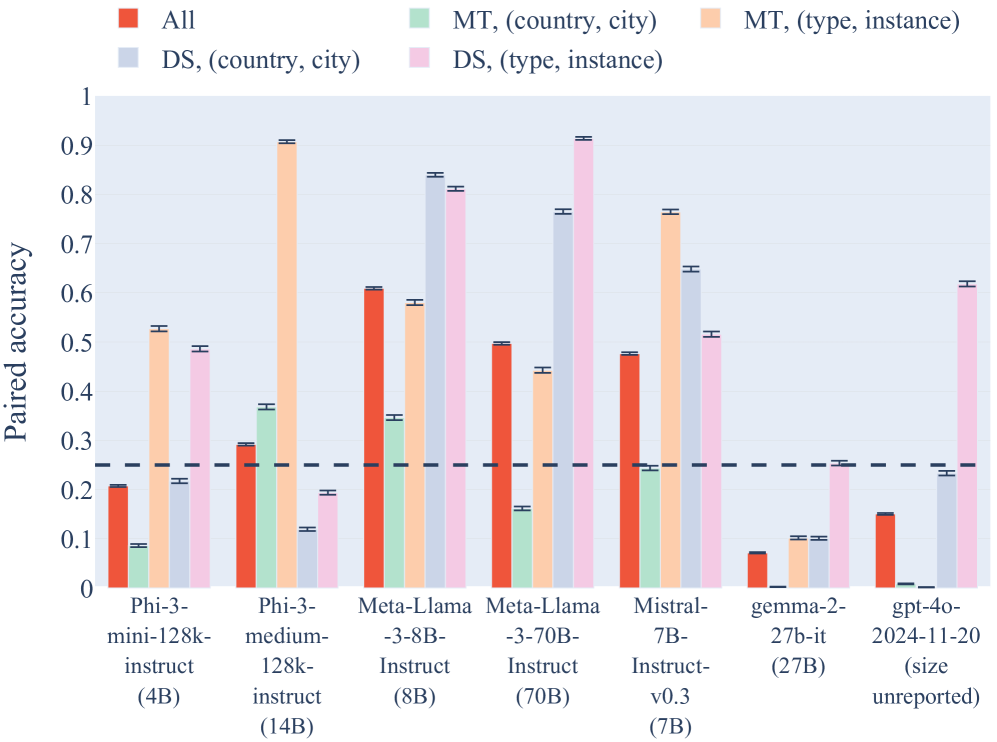
📊 实验亮点
实验结果表明,包括GPT-4o在内的大多数LLM在RULEBREAKERS数据集上的准确率表现平庸,表明它们在处理“规则破坏者”场景时存在困难。分析还发现,LLM倾向于过度依赖形式逻辑,未能有效利用世界知识。这些发现揭示了当前LLM在推理方面的局限性,并为未来的研究方向提供了重要的启示。
🎯 应用场景
该研究成果可应用于提升LLM在需要常识推理的场景下的表现,例如智能客服、医疗诊断、法律咨询等领域。通过更好地理解LLM在形式逻辑和类人推理之间的权衡,可以开发出更可靠、更符合人类直觉的AI系统。此外,该研究也为未来LLM的训练和评估提供了新的思路,有助于推动AI技术的进一步发展。
📄 摘要(原文)
Formal logic enables computers to reason in natural language by representing sentences in symbolic forms and applying rules to derive conclusions. However, in what our study characterizes as "rulebreaker" scenarios, this method can lead to conclusions that are typically not inferred or accepted by humans given their common sense and factual knowledge. Inspired by works in cognitive science, we create RULEBREAKERS, the first dataset for rigorously evaluating the ability of large language models (LLMs) to recognize and respond to rulebreakers (versus non-rulebreakers) in a human-like manner. Evaluating seven LLMs, we find that most models, including GPT-4o, achieve mediocre accuracy on RULEBREAKERS and exhibit some tendency to over-rigidly apply logical rules unlike what is expected from typical human reasoners. Further analysis suggests that this apparent failure is potentially associated with the models' poor utilization of their world knowledge and their attention distribution patterns. Whilst revealing a limitation of current LLMs, our study also provides a timely counterbalance to a growing body of recent works that propose methods relying on formal logic to improve LLMs' general reasoning capabilities, highlighting their risk of further increasing divergence between LLMs and human-like reasoning.