DocEdit-v2: Document Structure Editing Via Multimodal LLM Grounding
作者: Manan Suri, Puneet Mathur, Franck Dernoncourt, Rajiv Jain, Vlad I Morariu, Ramit Sawhney, Preslav Nakov, Dinesh Manocha
分类: cs.CL
发布日期: 2024-10-21
备注: EMNLP 2024 (Main)
💡 一句话要点
DocEdit-v2:提出一种基于多模态LLM的文档结构编辑框架,提升文档编辑性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文档结构编辑 多模态学习 大型语言模型 视觉定位 指令重构
📋 核心要点
- 文档结构编辑的关键挑战在于如何准确地将用户请求与文档图像中的特定结构组件及其属性关联。
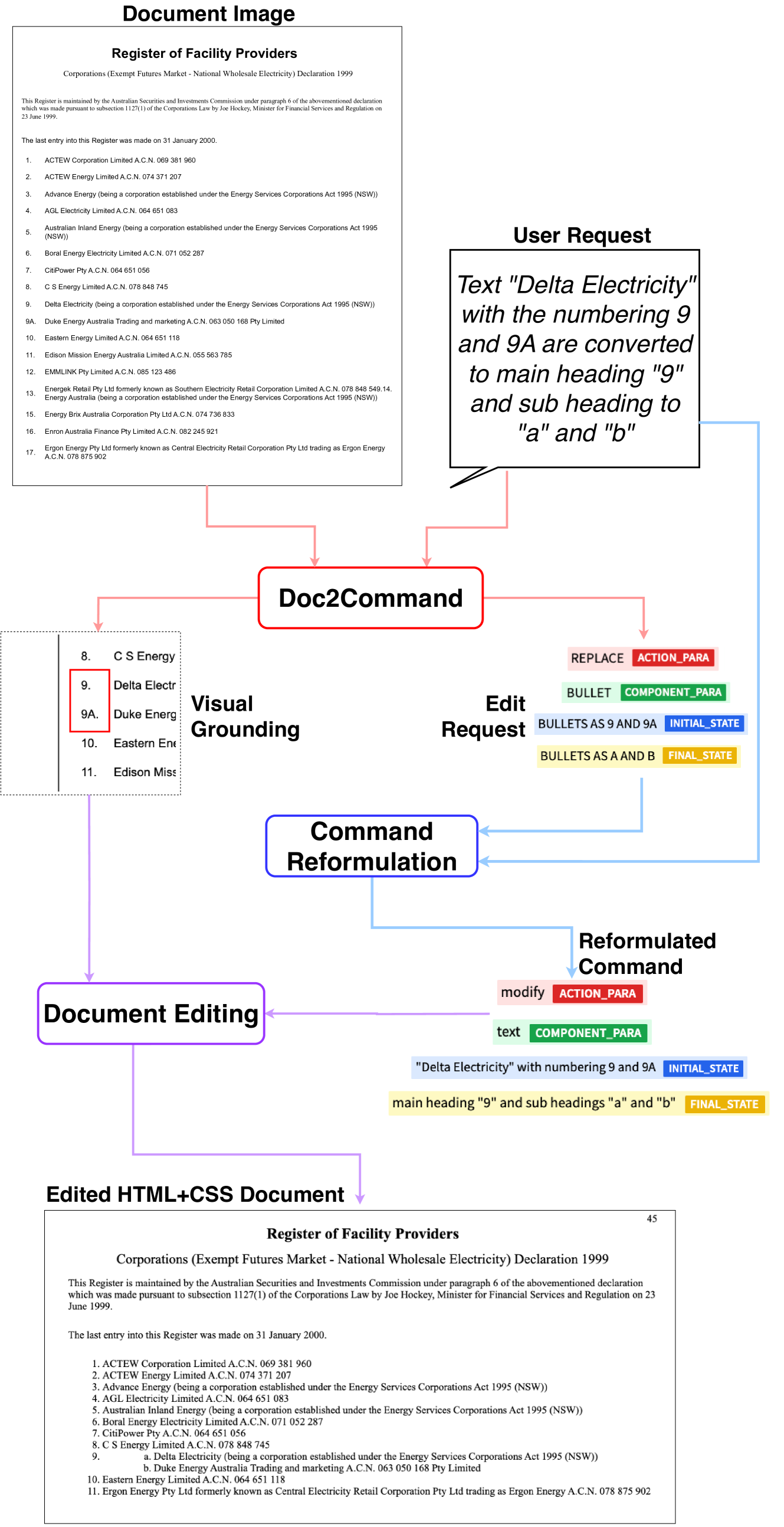
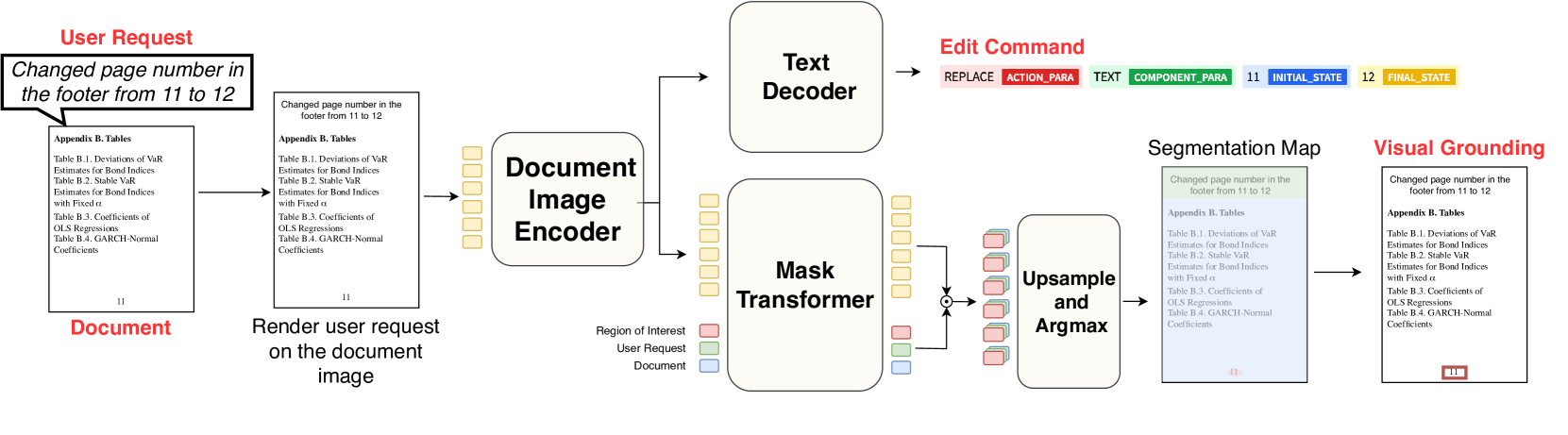
- DocEdit-v2通过Doc2Command模块定位编辑区域,并利用LLM重构编辑指令,使其适用于通用LMM。
- 实验结果表明,DocEdit-v2在编辑命令生成、RoI检测和整体文档编辑任务上均优于现有方法。
📝 摘要(中文)
本文提出DocEdit-v2,一个新颖的框架,利用大型多模态模型(LMMs)执行端到端的文档编辑。文档结构编辑涉及根据用户请求,操纵文档图像中局部化的文本、视觉和布局组件。过去的研究表明,用户请求在文档图像中的多模态定位,以及识别准确的结构组件及其相关属性,仍然是这项任务的关键挑战。DocEdit-v2包含三个新颖的组件:(1)Doc2Command,它同时定位感兴趣的编辑区域(RoI),并将用户编辑请求消歧为编辑命令;(2)基于LLM的命令重构提示,将最初为专用软件设计的编辑命令调整为适合通用LMM的编辑指令。(3)DocEdit-v2通过GPT-4V和Gemini等大型多模态模型处理这些输出,以解析文档布局,在已定位的感兴趣区域(RoI)上执行编辑,并生成编辑后的文档图像。在DocEdit数据集上的大量实验表明,DocEdit-v2在编辑命令生成(2-33%)、RoI边界框检测(12-31%)和整体文档编辑(1-12%)任务上显著优于强大的基线。
🔬 方法详解
问题定义:文档结构编辑旨在根据用户指令修改文档图像中的文本、视觉和布局元素。现有方法难以准确定位用户请求对应的文档区域,并将其转化为机器可执行的指令,尤其是在处理复杂文档结构和模糊指令时。现有方法在多模态信息融合和指令泛化能力方面存在不足。
核心思路:DocEdit-v2的核心思路是利用大型多模态模型(LMMs)的强大理解和生成能力,将用户请求转化为可执行的编辑命令,并在文档图像中定位相应的编辑区域。通过Doc2Command模块实现用户意图的精准解析和区域定位,并利用LLM进行命令重构,使其适应通用LMM的输入格式。
技术框架:DocEdit-v2框架包含三个主要模块:Doc2Command、LLM-based Command Reformulation和LMM Execution。Doc2Command模块负责将用户编辑请求转化为编辑命令,并定位感兴趣的编辑区域(RoI)。LLM-based Command Reformulation模块利用LLM将编辑命令调整为适合通用LMM的编辑指令。LMM Execution模块利用GPT-4V或Gemini等LMM解析文档布局,在RoI上执行编辑,并生成编辑后的文档图像。
关键创新:DocEdit-v2的关键创新在于Doc2Command模块和LLM-based Command Reformulation模块。Doc2Command模块能够同时进行编辑区域定位和用户意图消歧,提高了编辑的准确性。LLM-based Command Reformulation模块利用LLM的泛化能力,将特定软件的编辑命令转化为通用LMM可理解的指令,降低了对特定软件的依赖。
关键设计:Doc2Command模块的具体实现细节未知,但其核心功能是生成编辑命令和RoI。LLM-based Command Reformulation模块使用了特定的prompting策略,以指导LLM生成合适的编辑指令。LMM Execution模块利用LMM的视觉理解能力解析文档布局,并根据编辑指令修改RoI中的内容。具体的损失函数和网络结构等技术细节未知。
🖼️ 关键图片

📊 实验亮点
DocEdit-v2在DocEdit数据集上进行了广泛的实验,结果表明其在编辑命令生成、RoI边界框检测和整体文档编辑任务上均显著优于现有方法。具体而言,在编辑命令生成任务上提升了2-33%,在RoI边界框检测任务上提升了12-31%,在整体文档编辑任务上提升了1-12%。
🎯 应用场景
DocEdit-v2可应用于自动化文档处理、智能文档编辑、文档修复与增强等领域。例如,可以用于批量修改合同模板、自动生成报告、修复扫描文档中的错误等。该研究有助于提高文档处理效率,降低人工成本,并提升文档质量。
📄 摘要(原文)
Document structure editing involves manipulating localized textual, visual, and layout components in document images based on the user's requests. Past works have shown that multimodal grounding of user requests in the document image and identifying the accurate structural components and their associated attributes remain key challenges for this task. To address these, we introduce the DocEdit-v2, a novel framework that performs end-to-end document editing by leveraging Large Multimodal Models (LMMs). It consists of three novel components: (1) Doc2Command, which simultaneously localizes edit regions of interest (RoI) and disambiguates user edit requests into edit commands; (2) LLM-based Command Reformulation prompting to tailor edit commands originally intended for specialized software into edit instructions suitable for generalist LMMs. (3) Moreover, DocEdit-v2 processes these outputs via Large Multimodal Models like GPT-4V and Gemini, to parse the document layout, execute edits on grounded Region of Interest (RoI), and generate the edited document image. Extensive experiments on the DocEdit dataset show that DocEdit-v2 significantly outperforms strong baselines on edit command generation (2-33%), RoI bounding box detection (12-31%), and overall document editing (1-12\%) tasks.