RM-Bench: Benchmarking Reward Models of Language Models with Subtlety and Style
作者: Yantao Liu, Zijun Yao, Rui Min, Yixin Cao, Lei Hou, Juanzi Li
分类: cs.CL
发布日期: 2024-10-21
🔗 代码/项目: GITHUB
💡 一句话要点
提出RM-Bench,评估奖励模型对语言模型细微内容差异和风格偏差的敏感性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 奖励模型 语言模型对齐 强化学习 人类反馈 基准测试 风格偏差 内容差异
📋 核心要点
- 现有奖励模型基准难以评估模型对细微内容差异和风格变化的敏感性,导致与策略模型性能相关性低。
- RM-Bench通过评估奖励模型对细微内容差异的敏感性和对风格偏差的抵抗力,来更准确地评估奖励模型。
- 实验表明RM-Bench与策略模型性能高度相关,能有效评估奖励模型,并揭示现有模型在风格偏差方面表现不足。
📝 摘要(中文)
奖励模型在诸如基于人类反馈的强化学习(RLHF)和推理扩展定律等技术中至关重要,它们指导语言模型的对齐并选择最佳响应。然而,现有的奖励模型基准通常通过要求模型区分由不同能力模型生成的响应来评估模型。这种方法无法评估奖励模型对细微但关键的内容变化和风格变化的敏感性,导致与策略模型性能的相关性较低。为此,我们引入了RM-Bench,这是一个新颖的基准,旨在根据奖励模型对细微内容差异的敏感性和对风格偏差的抵抗力来评估它们。大量实验表明,RM-Bench与策略模型性能密切相关,使其成为选择奖励模型以有效对齐语言模型的可靠参考。我们在RM-Bench上评估了近40个奖励模型。我们的结果表明,即使是最先进的模型,在面对风格偏差干扰时,平均性能也仅为46.6%,低于随机水平的准确率(50%)。这些发现突出了当前奖励模型仍有很大的改进空间。
🔬 方法详解
问题定义:现有奖励模型评估方法主要通过区分不同能力模型生成的回复来评估奖励模型,无法有效评估奖励模型对细微内容差异和风格变化的敏感性。这导致奖励模型在实际应用中,与策略模型的性能相关性较低,无法有效指导语言模型的对齐。
核心思路:RM-Bench的核心思路是构建一个更具挑战性的评估基准,该基准能够测试奖励模型对细微内容差异的辨别能力,以及对风格偏差的鲁棒性。通过这种方式,可以更准确地评估奖励模型的质量,并选择更适合指导语言模型对齐的奖励模型。
技术框架:RM-Bench主要包含以下几个部分: 1. 数据集构建:构建包含细微内容差异和风格偏差的数据集。 2. 评估指标:设计评估奖励模型对细微内容差异敏感性和对风格偏差抵抗力的指标。 3. 模型评估:使用RM-Bench评估现有奖励模型,并分析其优缺点。
关键创新:RM-Bench的关键创新在于其评估奖励模型的方式。它不再仅仅关注奖励模型区分不同能力模型生成回复的能力,而是更加关注奖励模型对细微内容差异的辨别能力和对风格偏差的鲁棒性。这种评估方式更贴近实际应用场景,能够更准确地评估奖励模型的质量。
关键设计:RM-Bench的关键设计包括: 1. 细微内容差异的构建:通过对原始文本进行细微的修改,例如替换同义词、调整语序等,来构建包含细微内容差异的数据集。 2. 风格偏差的引入:通过使用不同的写作风格,例如正式、非正式、幽默等,来引入风格偏差。 3. 评估指标的设计:设计能够衡量奖励模型对细微内容差异敏感性和对风格偏差抵抗力的指标,例如准确率、F1值等。
🖼️ 关键图片


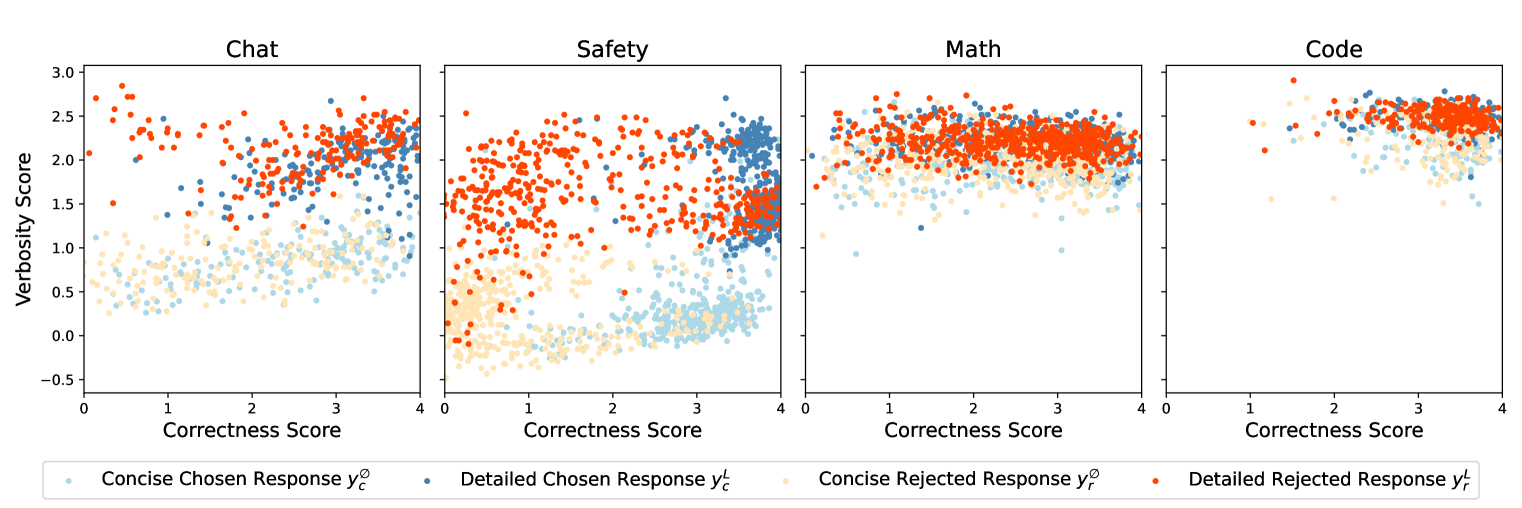
📊 实验亮点
实验结果表明,RM-Bench与策略模型性能高度相关,能够更准确地评估奖励模型。对近40个奖励模型的评估结果显示,即使是最先进的模型在面对风格偏差干扰时,平均性能也仅为46.6%,低于随机水平的准确率(50%),表明现有奖励模型在风格鲁棒性方面仍有很大的提升空间。
🎯 应用场景
RM-Bench可用于评估和选择更有效的奖励模型,从而提升基于人类反馈的强化学习(RLHF)的效果,并改进语言模型的对齐。该基准有助于开发更鲁棒、更细致的奖励模型,从而提升对话系统、文本生成等应用的性能和用户体验。此外,该研究也为奖励模型的设计和优化提供了新的思路。
📄 摘要(原文)
Reward models are critical in techniques like Reinforcement Learning from Human Feedback (RLHF) and Inference Scaling Laws, where they guide language model alignment and select optimal responses. Despite their importance, existing reward model benchmarks often evaluate models by asking them to distinguish between responses generated by models of varying power. However, this approach fails to assess reward models on subtle but critical content changes and variations in style, resulting in a low correlation with policy model performance. To this end, we introduce RM-Bench, a novel benchmark designed to evaluate reward models based on their sensitivity to subtle content differences and resistance to style biases. Extensive experiments demonstrate that RM-Bench strongly correlates with policy model performance, making it a reliable reference for selecting reward models to align language models effectively. We evaluate nearly 40 reward models on RM-Bench. Our results reveal that even state-of-the-art models achieve an average performance of only 46.6%, which falls short of random-level accuracy (50%) when faced with style bias interference. These findings highlight the significant room for improvement in current reward models. Related code and data are available at https://github.com/THU-KEG/RM-Bench.