MagicPIG: LSH Sampling for Efficient LLM Generation
作者: Zhuoming Chen, Ranajoy Sadhukhan, Zihao Ye, Yang Zhou, Jianyu Zhang, Niklas Nolte, Yuandong Tian, Matthijs Douze, Leon Bottou, Zhihao Jia, Beidi Chen
分类: cs.CL, cs.LG
发布日期: 2024-10-21 (更新: 2024-12-18)
🔗 代码/项目: GITHUB
💡 一句话要点
MagicPIG:基于LSH采样的LLM高效生成方法,提升长文本处理性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 长上下文 注意力机制 局部敏感哈希 采样 高效推理 KV缓存 异构计算
📋 核心要点
- 现有TopK注意力方法在某些任务中表现不佳,因为注意力并非总是稀疏的,导致性能下降。
- MagicPIG采用基于LSH的采样方法,以理论保证提供更好的注意力输出估计,提高生成质量。
- MagicPIG在CPU上存储LSH哈希表并运行注意力计算,显著提升长文本处理的解码吞吐量。
📝 摘要(中文)
具有长上下文窗口的大型语言模型(LLM)受到了广泛关注。然而,为避免重复计算而存储的KV缓存成为了瓶颈。现有的动态稀疏或基于TopK的注意力近似方法被提出,它们利用了注意力是稀疏的这一常见观点。本文首先表明,TopK注意力本身在某些下游任务中会降低质量,因为注意力并不总是像预期的那样稀疏。与选择具有最高注意力分数的键和值不同,具有理论保证的采样可以为注意力输出提供更好的估计。为了使基于采样的近似在LLM生成中实用,我们提出了一种基于局部敏感哈希(LSH)的异构系统MagicPIG。MagicPIG显著减少了注意力计算的工作量,同时保持了各种任务的高精度。MagicPIG将LSH哈希表存储在CPU上并运行注意力计算,这使其能够以高近似精度服务于更长的上下文和更大的批处理大小。MagicPIG可以在各种GPU硬件上将解码吞吐量提高高达5倍,并且对于具有96k tokens上下文的Llama-3.1-8B-Instruct模型,在单个RTX 4090上实现54ms的解码延迟。代码可在https://github.com/Infini-AI-Lab/MagicPIG获取。
🔬 方法详解
问题定义:现有的大型语言模型在处理长上下文时,KV缓存会成为性能瓶颈。虽然TopK注意力机制试图通过选择最重要的键值对来缓解这个问题,但它在某些情况下会因为注意力分布并非真正稀疏而导致精度下降。因此,如何更有效地近似注意力计算,同时保证生成质量,是一个关键问题。
核心思路:MagicPIG的核心思路是使用基于局部敏感哈希(LSH)的采样方法来近似注意力计算。与直接选择具有最高注意力分数的TopK键值对不同,LSH采样通过哈希函数将相似的键映射到同一个桶中,然后在每个桶内进行采样。这种方法能够以更高的概率选择到重要的键值对,从而提供更准确的注意力输出估计。
技术框架:MagicPIG是一个异构系统,它将LSH哈希表的存储和注意力计算放在CPU上进行,而将模型的其他部分放在GPU上。整体流程如下:1. 将键向量通过LSH哈希函数映射到不同的桶中。2. 在每个桶内进行采样,选择一部分键值对。3. 使用采样的键值对进行注意力计算。4. 将计算结果传递给GPU上的模型进行后续处理。
关键创新:MagicPIG的关键创新在于使用LSH采样来近似注意力计算,并将其部署在CPU上。与TopK注意力相比,LSH采样能够提供更准确的注意力输出估计,尤其是在注意力分布不稀疏的情况下。将LSH哈希表存储和注意力计算放在CPU上,可以有效利用CPU的内存资源,从而支持更长的上下文和更大的批处理大小。
关键设计:MagicPIG的关键设计包括:1. LSH哈希函数的选择:论文可能采用了多种LSH哈希函数,例如随机投影哈希或交叉多项式哈希,以提高哈希的准确性。2. 桶大小的设置:桶的大小会影响采样的效率和准确性,需要根据具体的任务和数据集进行调整。3. 采样策略:论文可能采用了不同的采样策略,例如均匀采样或基于权重的采样,以提高采样的效率和准确性。4. CPU和GPU之间的通信:论文需要设计高效的CPU和GPU之间的数据传输机制,以减少通信开销。
🖼️ 关键图片
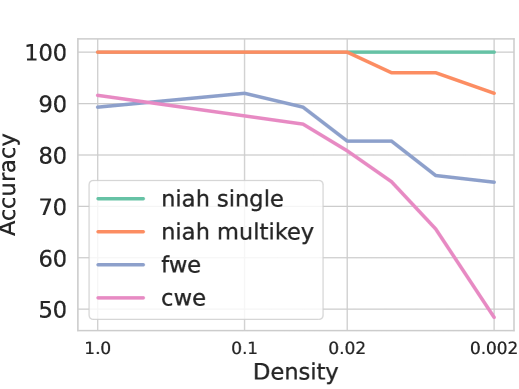


📊 实验亮点
MagicPIG在各种GPU硬件上将解码吞吐量提高了高达5倍。对于具有96k tokens上下文的Llama-3.1-8B-Instruct模型,在单个RTX 4090上实现了54ms的解码延迟。这些结果表明,MagicPIG能够显著提高长文本处理的效率,并降低推理成本。
🎯 应用场景
MagicPIG适用于需要处理长上下文的各种大型语言模型应用,例如长文档摘要、对话系统、代码生成等。通过提高解码吞吐量和支持更大的批处理大小,MagicPIG可以显著降低推理成本,并提高用户体验。该方法还有潜力应用于其他需要高效注意力计算的场景,例如机器翻译和语音识别。
📄 摘要(原文)
Large language models (LLMs) with long context windows have gained significant attention. However, the KV cache, stored to avoid re-computation, becomes a bottleneck. Various dynamic sparse or TopK-based attention approximation methods have been proposed to leverage the common insight that attention is sparse. In this paper, we first show that TopK attention itself suffers from quality degradation in certain downstream tasks because attention is not always as sparse as expected. Rather than selecting the keys and values with the highest attention scores, sampling with theoretical guarantees can provide a better estimation for attention output. To make the sampling-based approximation practical in LLM generation, we propose MagicPIG, a heterogeneous system based on Locality Sensitive Hashing (LSH). MagicPIG significantly reduces the workload of attention computation while preserving high accuracy for diverse tasks. MagicPIG stores the LSH hash tables and runs the attention computation on the CPU, which allows it to serve longer contexts and larger batch sizes with high approximation accuracy. MagicPIG can improve decoding throughput by up to $5\times$ across various GPU hardware and achieve 54ms decoding latency on a single RTX 4090 for Llama-3.1-8B-Instruct model with a context of 96k tokens. The code is available at https://github.com/Infini-AI-Lab/MagicPIG.