Guardians of Discourse: Evaluating LLMs on Multilingual Offensive Language Detection
作者: Jianfei He, Lilin Wang, Jiaying Wang, Zhenyu Liu, Hongbin Na, Zimu Wang, Wei Wang, Qi Chen
分类: cs.CL
发布日期: 2024-10-21
备注: Accepted at UIC 2024 proceedings. Accepted version
💡 一句话要点
评估LLM在多语言攻击性语言检测中的表现,揭示其偏见与局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言攻击性语言检测 大型语言模型 自然语言处理 偏见分析 社交媒体分析
📋 核心要点
- 现有大型语言模型在多语言环境下攻击性语言检测能力评估不足,存在局限性。
- 本文通过多语言实验,评估了GPT-3.5、Flan-T5和Mistral在攻击性语言检测中的表现。
- 实验分析了提示语言和翻译数据对非英语环境的影响,并讨论了模型和数据的固有偏见。
📝 摘要(中文)
在社交媒体时代,识别攻击性语言对于维护安全和可持续性至关重要。尽管大型语言模型(LLMs)在社交媒体分析中展现出令人鼓舞的潜力,但在攻击性语言检测方面,尤其是在多语言环境中,它们缺乏全面的评估。本文首次评估了LLMs在三种语言(英语、西班牙语和德语)中的多语言攻击性语言检测能力,使用了GPT-3.5、Flan-T5和Mistral这三种LLMs,分别在单语和多语设置下进行。我们进一步研究了不同提示语言和增强翻译数据对非英语环境中任务的影响。此外,我们还讨论了LLMs和数据集中固有的偏见对与敏感话题相关的错误预测的影响。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在多语言环境下攻击性语言检测能力评估不足的问题。现有方法缺乏对LLMs在不同语言和文化背景下检测攻击性语言的全面评估,并且忽略了模型和数据中可能存在的偏见,导致在实际应用中可能出现误判和不公平现象。
核心思路:论文的核心思路是通过构建多语言攻击性语言检测数据集,并在此基础上对多种LLMs进行系统性的评估。通过对比LLMs在不同语言、不同设置下的表现,以及分析其错误预测的原因,从而揭示LLMs在多语言攻击性语言检测方面的优势和不足。同时,研究提示语言和翻译数据对模型性能的影响,并探讨模型和数据中存在的偏见。
技术框架:论文的整体框架包括以下几个主要步骤:1) 数据收集与准备:构建包含英语、西班牙语和德语的攻击性语言检测数据集。2) 模型选择与配置:选择GPT-3.5、Flan-T5和Mistral三种LLMs作为评估对象,并在单语和多语设置下进行配置。3) 实验设计与评估:设计不同的实验方案,包括不同提示语言和增强翻译数据的使用,并采用准确率、召回率、F1值等指标对模型性能进行评估。4) 误差分析与偏见讨论:分析模型错误预测的原因,并讨论模型和数据中存在的偏见。
关键创新:论文的主要创新点在于:1) 首次对LLMs在多语言攻击性语言检测任务中进行系统性的评估。2) 深入研究了提示语言和翻译数据对模型性能的影响。3) 探讨了模型和数据中存在的偏见,并分析了其对模型预测结果的影响。
关键设计:论文的关键设计包括:1) 多语言数据集的构建,确保数据集的质量和多样性。2) 实验方案的设计,包括单语和多语设置、不同提示语言和增强翻译数据的使用,以全面评估模型性能。3) 评估指标的选择,采用准确率、召回率、F1值等指标,以综合评估模型性能。4) 误差分析的方法,通过分析模型错误预测的原因,揭示模型和数据中存在的偏见。
🖼️ 关键图片

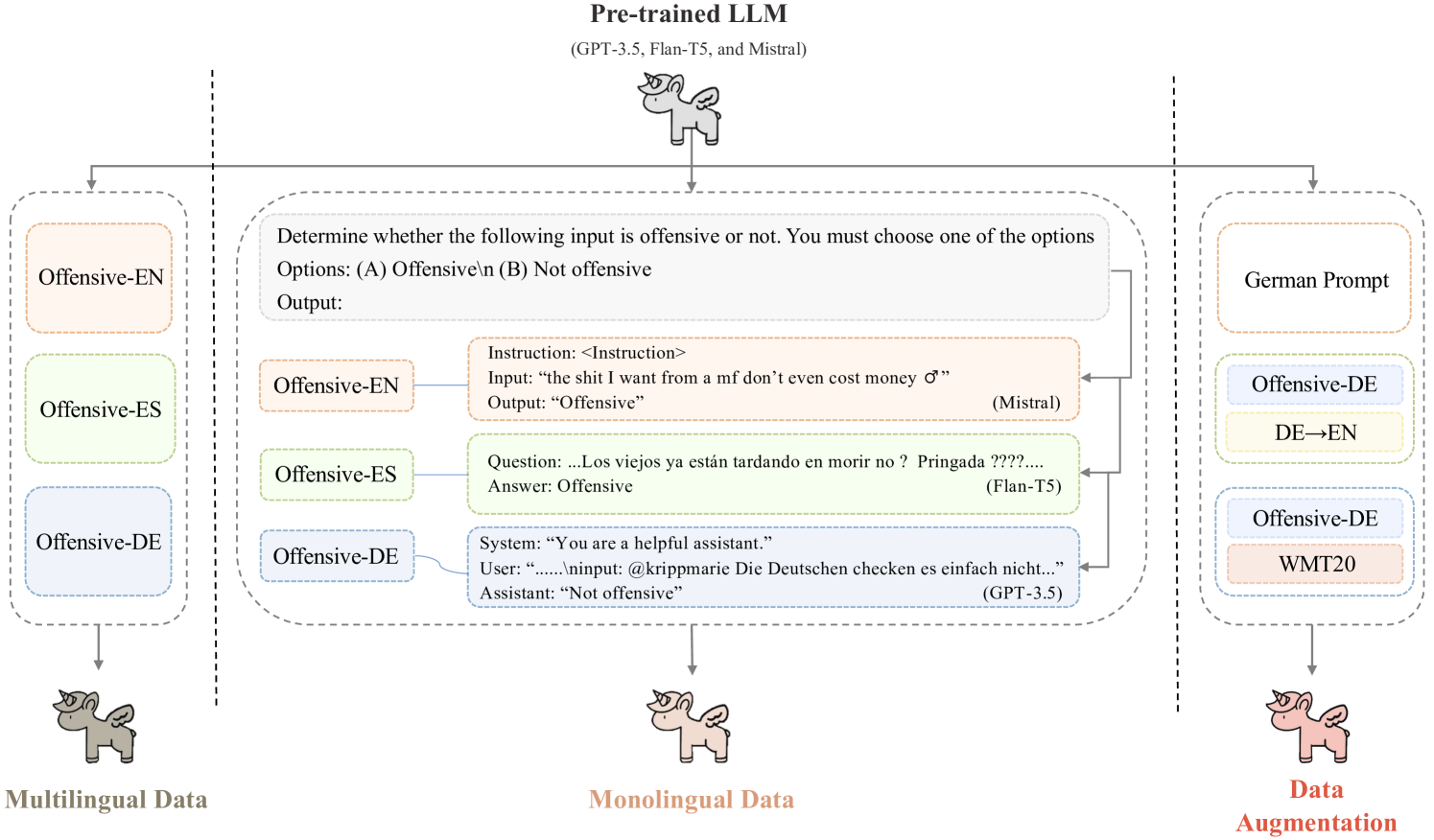
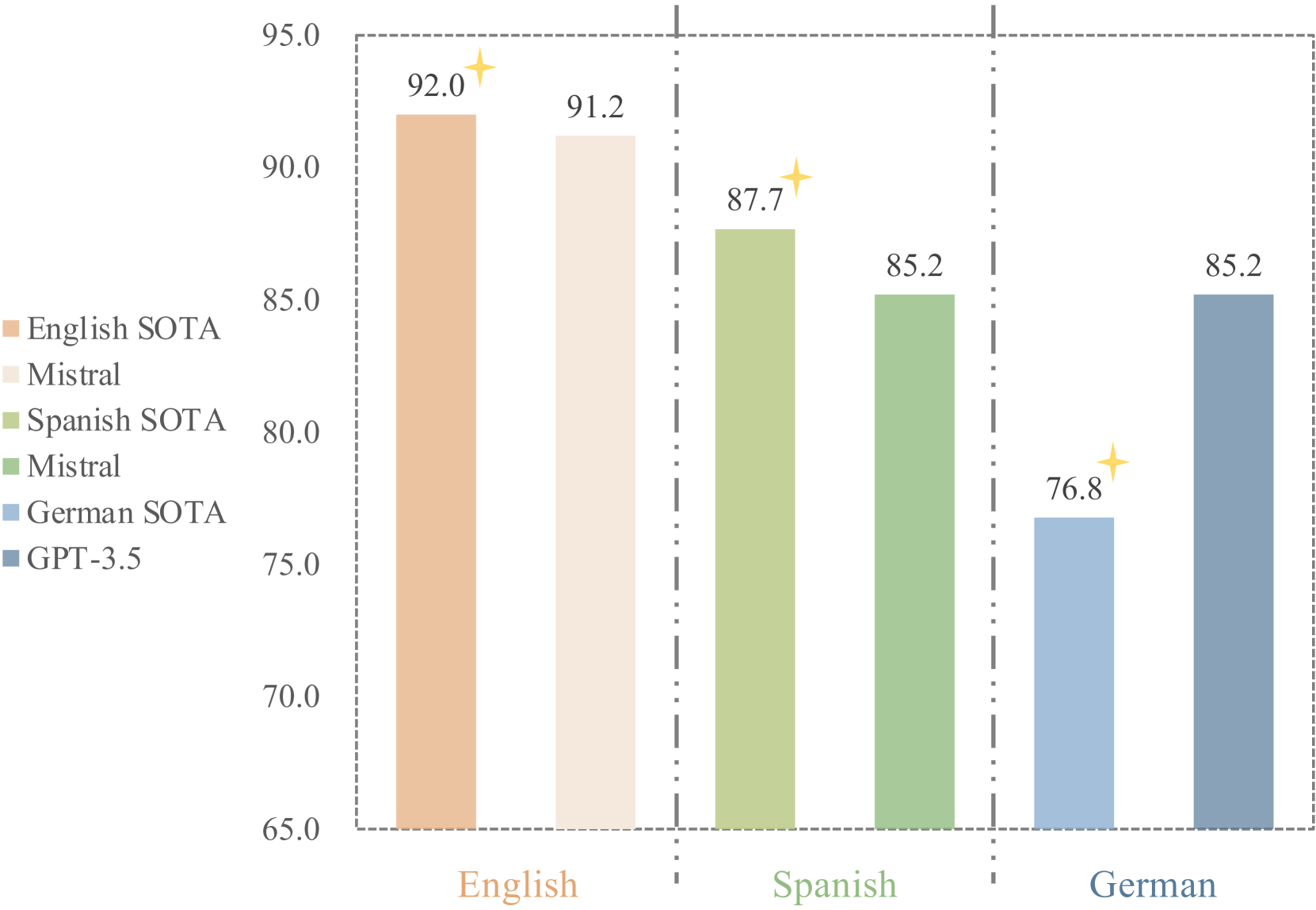
📊 实验亮点
实验结果表明,LLMs在多语言攻击性语言检测任务中表现出一定的潜力,但仍存在局限性。例如,在某些语言和文化背景下,模型的性能明显下降。此外,实验还发现,提示语言和翻译数据对模型性能有显著影响。例如,使用目标语言作为提示语言可以提高模型性能,而增强翻译数据可以改善模型在非英语环境下的表现。研究还揭示了模型和数据中存在的偏见,这些偏见可能导致模型在处理敏感话题时出现误判。
🎯 应用场景
该研究成果可应用于社交媒体平台的内容审核、舆情监控、在线社区管理等领域,帮助识别和过滤攻击性言论,维护网络空间的健康和安全。此外,该研究还可以为LLMs的开发和优化提供指导,使其在多语言环境下更好地理解和处理文本信息,减少偏见和误判,提升用户体验。
📄 摘要(原文)
Identifying offensive language is essential for maintaining safety and sustainability in the social media era. Though large language models (LLMs) have demonstrated encouraging potential in social media analytics, they lack thorough evaluation when in offensive language detection, particularly in multilingual environments. We for the first time evaluate multilingual offensive language detection of LLMs in three languages: English, Spanish, and German with three LLMs, GPT-3.5, Flan-T5, and Mistral, in both monolingual and multilingual settings. We further examine the impact of different prompt languages and augmented translation data for the task in non-English contexts. Furthermore, we discuss the impact of the inherent bias in LLMs and the datasets in the mispredictions related to sensitive topics.