Keep Guessing? When Considering Inference Scaling, Mind the Baselines
作者: Gal Yona, Or Honovich, Omer Levy, Roee Aharoni
分类: cs.CL, cs.AI
发布日期: 2024-10-20
💡 一句话要点
提出基于训练集答案频率的基线方法,评估LLM重复采样推理的真实提升
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 重复采样 推理评估 基线方法 训练集频率
📋 核心要点
- 现有LLM通过重复采样提升推理效果,但标准评测集答案分布可能存在偏差,导致评估结果虚高。
- 论文提出一种基于训练集答案频率的基线方法,用于更准确地评估重复采样带来的真实性能提升。
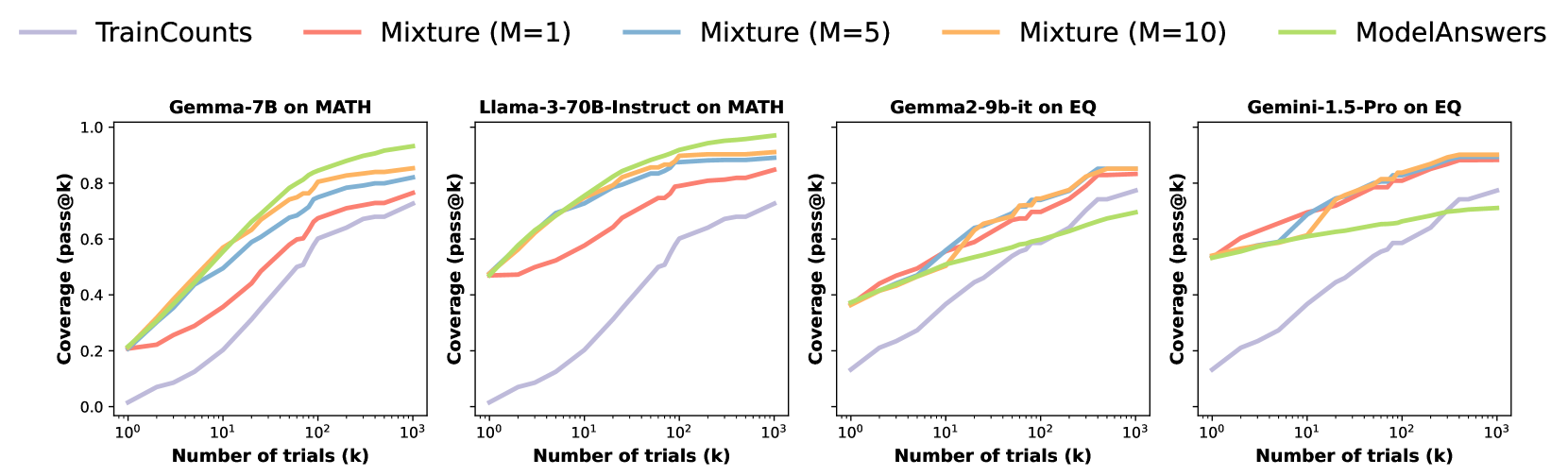
- 实验表明,该基线在某些LLM上优于重复采样,或与混合策略相当,揭示了重复采样的部分收益来自简单猜测。
📝 摘要(中文)
通过重复采样来扩展大型语言模型(LLM)的推理计算,通常可以提高覆盖率(解决问题的比例),因为随着样本数量的增加,模型更有可能命中正确答案。本文提出,这种观察到的改进部分是由于标准评估基准的答案分布偏向于相对较小的一组常见答案。为了验证这一猜想,作者定义了一个基线,该基线根据答案在训练集中的流行程度来枚举答案。在数学推理和事实知识两个领域的实验表明,对于某些LLM,该基线的性能优于重复模型采样;而对于另一些LLM,该基线的覆盖率与一种混合策略相当,该策略仅使用10个模型样本获得k个答案,并通过枚举猜测剩余的k-10个尝试。该基线能够更准确地衡量重复采样在这种设置中对覆盖率的提升,从而排除了与提示无关的猜测带来的影响。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在评估时,通过重复采样提升推理效果的评估偏差问题。现有方法直接评估重复采样带来的性能提升,但忽略了标准评估数据集答案分布的偏差,即少量答案占据了大部分的正确答案,导致重复采样可能只是增加了命中常见答案的概率,而非模型真正理解了问题。
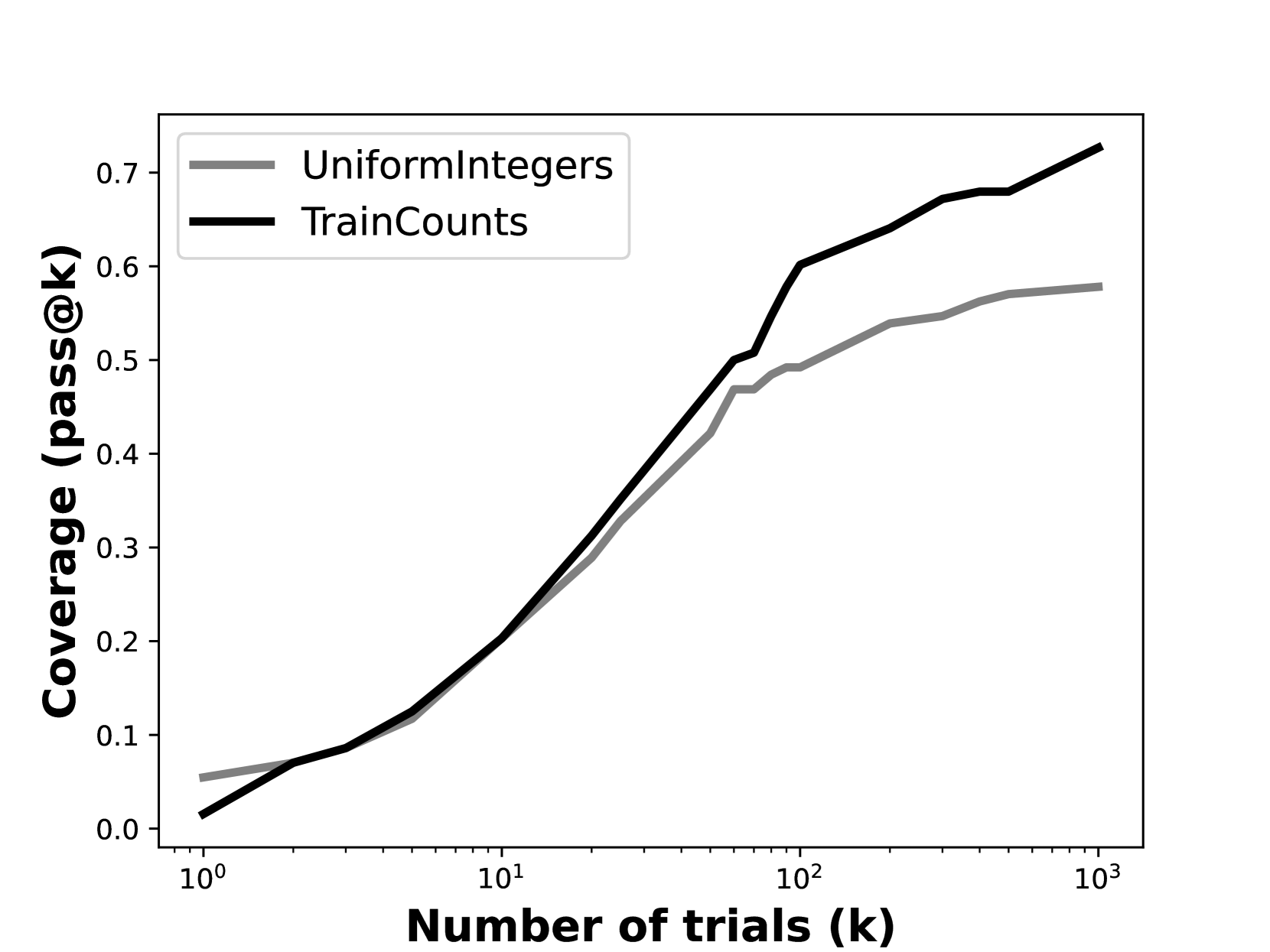
核心思路:论文的核心思路是构建一个基于训练集答案频率的基线模型,该模型不依赖于任何推理能力,而是简单地按照答案在训练集中出现的频率进行猜测。通过比较LLM重复采样的性能与该基线的性能,可以更准确地评估LLM通过重复采样获得的真实性能提升,排除简单猜测带来的影响。
技术框架:论文的技术框架主要包含以下几个部分:1) 定义基于训练集答案频率的基线模型;2) 在数学推理和事实知识两个领域,使用不同的LLM进行实验;3) 比较LLM重复采样的性能与基线模型的性能;4) 分析实验结果,评估重复采样带来的真实性能提升。
关键创新:论文的关键创新在于提出了基于训练集答案频率的基线模型,用于评估LLM重复采样推理的真实提升。该基线模型不依赖于任何推理能力,而是简单地按照答案在训练集中出现的频率进行猜测,从而可以排除简单猜测带来的影响,更准确地评估LLM的推理能力。
关键设计:基线模型的核心是计算训练集中每个答案的频率,并按照频率从高到低的顺序进行猜测。具体来说,对于每个问题,基线模型首先从训练集中提取所有可能的答案,然后计算每个答案在训练集中出现的次数,最后按照出现次数从高到低的顺序进行排序。在进行猜测时,基线模型按照排序后的顺序依次猜测答案,直到猜中正确答案或者达到最大猜测次数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在数学推理和事实知识两个领域,对于某些LLM,基于训练集答案频率的基线模型的性能优于重复模型采样。对于另一些LLM,该基线的覆盖率与一种混合策略相当,该策略仅使用10个模型样本获得k个答案,并通过枚举猜测剩余的k-10个尝试。这些结果表明,重复采样的部分收益来自简单猜测,而非模型真正理解了问题。
🎯 应用场景
该研究成果可应用于更准确地评估大型语言模型的推理能力,避免因评估数据集偏差而产生误导性结论。此外,该方法可以帮助研究人员更好地理解重复采样在提升LLM性能中的作用,并指导模型训练和优化。
📄 摘要(原文)
Scaling inference compute in large language models (LLMs) through repeated sampling consistently increases the coverage (fraction of problems solved) as the number of samples increases. We conjecture that this observed improvement is partially due to the answer distribution of standard evaluation benchmarks, which is skewed towards a relatively small set of common answers. To test this conjecture, we define a baseline that enumerates answers according to their prevalence in the training set. Experiments spanning two domains -- mathematical reasoning and factual knowledge -- reveal that this baseline outperforms repeated model sampling for some LLMs, while the coverage for others is on par with that of a mixture strategy that obtains $k$ answers by using only $10$ model samples and similarly guessing the remaining $k-10$ attempts via enumeration. Our baseline enables a more accurate measurement of how much repeated sampling improves coverage in such settings beyond prompt-agnostic guessing.