Evaluating Deep Unlearning in Large Language Models
作者: Ruihan Wu, Chhavi Yadav, Russ Salakhutdinov, Kamalika Chaudhuri
分类: cs.CL
发布日期: 2024-10-19 (更新: 2025-11-11)
💡 一句话要点
提出深度卸载学习框架,评估LLM在删除目标事实及其逻辑推导结果上的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 深度卸载学习 机器卸载学习 大型语言模型 知识推理 数据集构建
📋 核心要点
- 现有LLM事实卸载方法忽略了知识间的逻辑推导关系,导致卸载不彻底。
- 提出“深度卸载学习”概念,旨在移除目标事实及其通过逻辑推理可得的结论。
- 构建半合成数据集Eval-DU,并设计指标Success-DU、Recall和Accuracy来评估卸载效果。
📝 摘要(中文)
机器卸载学习已成为开发安全可信模型的重要组成部分。现有关于LLM中事实卸载的工作主要集中于稳健地移除指定的目标事实,但常常忽略其与其他知识的演绎联系。我们提出了一个新的事实卸载设置,即深度卸载学习,其目标不仅是移除目标事实,还要阻止通过LLM中保留的知识和逻辑推理来推导出该事实。我们提出了三个新的指标:Success-DU和Recall来衡量卸载效果,以及Accuracy来衡量剩余模型的效用。为了评估这个设置,我们利用了(1)现有的真实世界知识数据集MQuAKE,它提供了一步演绎实例,以及(2)新构建的半合成数据集Eval-DU,它允许合成事实之间进行多步的现实演绎。实验表明,当前的方法在深度卸载学习方面表现不佳:它们要么未能深度卸载,要么过度地移除了不相关的事实。我们的结果表明,可能需要开发有针对性的算法,以实现LLM中稳健/深度的事实卸载。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中事实卸载不彻底的问题。现有方法主要关注直接删除目标事实,而忽略了LLM可以通过已有的知识进行逻辑推理,从而重新推导出被删除的事实。这种现象使得卸载效果大打折扣,模型仍然可能泄露敏感或错误的信息。现有方法的痛点在于缺乏对知识间深层联系的考虑,无法实现真正的“深度卸载”。
核心思路:论文的核心思路是不仅要删除目标事实,还要阻止LLM通过其他知识和逻辑推理重新推导出该事实。这需要一种更全面的卸载策略,不仅要移除显式知识,还要消除或削弱相关的推理路径。通过这种方式,可以确保模型在卸载后不会泄露或重新生成被删除的信息。
技术框架:论文提出了一个评估深度卸载学习的框架,主要包含以下几个部分:1)定义了深度卸载学习的概念和目标;2)提出了三个新的评估指标:Success-DU、Recall和Accuracy,用于衡量卸载效果和模型效用;3)利用现有的MQuAKE数据集和新构建的Eval-DU数据集进行实验评估。Eval-DU数据集允许进行多步的现实演绎,更全面地评估深度卸载能力。
关键创新:论文最重要的技术创新点在于提出了“深度卸载学习”的概念,并将其形式化为一个可评估的问题。与以往只关注直接事实删除的工作不同,该论文强调了知识间的逻辑推导关系,并提出了相应的评估指标和数据集。这种对卸载学习的更深层次的理解是该论文的核心贡献。
关键设计:Eval-DU数据集的关键设计在于其半合成的特性,它允许控制事实之间的逻辑关系,并生成多步推理的实例。Success-DU指标衡量模型成功卸载目标事实及其推导结果的能力,Recall指标衡量模型移除了多少与目标事实相关的知识,Accuracy指标衡量模型在卸载后保留了多少有用的知识。这些指标共同构成了对深度卸载学习效果的全面评估。
🖼️ 关键图片

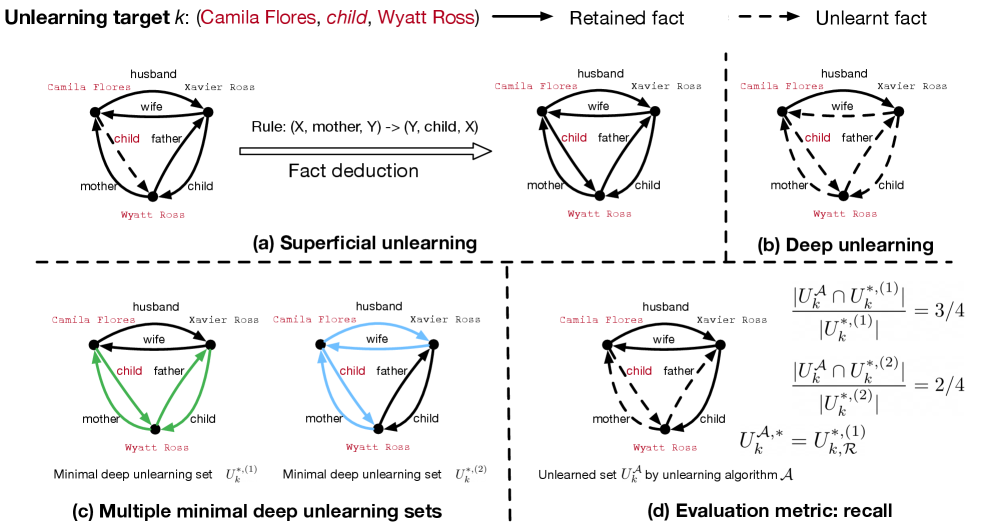
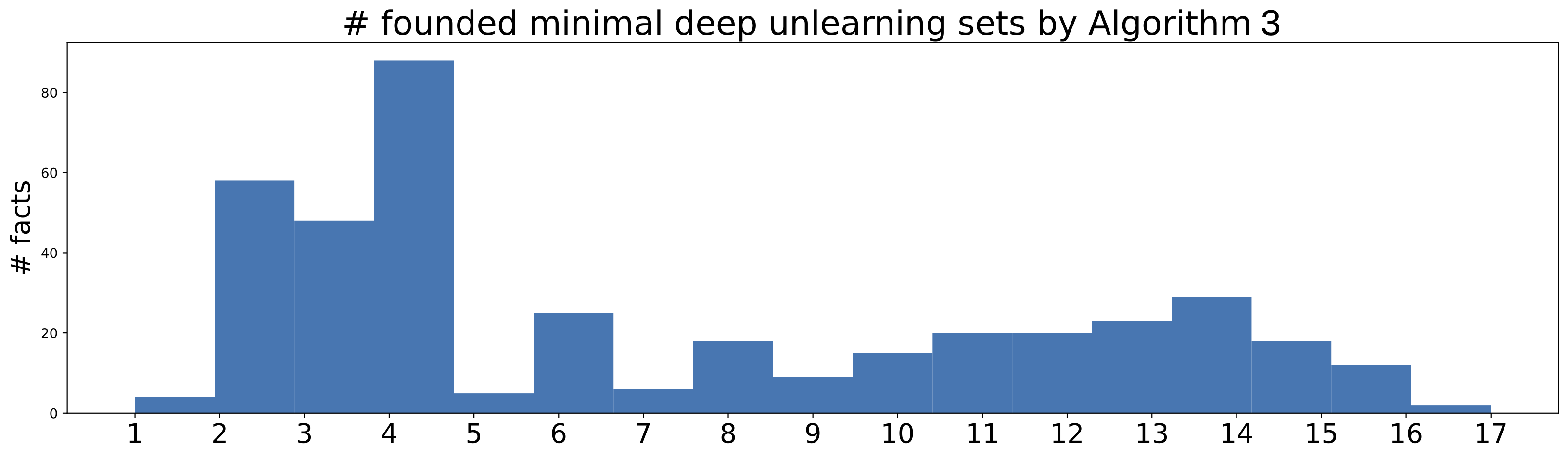
📊 实验亮点
实验结果表明,现有方法在深度卸载学习方面表现不佳,要么无法彻底移除目标事实及其推导结果,要么过度移除不相关的事实。这表明需要开发专门针对深度卸载学习的算法,以在保证卸载效果的同时,尽可能保留模型的有用知识。Eval-DU数据集的构建和相关指标的提出,为未来研究提供了基准和评估工具。
🎯 应用场景
该研究成果可应用于需要保护用户隐私、防止模型泄露敏感信息或纠正模型错误知识的场景。例如,在医疗、金融等领域,可以利用深度卸载学习技术来移除模型中与特定用户或事件相关的信息,从而避免隐私泄露。此外,该技术还可以用于修复模型中的错误知识,提高模型的可靠性和安全性。
📄 摘要(原文)
Machine unlearning has emerged as an important component in developing safe and trustworthy models. Prior work on fact unlearning in LLMs has mostly focused on removing a specified target fact robustly, but often overlooks its deductive connections to other knowledge. We propose a new setting for fact unlearning, deep unlearning, where the goal is not only to remove a target fact but also to prevent it from being deduced via retained knowledge in the LLM and logical reasoning. We propose three novel metrics: Success-DU and Recall to measure unlearning efficacy, and Accuracy to measure the remainder model utility. To benchmark this setting, we leverage both (1) an existing real-world knowledge dataset, MQuAKE, that provides one-step deduction instances, and (2) newly construct a novel semi-synthetic dataset, Eval-DU, that allows multiple steps of realistic deductions among synthetic facts. Experiments reveal that current methods struggle with deep unlearning: they either fail to deeply unlearn, or excessively remove unrelated facts. Our results suggest that targeted algorithms may have to be developed for robust/deep fact unlearning in LLMs.