DM-Codec: Distilling Multimodal Representations for Speech Tokenization
作者: Md Mubtasim Ahasan, Md Fahim, Tasnim Mohiuddin, A K M Mahbubur Rahman, Aman Chadha, Tariq Iqbal, M Ashraful Amin, Md Mofijul Islam, Amin Ahsan Ali
分类: cs.CL, cs.AI, cs.SD, eess.AS
发布日期: 2024-10-19 (更新: 2025-09-29)
备注: Accepted at EMNLP 2025
🔗 代码/项目: GITHUB
💡 一句话要点
DM-Codec通过多模态表示蒸馏进行语音Token化,显著降低了语音转录的错误率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音Token化 知识蒸馏 多模态融合 上下文建模 残差向量量化
📋 核心要点
- 现有语音Token化方法忽略了上下文表示在语音建模中的关键作用,导致语音转录的词错误率和词信息丢失率较高。
- DM-Codec通过语言模型和自监督语音模型引导的蒸馏,将声学、语义和上下文信息融合到语音Token化过程中。
- 实验结果表明,DM-Codec在LibriSpeech数据集上显著降低了词错误率和词信息丢失率,并提高了语音质量和可懂度。
📝 摘要(中文)
本文提出了一种名为DM-Codec的语音Token化方法,旨在解决现有方法在将语音复杂的多维属性映射到离散Token时,缺乏对上下文信息的有效利用的问题。DM-Codec采用两种新颖的蒸馏方法:一种是语言模型(LM)引导的蒸馏,用于整合上下文信息;另一种是结合LM和自监督语音模型(SM)引导的蒸馏,用于将声学、语义和上下文信息蒸馏成一个综合的语音Token化器。DM-Codec架构采用精简的编码器-解码器框架,配备残差向量量化器(RVQ),并在训练过程中融入LM和SM。实验结果表明,DM-Codec显著优于最先进的语音Token化模型,在LibriSpeech基准数据集上,词错误率(WER)降低高达13.46%,词信息丢失率(WIL)降低9.82%,语音质量提高5.84%,可懂度提高1.85%。
🔬 方法详解
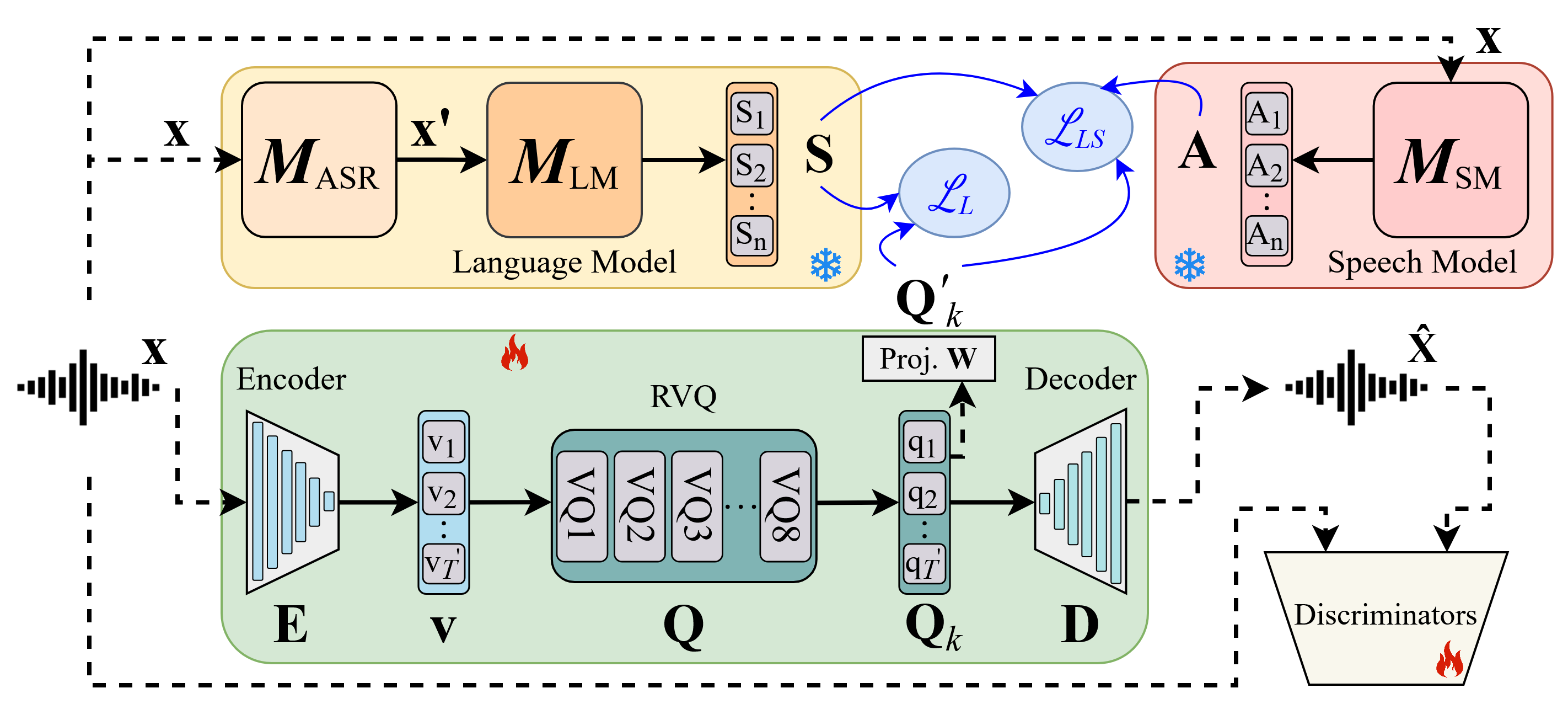
问题定义:现有语音Token化方法,如基于音频编解码器的声学Token和基于自监督学习模型的语义Token,在语音转录任务中表现出局限性。主要痛点在于缺乏对语音信号中上下文信息的有效建模,导致转录错误率较高。
核心思路:DM-Codec的核心思路是通过知识蒸馏,将语言模型(LM)和自监督语音模型(SM)的知识迁移到语音Token化器中,从而使Token化器能够同时捕获声学、语义和上下文信息。这样设计的目的是为了弥补现有方法在上下文建模方面的不足,提升语音转录的准确性。
技术框架:DM-Codec采用编码器-解码器框架,其中编码器负责将语音信号转换为中间表示,解码器负责将中间表示量化为离散的Token。该框架包含以下主要模块:1) 编码器;2) 残差向量量化器(RVQ),用于将连续的语音表示量化为离散的Token;3) 解码器;4) 语言模型(LM)和自监督语音模型(SM),用于在训练过程中提供上下文和语义信息。
关键创新:DM-Codec的关键创新在于提出了两种新的蒸馏方法:1) LM引导的蒸馏,通过最小化Token化器输出和LM输出之间的差异,使Token化器学习到上下文信息;2) 结合LM和SM引导的蒸馏,同时利用LM和SM的知识,使Token化器能够捕获声学、语义和上下文信息。
关键设计:DM-Codec的关键设计包括:1) 使用残差向量量化器(RVQ)进行Token化,允许模型生成多层次的Token表示;2) 在训练过程中,使用LM和SM作为教师模型,通过最小化KL散度等损失函数,将知识迁移到Token化器中;3) 采用精简的编码器-解码器结构,以提高模型的效率。
🖼️ 关键图片


📊 实验亮点
DM-Codec在LibriSpeech数据集上取得了显著的性能提升。与最先进的语音Token化模型相比,DM-Codec将词错误率(WER)降低了高达13.46%,词信息丢失率(WIL)降低了9.82%,语音质量提高了5.84%,可懂度提高了1.85%。这些结果表明,DM-Codec能够更有效地捕获语音信号中的信息,并生成更准确的语音表示。
🎯 应用场景
DM-Codec在语音识别、语音合成、语音翻译等领域具有广泛的应用前景。它可以用于构建更高质量的语音转录系统,提升语音交互设备的性能,并为语音相关的AI应用提供更准确的语音表示。未来,该技术有望应用于智能客服、语音助手、自动字幕生成等场景。
📄 摘要(原文)
Recent advancements in speech-language models have yielded significant improvements in speech tokenization and synthesis. However, effectively mapping the complex, multidimensional attributes of speech into discrete tokens remains challenging. This process demands acoustic, semantic, and contextual information for precise speech representations. Existing speech representations generally fall into two categories: acoustic tokens from audio codecs and semantic tokens from speech self-supervised learning models. Although recent efforts have unified acoustic and semantic tokens for improved performance, they overlook the crucial role of contextual representation in comprehensive speech modeling. Our empirical investigations reveal that the absence of contextual representations results in elevated Word Error Rate (WER) and Word Information Lost (WIL) scores in speech transcriptions. To address these limitations, we propose two novel distillation approaches: (1) a language model (LM)-guided distillation method that incorporates contextual information, and (2) a combined LM and self-supervised speech model (SM)-guided distillation technique that effectively distills multimodal representations (acoustic, semantic, and contextual) into a comprehensive speech tokenizer, termed DM-Codec. The DM-Codec architecture adopts a streamlined encoder-decoder framework with a Residual Vector Quantizer (RVQ) and incorporates the LM and SM during the training process. Experiments show DM-Codec significantly outperforms state-of-the-art speech tokenization models, reducing WER by up to 13.46%, WIL by 9.82%, and improving speech quality by 5.84% and intelligibility by 1.85% on the LibriSpeech benchmark dataset. Code, samples, and checkpoints are available at https://github.com/mubtasimahasan/DM-Codec.