SemiHVision: Enhancing Medical Multimodal Models with a Semi-Human Annotated Dataset and Fine-Tuned Instruction Generation
作者: Junda Wang, Yujan Ting, Eric Z. Chen, Hieu Tran, Hong Yu, Weijing Huang, Terrence Chen
分类: cs.CL, cs.CV
发布日期: 2024-10-19
💡 一句话要点
SemiHVision:通过半人工标注数据集和微调指令生成增强医学多模态模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学多模态模型 半监督学习 指令微调 诊断推理 医学图像分析
📋 核心要点
- 医学多模态大语言模型在实际应用中面临挑战,现有模型在真实临床任务中的表现与实验室环境存在差距。
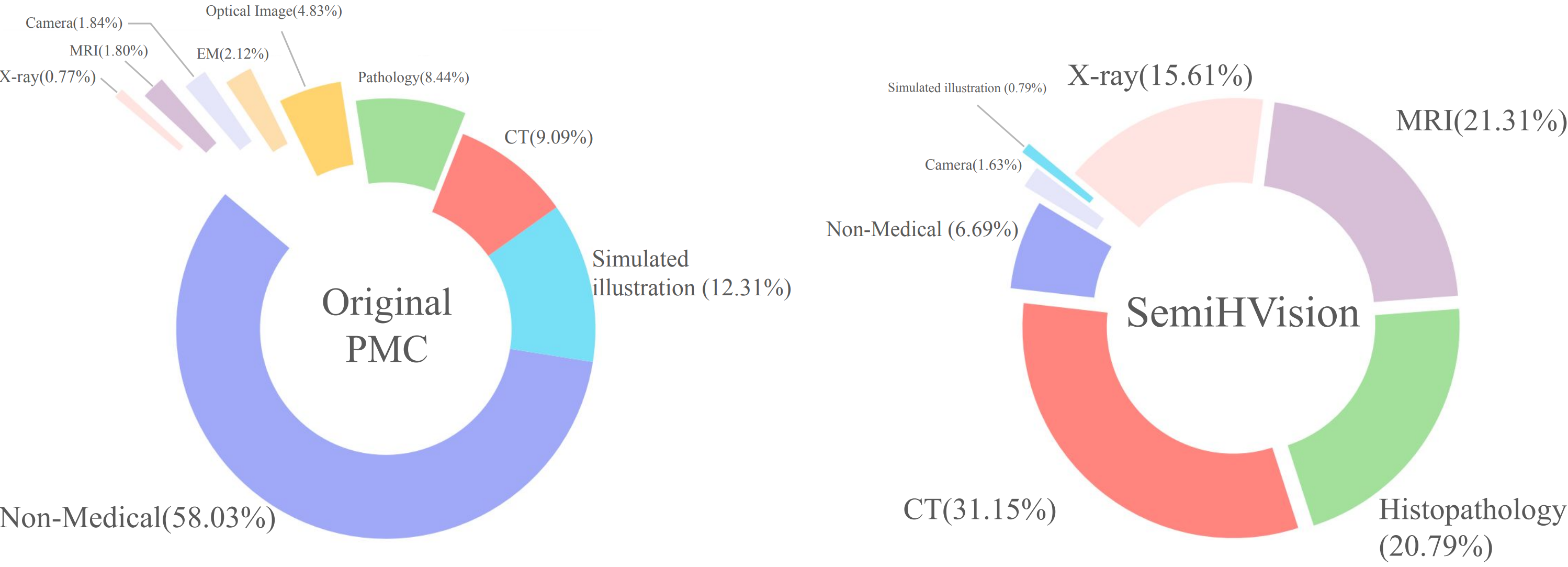
- 论文提出SemiHVision数据集,结合人工标注和自动增强,提升模型医学知识表示和诊断推理能力。
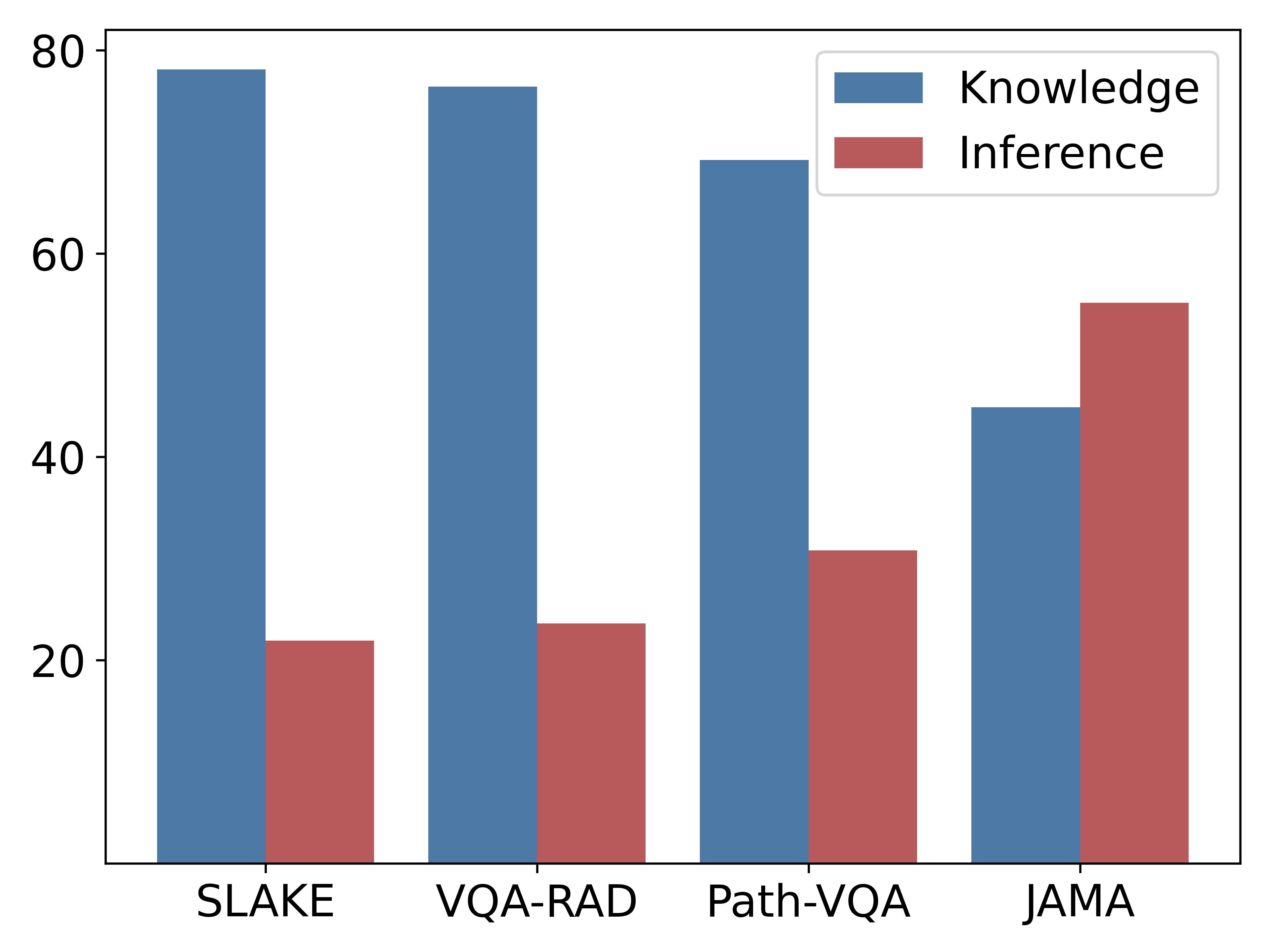
- PMC-Cambrian-AN模型在SLAKE、VQA-RAD和JAMA临床挑战等基准测试中均取得优异成绩,展现卓越性能。
📝 摘要(中文)
多模态大型语言模型(MLLM)取得了显著进展,但由于缺乏专业的医学知识,它们在医学领域面临挑战。虽然最近的医学MLLM在实验室环境中表现出强大的性能,但它们在实际应用中常常表现不佳,突出了研究与实践之间的巨大差距。本文旨在解决端到端学习流程各个阶段的差距,包括数据收集、模型微调和评估。在数据收集阶段,我们引入了SemiHVision数据集,该数据集结合了人工标注和自动增强技术,以提高医学知识表示和诊断推理能力。对于模型微调,我们使用超过2400个H100 GPU小时训练了PMC-Cambrian-8B-AN,使其在SLAKE和VQA-RAD等传统基准测试中,性能超越了HuatuoGPT-Vision-34B(79.0% vs. 66.7%)等公共医学模型和Claude3-Opus(55.7%)等私有通用模型。在评估阶段,我们观察到传统基准测试无法准确反映真实的临床任务能力。为了克服这一限制,并为模型评估提供更有针对性的指导,我们引入了JAMA临床挑战,这是一个专门用于评估诊断推理的新基准。在这一基准上,PMC-Cambrian-AN取得了最先进的性能,GPT-4得分为1.29,显著优于HuatuoGPT-Vision-34B(1.13)和Claude3-Opus(1.17),证明了其卓越的诊断推理能力。
🔬 方法详解
问题定义:医学多模态大语言模型在实际临床应用中表现不佳,现有数据集和评估基准无法充分反映模型的真实诊断推理能力。模型缺乏足够的医学知识和有效的推理机制,导致在复杂病例分析中表现不足。
核心思路:通过构建高质量的半人工标注数据集SemiHVision,并结合指令微调,增强模型对医学知识的理解和应用能力。同时,设计新的评估基准JAMA临床挑战,更准确地评估模型的诊断推理能力。
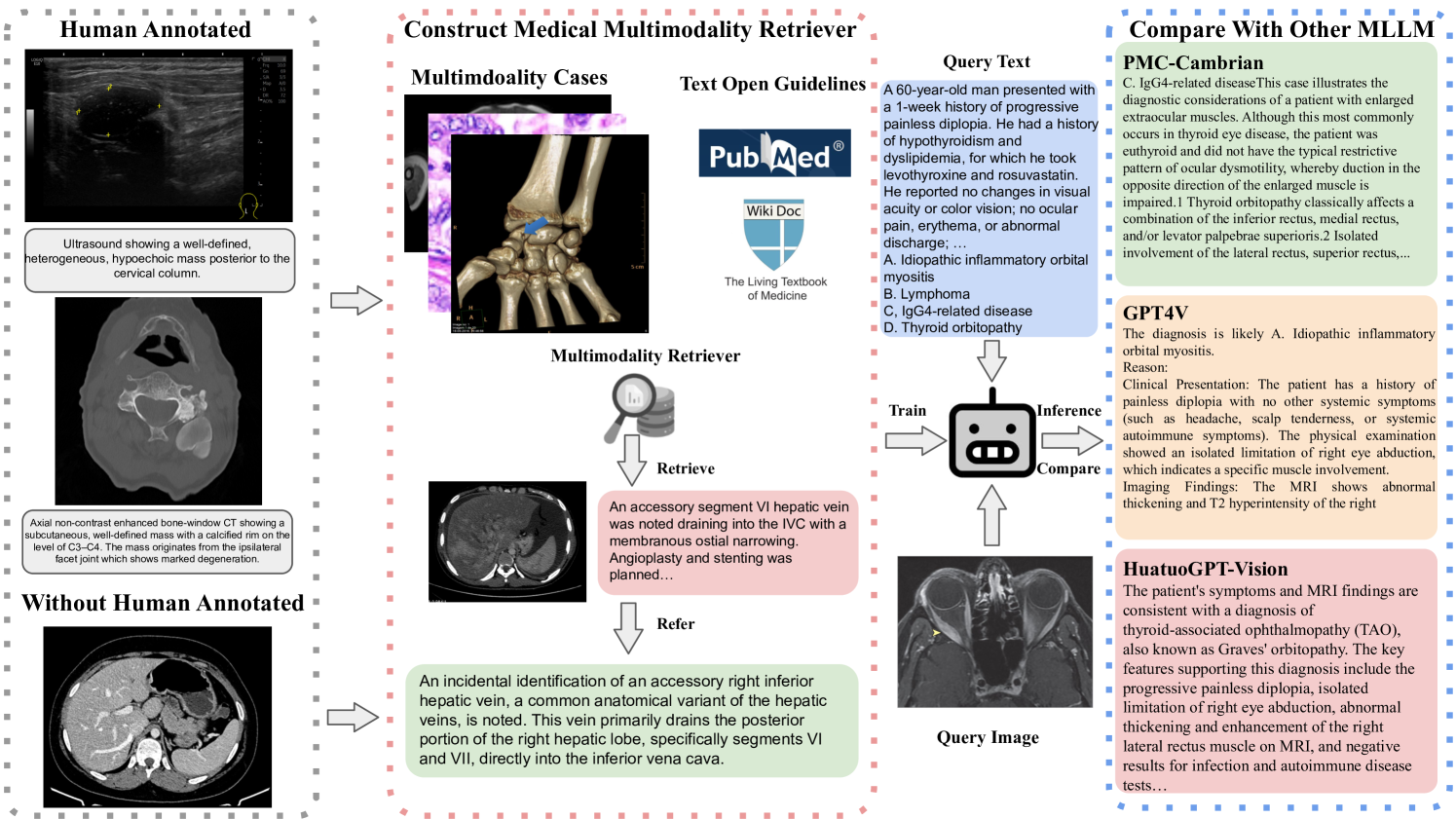
技术框架:整体框架包含三个主要阶段:1) 数据收集:构建SemiHVision数据集,结合人工标注和自动增强。2) 模型微调:使用SemiHVision数据集对PMC-Cambrian-8B进行指令微调,得到PMC-Cambrian-AN模型。3) 模型评估:在传统基准(SLAKE、VQA-RAD)和新基准(JAMA临床挑战)上评估模型性能。
关键创新:1) SemiHVision数据集:结合人工标注和自动增强,提高数据质量和多样性。2) JAMA临床挑战基准:更贴近真实临床场景,能够更准确地评估模型的诊断推理能力。3) 指令微调策略:通过精细设计的指令,引导模型学习医学知识和推理技巧。
关键设计:SemiHVision数据集包含多种医学图像和相应的诊断报告,人工标注部分由医学专家完成,自动增强部分采用数据增强技术,如图像旋转、缩放等。JAMA临床挑战基准包含真实的临床病例,需要模型进行诊断和给出治疗建议。PMC-Cambrian-8B-AN模型采用Transformer架构,使用交叉熵损失函数进行训练。
🖼️ 关键图片
📊 实验亮点
PMC-Cambrian-AN模型在SLAKE和VQA-RAD等传统基准测试中超越了HuatuoGPT-Vision-34B和Claude3-Opus等模型。在JAMA临床挑战基准上,PMC-Cambrian-AN取得了1.29的GPT-4评分,显著优于HuatuoGPT-Vision-34B(1.13)和Claude3-Opus(1.17),证明了其卓越的诊断推理能力。
🎯 应用场景
该研究成果可应用于辅助医生进行疾病诊断、制定治疗方案,提高医疗效率和准确性。未来,该模型有望应用于远程医疗、医学教育等领域,为医疗资源的普及和医疗水平的提升做出贡献。同时,相关技术也可推广到其他专业领域,例如法律、金融等。
📄 摘要(原文)
Multimodal large language models (MLLMs) have made significant strides, yet they face challenges in the medical domain due to limited specialized knowledge. While recent medical MLLMs demonstrate strong performance in lab settings, they often struggle in real-world applications, highlighting a substantial gap between research and practice. In this paper, we seek to address this gap at various stages of the end-to-end learning pipeline, including data collection, model fine-tuning, and evaluation. At the data collection stage, we introduce SemiHVision, a dataset that combines human annotations with automated augmentation techniques to improve both medical knowledge representation and diagnostic reasoning. For model fine-tuning, we trained PMC-Cambrian-8B-AN over 2400 H100 GPU hours, resulting in performance that surpasses public medical models like HuatuoGPT-Vision-34B (79.0% vs. 66.7%) and private general models like Claude3-Opus (55.7%) on traditional benchmarks such as SLAKE and VQA-RAD. In the evaluation phase, we observed that traditional benchmarks cannot accurately reflect realistic clinical task capabilities. To overcome this limitation and provide more targeted guidance for model evaluation, we introduce the JAMA Clinical Challenge, a novel benchmark specifically designed to evaluate diagnostic reasoning. On this benchmark, PMC-Cambrian-AN achieves state-of-the-art performance with a GPT-4 score of 1.29, significantly outperforming HuatuoGPT-Vision-34B (1.13) and Claude3-Opus (1.17), demonstrating its superior diagnostic reasoning abilities.