TreeBoN: Enhancing Inference-Time Alignment with Speculative Tree-Search and Best-of-N Sampling
作者: Jiahao Qiu, Yifu Lu, Yifan Zeng, Jiacheng Guo, Jiayi Geng, Chenhao Zhu, Xinzhe Juan, Ling Yang, Huazheng Wang, Kaixuan Huang, Yue Wu, Mengdi Wang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-10-18 (更新: 2025-09-03)
💡 一句话要点
TreeBoN:通过推断时投机树搜索和Best-of-N采样增强大语言模型对齐
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推断时对齐 Best-of-N采样 投机树搜索 直接偏好优化
📋 核心要点
- 现有Best-of-N采样方法计算成本高昂,难以在计算效率和输出质量之间取得平衡。
- TreeBoN通过引入投机树搜索策略,迭代分支和修剪低质量响应,降低计算开销。
- 实验结果表明,TreeBoN在多个数据集上优于标准BoN,并在TutorEval上取得了65%的最高胜率。
📝 摘要(中文)
推断时对齐能够提升大型语言模型的性能,而无需额外的训练或微调,但其挑战在于平衡计算效率和高质量输出。Best-of-N (BoN) 采样作为一种简单而强大的方法,通过生成多个响应并选择最佳响应来提高性能,但计算成本很高。我们提出了TreeBoN,这是一种将投机树搜索策略集成到Best-of-N (BoN) 采样中的新框架。TreeBoN维护一组父节点,迭代地分支和修剪低质量的响应,从而在保持高输出质量的同时降低计算开销。我们的方法还利用来自直接偏好优化 (DPO) 的token级别奖励来指导树的扩展和修剪低质量路径。我们在AlpacaFarm、HH-RLHF、UltraFeedback、GSM8K和TutorEval数据集上评估了TreeBoN,证明了一致的改进。具体而言,TreeBoN在TutorEval上实现了65%的最高胜率,并在其他不同数据集上实现了约60%的胜率,优于具有相同计算成本的标准BoN,并展示了其可扩展性和对齐有效性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在推断时对齐(Inference-time alignment)的问题。现有的Best-of-N (BoN)采样方法虽然能提升LLM的性能,但由于需要生成和评估多个响应,计算成本非常高,限制了其在实际应用中的可行性。因此,如何在保证输出质量的前提下,降低BoN采样的计算复杂度是本研究要解决的核心问题。
核心思路:TreeBoN的核心思路是将投机树搜索(Speculative Tree-Search)集成到BoN采样中。通过构建一个树结构,每个节点代表一个可能的响应序列,然后利用token级别的奖励(例如来自DPO)来指导树的扩展和修剪。这样,TreeBoN可以在搜索过程中尽早地排除低质量的响应路径,从而减少需要完整生成的响应数量,降低计算成本。
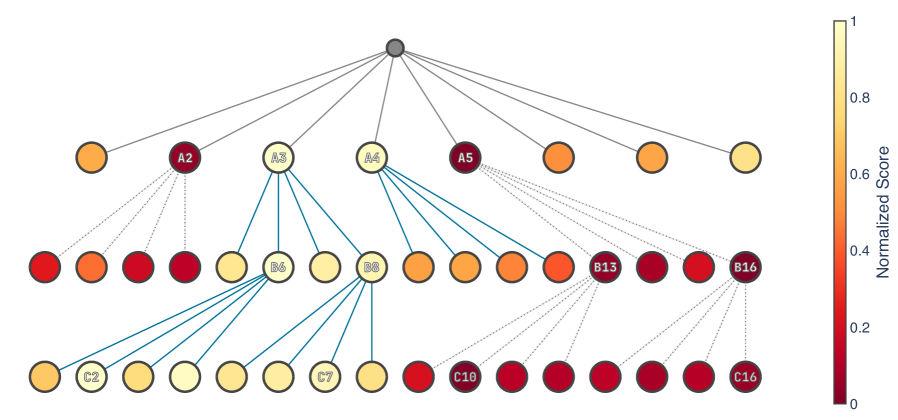
技术框架:TreeBoN的整体框架包括以下几个主要步骤: 1. 初始化:维护一组父节点,每个节点代表一个部分生成的响应序列。 2. 树扩展:对于每个父节点,根据LLM的概率分布生成多个子节点(即可能的下一个token)。 3. 奖励评估:使用token级别的奖励函数(例如来自DPO)评估每个子节点的质量。 4. 树修剪:根据奖励值,修剪掉低质量的子节点,只保留高质量的节点作为新的父节点。 5. 迭代:重复步骤2-4,直到达到预定的生成长度。 6. 选择最佳:在最终生成的响应序列中,选择奖励值最高的作为最终输出。
关键创新:TreeBoN的关键创新在于将投机树搜索与BoN采样相结合。与传统的BoN采样需要完整生成所有候选响应不同,TreeBoN通过树搜索的方式,可以在生成过程中尽早地排除低质量的响应路径,从而显著降低计算成本。此外,利用token级别的奖励函数来指导树的扩展和修剪,可以更有效地找到高质量的响应。
关键设计:TreeBoN的关键设计包括: 1. 奖励函数:使用来自DPO的token级别奖励作为评估响应质量的指标。具体如何将DPO的偏好信息转化为token级别的奖励,论文中应该有详细描述(未知)。 2. 树的宽度和深度:树的宽度决定了每个父节点生成多少个子节点,深度决定了搜索的长度。这两个参数需要根据具体的应用场景进行调整,以平衡计算成本和搜索效果。 3. 修剪策略:如何根据奖励值来修剪低质量的节点,例如可以设置一个阈值,只保留奖励值高于阈值的节点。
🖼️ 关键图片


📊 实验亮点
TreeBoN在AlpacaFarm、HH-RLHF、UltraFeedback、GSM8K和TutorEval等多个数据集上进行了评估,结果表明TreeBoN能够显著提升LLM的性能。特别是在TutorEval数据集上,TreeBoN取得了65%的最高胜率,并在其他数据集上取得了约60%的胜率,优于具有相同计算成本的标准BoN。这些实验结果充分证明了TreeBoN的有效性和优越性。
🎯 应用场景
TreeBoN具有广泛的应用前景,可以应用于各种需要高质量文本生成的场景,例如对话系统、文本摘要、机器翻译等。通过降低BoN采样的计算成本,TreeBoN使得在资源受限的环境下也能获得高质量的LLM输出,从而提升用户体验和应用效果。未来,TreeBoN还可以与其他技术相结合,例如知识图谱、强化学习等,进一步提升LLM的性能和应用范围。
📄 摘要(原文)
Inference-time alignment enhances the performance of large language models without requiring additional training or fine-tuning but presents challenges due to balancing computational efficiency with high-quality output. Best-of-N (BoN) sampling, as a simple yet powerful approach, generates multiple responses and selects the best one, achieving improved performance but with a high computational cost. We propose TreeBoN, a novel framework that integrates a speculative tree-search strategy into Best-of-N (BoN) Sampling. TreeBoN maintains a set of parent nodes, iteratively branching and pruning low-quality responses, thereby reducing computational overhead while maintaining high output quality. Our approach also leverages token-level rewards from Direct Preference Optimization (DPO) to guide tree expansion and prune low-quality paths. We evaluate TreeBoN using AlpacaFarm, HH-RLHF, UltraFeedback, GSM8K, and TutorEval datasets, demonstrating consistent improvements. Specifically, TreeBoN achieves the highest win rate of 65% on TutorEval and around 60% win rates across other different datasets, outperforming standard BoN with the same computational cost and showcasing its scalability and alignment efficacy.