MiCEval: Unveiling Multimodal Chain of Thought's Quality via Image Description and Reasoning Steps
作者: Xiongtao Zhou, Jie He, Lanyu Chen, Jingyu Li, Haojing Chen, Víctor Gutiérrez-Basulto, Jeff Z. Pan, Hanjie Chen
分类: cs.CL
发布日期: 2024-10-18 (更新: 2025-02-28)
备注: NAACL 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出MiCEval,通过图像描述和推理步骤评估多模态CoT的质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 思维链 模型评估 大型语言模型 图像理解
📋 核心要点
- 现有方法缺乏对多模态思维链(MCoT)中推理步骤质量的自动评估手段,限制了对MLLM推理过程的深入理解。
- MiCEval框架通过评估图像描述的准确性和每个推理步骤的质量,来判断推理链的正确性,从而实现对MCoT质量的评估。
- 实验表明,MiCEval的逐步评估结果与人类判断更吻合,优于基于余弦相似度或微调的现有方法。
📝 摘要(中文)
多模态思维链(MCoT)是一种流行的提示策略,用于提高多模态大型语言模型(MLLM)在一系列复杂推理任务中的性能。尽管它很受欢迎,但目前缺乏自动评估MCoT中推理步骤质量的方法。为了解决这个问题,我们提出了多模态思维链评估(MiCEval),该框架旨在通过评估描述和每个推理步骤的质量来评估推理链的正确性。描述组件的评估侧重于图像描述的准确性,而推理步骤评估则评估每个步骤的质量,因为它是在前一步骤的基础上条件生成的。MiCEval建立在一个细粒度的数据集之上,该数据集根据正确性、相关性和信息量对每个步骤进行注释。对四个最先进的MLLM进行的大量实验表明,与基于余弦相似度或微调方法的现有方法相比,使用MiCEval进行逐步评估更符合人类的判断。MiCEval数据集和代码可在https://github.com/alenai97/MiCEval中找到。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)中,对于使用多模态思维链(MCoT)进行推理时,缺乏有效评估推理步骤质量的自动化方法的问题。现有方法,如基于余弦相似度或微调的方法,无法准确反映推理过程的正确性、相关性和信息量,与人类判断存在偏差。
核心思路:MiCEval的核心思路是将MCoT的评估分解为对图像描述和每个推理步骤的细粒度评估。通过分别评估图像描述的准确性和每个推理步骤的质量(包括正确性、相关性和信息量),从而更全面、准确地评估整个推理链的质量。
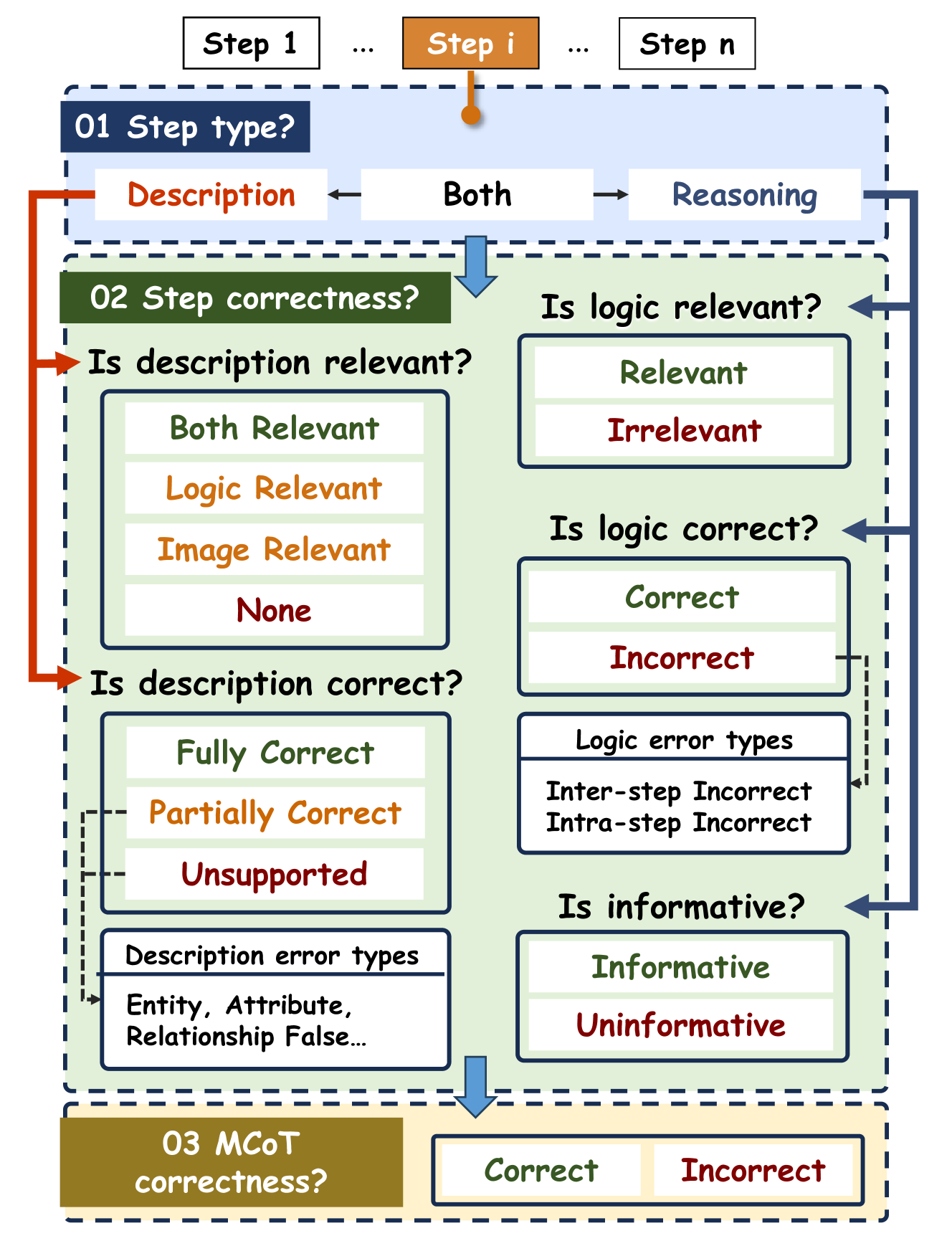
技术框架:MiCEval框架主要包含以下几个阶段:1) 输入:图像和相应的MCoT推理链;2) 图像描述评估:评估图像描述的准确性;3) 推理步骤评估:逐个评估推理链中的每个步骤,判断其正确性、相关性和信息量;4) 综合评估:综合图像描述评估和推理步骤评估的结果,给出对整个MCoT推理链质量的评估。该框架依赖于一个带有细粒度标注的数据集,该数据集对每个步骤的正确性、相关性和信息量进行了评分。
关键创新:MiCEval的关键创新在于其细粒度的评估方法,它将MCoT的评估分解为对图像描述和每个推理步骤的独立评估。这种方法能够更准确地捕捉推理过程中的错误和不足,从而提供更可靠的评估结果。与现有方法相比,MiCEval更注重对推理过程本身的理解,而非仅仅关注最终结果的正确性。
关键设计:MiCEval的关键设计包括:1) 细粒度标注数据集:该数据集是MiCEval的基础,提供了对每个推理步骤的正确性、相关性和信息量的详细标注;2) 评估指标:MiCEval使用一系列评估指标来衡量图像描述的准确性和推理步骤的质量,例如,可以使用BLEU或ROUGE等指标评估图像描述的准确性,并设计专门的指标来评估推理步骤的正确性、相关性和信息量;3) 评估流程:MiCEval采用逐步评估的流程,逐个评估推理链中的每个步骤,从而更准确地定位错误和不足。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MiCEval的逐步评估结果与人类判断的吻合度高于现有方法。具体来说,MiCEval在评估MLLM的推理链质量方面,与人类判断的相关性显著高于基于余弦相似度或微调的方法。这表明MiCEval能够更准确地反映MCoT的质量,为MLLM的改进提供更可靠的依据。
🎯 应用场景
MiCEval可应用于多模态大型语言模型的开发和评估,帮助研究人员和开发者更好地理解和改进模型的推理能力。它还可以用于自动评估MCoT的质量,从而提高模型在视觉问答、图像理解等任务中的性能。此外,该研究为构建更可靠、可解释的多模态AI系统奠定了基础。
📄 摘要(原文)
Multimodal Chain of Thought (MCoT) is a popular prompting strategy for improving the performance of multimodal large language models (MLLMs) across a range of complex reasoning tasks. Despite its popularity, there is a notable absence of automated methods for evaluating the quality of reasoning steps in MCoT. To address this gap, we propose Multimodal Chain-of-Thought Evaluation (MiCEval), a framework designed to assess the correctness of reasoning chains by evaluating the quality of both the description and each reasoning step. The evaluation of the description component focuses on the accuracy of the image descriptions, while the reasoning step evaluates the quality of each step as it is conditionally generated based on the preceding steps. MiCEval is built upon a fine-grained dataset with annotations that rate each step according to correctness, relevance, and informativeness. Extensive experiments on four state-of-the-art MLLMs show that step-wise evaluations using MiCEval align more closely with human judgments compared to existing methods based on cosine similarity or fine-tuning approaches. MiCEval datasets and code can be found in https://github.com/alenai97/MiCEval.