Large Language Models Are Overparameterized Text Encoders
作者: Thennal D K, Tim Fischer, Chris Biemann
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-10-18
备注: 8 pages of content + 1 for limitations and ethical considerations, 14 pages in total including references and appendix, 5+1 figures
💡 一句话要点
通过层剪枝,显著降低大语言模型文本编码的参数冗余,提升推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 文本嵌入 模型剪枝 参数冗余 监督对比学习
📋 核心要点
- 现有大语言模型作为文本嵌入模型时,参数量巨大,导致推理时间和内存需求高昂。
- 通过在监督训练前剪枝LLM的最后若干层,可以在基本不损失性能的前提下,显著降低模型大小。
- 实验表明,该方法能以极小的性能损失剪枝高达80%的层,并提出了基于初始损失的剪枝策略。
📝 摘要(中文)
大型语言模型(LLM)在经过监督对比训练微调后,作为文本嵌入模型表现出强大的性能。然而,它们庞大的规模增加了推理时间和内存需求。本文表明,在LLM进行监督训练之前,通过剪枝掉最后p%的层,只需1000步,就可以实现内存和推理时间的成比例减少。我们在文本嵌入任务上评估了四种不同的最先进的LLM,发现我们的方法可以剪枝高达30%的层,而对性能的影响可以忽略不计,剪枝高达80%的层,也只有适度的下降。我们的方法只需三行代码即可轻松地在任何将LLM转换为文本编码器的pipeline中实现。我们还提出了一种新的基于模型初始损失的层剪枝策略$ ext{L}^3 ext{Prune}$,它提供了两种最佳剪枝配置:一种具有可忽略的性能损失的大型变体,以及一种用于资源受限环境的小型变体。平均而言,大型变体剪枝了21%的参数,性能下降-0.3,而小型变体仅遭受-5.1的性能下降,同时剪枝了74%的模型。我们认为这些结果有力地证明了LLM对于文本嵌入任务来说是过度参数化的,并且可以很容易地进行剪枝。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在文本嵌入任务中过度参数化的问题。现有方法直接使用未经剪枝的LLM,导致推理速度慢、内存占用高,不适用于资源受限的场景。因此,如何有效降低LLM的参数量,同时保持其文本嵌入性能,是本文要解决的核心问题。
核心思路:论文的核心思路是在LLM用于文本嵌入任务之前,通过剪枝掉部分层来减少参数量。作者认为,LLM在文本嵌入任务中存在冗余,可以通过剪枝去除不重要的层,从而在不显著影响性能的前提下,降低模型大小和推理时间。
技术框架:该方法主要包含以下几个阶段:1) 选择预训练的LLM;2) 在监督对比训练之前,根据一定的策略(如随机剪枝或基于初始损失的剪枝)剪枝掉LLM的最后p%的层;3) 使用监督对比学习目标函数对剪枝后的LLM进行微调,使其适应文本嵌入任务;4) 评估剪枝后的LLM在文本嵌入任务上的性能。
关键创新:论文的关键创新在于提出了一种简单有效的LLM层剪枝方法,并提出了一种新的基于模型初始损失的层剪枝策略$ ext{L}^3 ext{Prune}$。该策略能够根据模型的初始损失,自动选择最佳的剪枝配置,从而在性能和模型大小之间取得平衡。与传统的剪枝方法相比,该方法更加高效,且易于实现。
关键设计:$ ext{L}^3 ext{Prune}$策略的关键设计在于利用模型的初始损失来评估每一层的重要性。具体来说,该策略计算每一层对模型初始损失的贡献,并根据贡献的大小来决定是否剪枝该层。此外,作者还探索了不同的剪枝比例p,并发现可以通过剪枝高达30%的层,而对性能的影响可以忽略不计,剪枝高达80%的层,也只有适度的下降。
🖼️ 关键图片
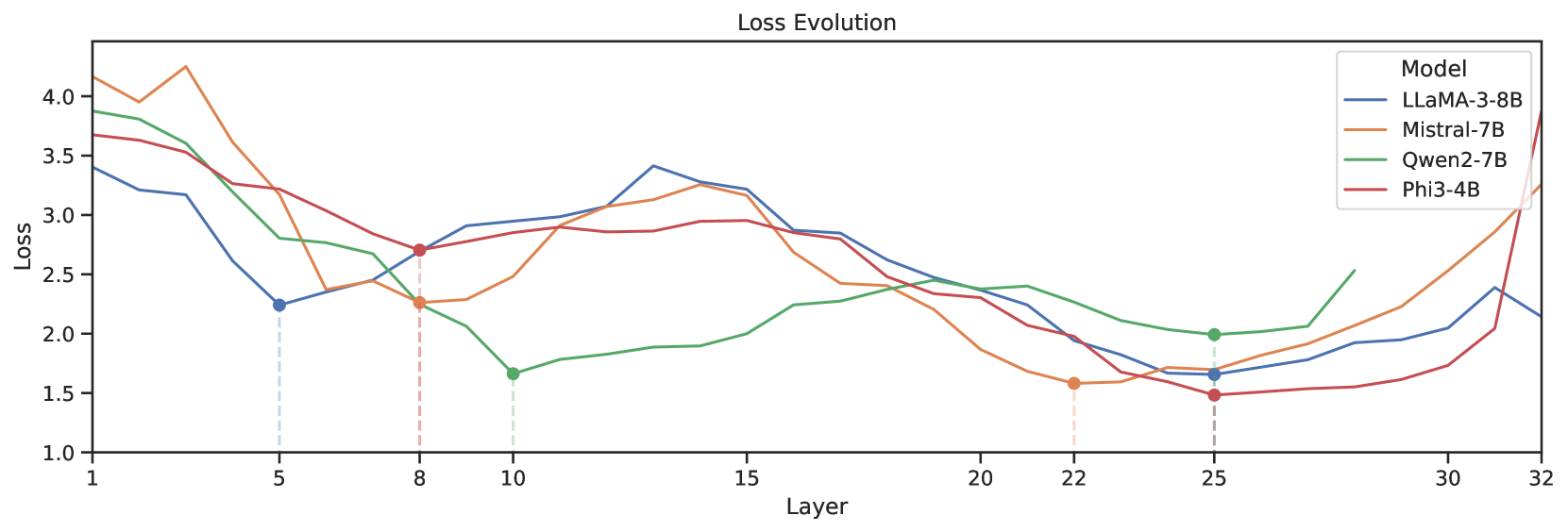


📊 实验亮点
实验结果表明,该方法可以在不显著影响性能的前提下,显著降低LLM的参数量。例如,通过$ ext{L}^3 ext{Prune}$策略,大型变体剪枝了21%的参数,性能仅下降-0.3,而小型变体仅遭受-5.1的性能下降,同时剪枝了74%的模型。这些结果表明,LLM在文本嵌入任务中存在显著的参数冗余,可以通过剪枝来提高效率。
🎯 应用场景
该研究成果可广泛应用于各种需要文本嵌入的场景,例如信息检索、文本分类、语义相似度计算等。通过降低LLM的参数量,可以将其部署在资源受限的设备上,例如移动设备或嵌入式系统。此外,该方法还可以加速LLM的推理速度,提高用户体验。
📄 摘要(原文)
Large language models (LLMs) demonstrate strong performance as text embedding models when finetuned with supervised contrastive training. However, their large size balloons inference time and memory requirements. In this paper, we show that by pruning the last $p\%$ layers of an LLM before supervised training for only 1000 steps, we can achieve a proportional reduction in memory and inference time. We evaluate four different state-of-the-art LLMs on text embedding tasks and find that our method can prune up to 30\% of layers with negligible impact on performance and up to 80\% with only a modest drop. With only three lines of code, our method is easily implemented in any pipeline for transforming LLMs to text encoders. We also propose $\text{L}^3 \text{Prune}$, a novel layer-pruning strategy based on the model's initial loss that provides two optimal pruning configurations: a large variant with negligible performance loss and a small variant for resource-constrained settings. On average, the large variant prunes 21\% of the parameters with a $-0.3$ performance drop, and the small variant only suffers from a $-5.1$ decrease while pruning 74\% of the model. We consider these results strong evidence that LLMs are overparameterized for text embedding tasks, and can be easily pruned.