How Do Multilingual Language Models Remember Facts?
作者: Constanza Fierro, Negar Foroutan, Desmond Elliott, Anders Søgaard
分类: cs.CL
发布日期: 2024-10-18 (更新: 2025-06-10)
备注: 9 pages
💡 一句话要点
揭示多语言LLM事实记忆机制:语言依赖与独立性分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言LLM 事实知识回忆 语言依赖性 函数向量 知识表示
📋 核心要点
- 现有研究主要集中在英语单语模型,忽略了多语言LLM如何存储和检索事实知识。
- 通过分析多语言LLM的中间表示,揭示了语言依赖和语言独立的知识回忆机制。
- 实验表明,主体信息增强是语言独立的,而客体信息提取是语言相关的,并发现了函数向量(FV)的作用。
📝 摘要(中文)
大型语言模型(LLMs)在预训练期间存储并检索大量事实知识。先前的研究已经定位并识别了知识回忆背后的机制,但仅关注于英语单语模型。这些机制如何推广到非英语语言和多语言LLM仍然未知。本文通过对三个多语言LLM进行全面分析来解决这一差距。首先,我们表明先前在英语中识别的回忆机制在很大程度上适用于多语言环境,但存在基于语言和架构的细微差别。接下来,通过修补中间表示,我们定位了语言在回忆过程中的作用,发现主体信息增强是语言独立的,而客体信息提取是语言相关的。此外,我们发现最后一个token的表示充当函数向量(FV),编码查询的语言和要从主体中提取的内容。此外,在仅解码器LLM中,FV分两个阶段组合这两部分信息。这些见解揭示了多语言LLM中用于回忆信息的独特机制,突出了对专门为多语言LLM量身定制的新方法(例如知识评估、事实编辑和知识获取)的需求。
🔬 方法详解
问题定义:现有研究主要关注英语单语LLM的事实知识回忆机制,缺乏对多语言LLM的深入理解。多语言LLM如何处理不同语言的事实知识,以及不同语言之间是否存在共享或独立的知识表示,这些问题尚未得到充分解答。现有方法难以直接应用于多语言场景,需要针对多语言特性进行调整和改进。
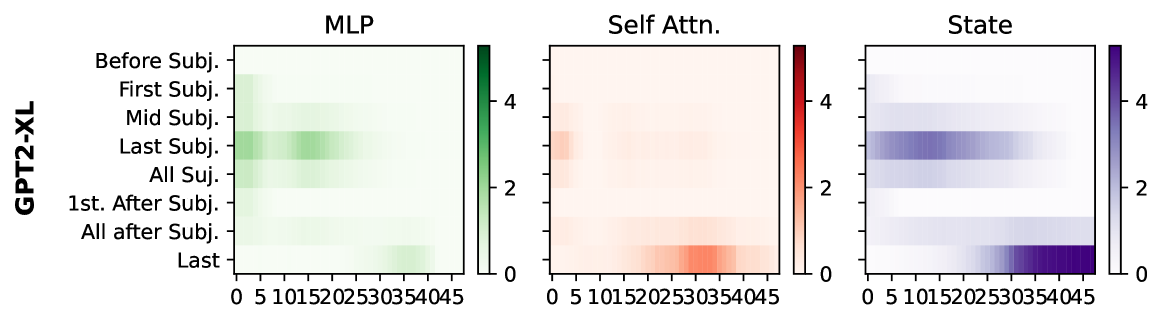
核心思路:本文的核心思路是通过分析多语言LLM的中间表示,来揭示其事实知识回忆机制。具体而言,通过“修补”(patching)中间表示,观察模型在不同语言下的表现差异,从而区分语言依赖和语言独立的知识回忆过程。此外,通过分析最后一个token的表示(函数向量FV),理解其如何编码查询的语言和要提取的内容。
技术框架:本文的研究框架主要包括以下几个步骤:1) 选择三个多语言LLM作为研究对象;2) 设计实验来评估模型在不同语言下的事实知识回忆能力;3) 使用“修补”技术,修改模型的中间表示,观察对回忆结果的影响,从而定位语言在回忆过程中的作用;4) 分析最后一个token的表示(FV),理解其编码的信息;5) 对比不同语言和架构的模型,总结多语言LLM事实知识回忆的共性和差异。
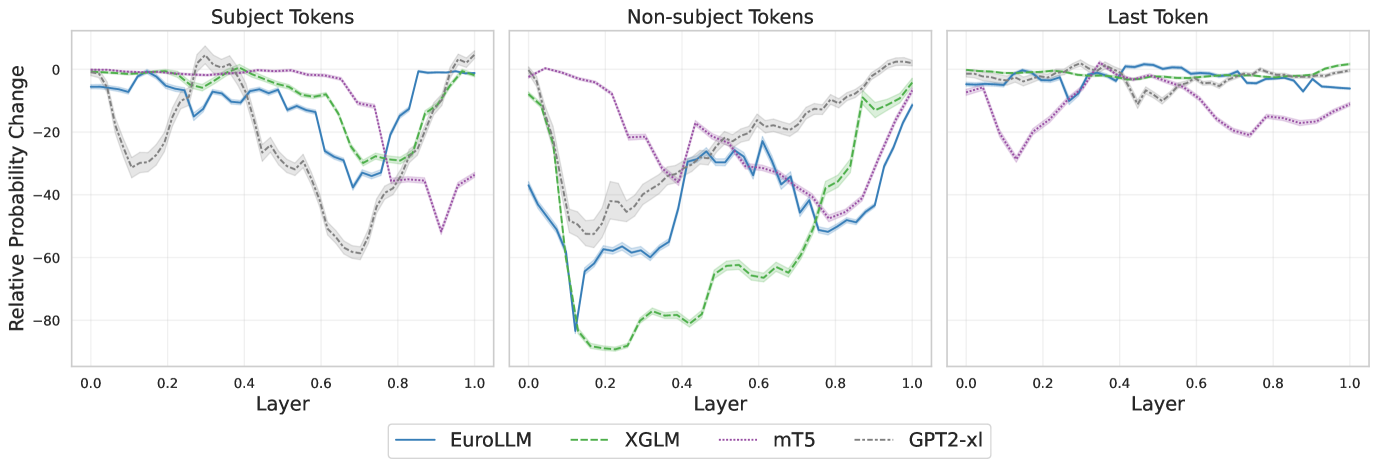
关键创新:本文最重要的技术创新点在于揭示了多语言LLM中语言依赖和语言独立的知识回忆机制。具体而言,发现主体信息增强是语言独立的,而客体信息提取是语言相关的。此外,发现了最后一个token的表示(FV)在编码查询语言和提取内容方面的作用,并揭示了在decoder-only LLM中,FV分两个阶段组合这些信息。
关键设计:本文的关键设计包括:1) 使用“修补”技术来修改模型的中间表示,通过观察对回忆结果的影响来定位语言的作用;2) 设计实验来评估模型在不同语言下的事实知识回忆能力,并对比不同语言和架构的模型;3) 分析最后一个token的表示(FV),使用聚类等方法来理解其编码的信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,先前在英语中识别的回忆机制在很大程度上适用于多语言环境,但存在基于语言和架构的细微差别。主体信息增强是语言独立的,而客体信息提取是语言相关的。最后一个token的表示充当函数向量(FV),编码查询的语言和要从主体中提取的内容。在decoder-only LLM中,FV分两个阶段组合这些信息。
🎯 应用场景
该研究成果可应用于提升多语言LLM的知识编辑能力,例如,针对特定语言的事实错误进行修正,而不会影响其他语言的知识。此外,该研究有助于开发更有效的多语言知识获取方法,以及设计更鲁棒的多语言知识评估指标。未来,可以进一步探索如何利用这些发现来构建更强大的多语言LLM。
📄 摘要(原文)
Large Language Models (LLMs) store and retrieve vast amounts of factual knowledge acquired during pre-training. Prior research has localized and identified mechanisms behind knowledge recall; however, it has only focused on English monolingual models. The question of how these mechanisms generalize to non-English languages and multilingual LLMs remains unexplored. In this paper, we address this gap by conducting a comprehensive analysis of three multilingual LLMs. First, we show that previously identified recall mechanisms in English largely apply to multilingual contexts, with nuances based on language and architecture. Next, through patching intermediate representations, we localize the role of language during recall, finding that subject enrichment is language-independent, while object extraction is language-dependent. Additionally, we discover that the last token representation acts as a Function Vector (FV), encoding both the language of the query and the content to be extracted from the subject. Furthermore, in decoder-only LLMs, FVs compose these two pieces of information in two separate stages. These insights reveal unique mechanisms in multilingual LLMs for recalling information, highlighting the need for new methodologies -- such as knowledge evaluation, fact editing, and knowledge acquisition -- that are specifically tailored for multilingual LLMs.