REEF: Representation Encoding Fingerprints for Large Language Models
作者: Jie Zhang, Dongrui Liu, Chen Qian, Linfeng Zhang, Yong Liu, Yu Qiao, Jing Shao
分类: cs.CL, cs.AI, cs.CR
发布日期: 2024-10-18
🔗 代码/项目: GITHUB
💡 一句话要点
提出REEF:一种免训练的大语言模型表征编码指纹方法,用于知识产权保护。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识产权保护 特征表示 模型指纹 免训练
📋 核心要点
- 开源LLM的知识产权保护至关重要,但现有方法难以在不损害模型性能的前提下进行有效鉴别。
- REEF通过比较嫌疑模型和受害模型在相同样本上的特征表示相似度,无需训练即可识别模型关系。
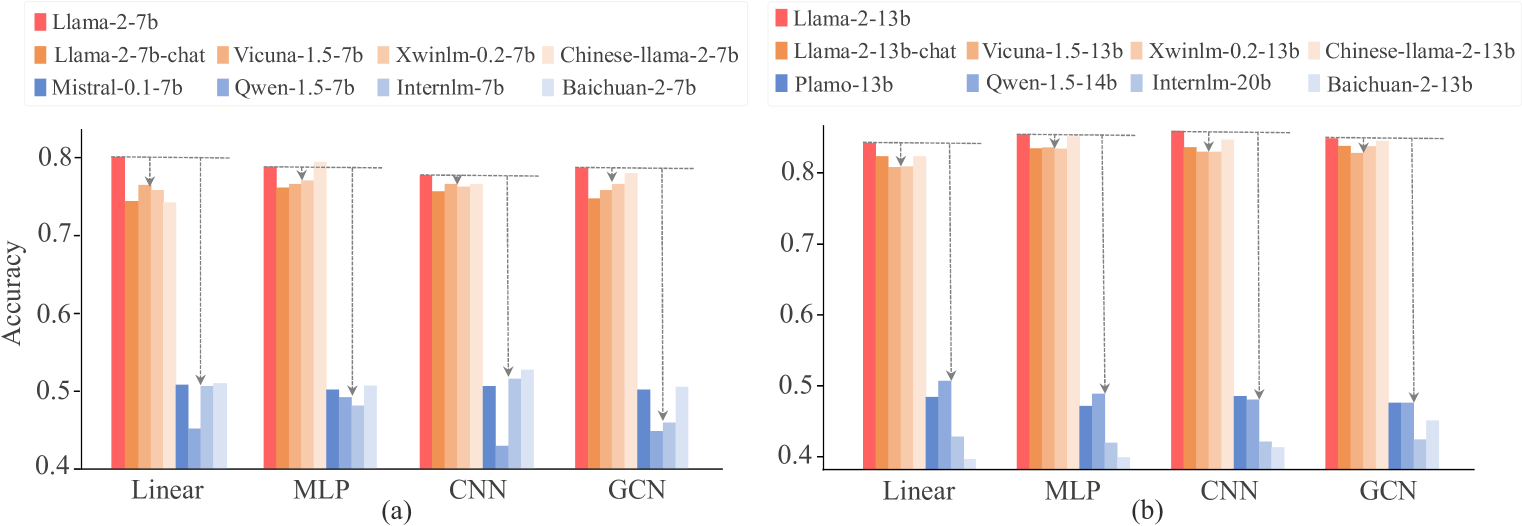
- 实验表明,REEF对微调、剪枝、模型合并和置换等操作具有鲁棒性,能有效保护LLM的知识产权。
📝 摘要(中文)
为了保护开源大语言模型(LLM)的知识产权,本文提出了一种免训练的REEF方法,用于识别嫌疑模型是否为受害模型的后续开发成果。训练LLM需要大量的计算资源和数据,因此模型所有者和第三方需要能够鉴别潜在的侵权行为。REEF从LLM的特征表示角度出发,通过计算和比较嫌疑模型和受害模型在相同样本上的中心核对齐相似度来判断二者关系。这种免训练的REEF方法不会损害模型的通用能力,并且对连续微调、剪枝、模型合并和置换具有鲁棒性。REEF为第三方和模型所有者共同保护LLM的知识产权提供了一种简单有效的方法。代码已开源。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)的知识产权保护问题。由于训练LLM成本高昂,需要一种有效的方法来识别潜在的侵权模型,即判断一个嫌疑模型是否是基于某个受害模型进行后续开发的。现有方法可能需要额外的训练或修改模型结构,从而影响模型的通用性能,或者对某些攻击手段(如微调、剪枝等)的鲁棒性不足。
核心思路:REEF的核心思路是利用LLM的特征表示来判断模型之间的关系。如果一个模型是基于另一个模型进行开发的,那么它们在处理相同输入时,其内部的特征表示应该具有一定的相似性。通过比较嫌疑模型和受害模型在相同输入上的特征表示相似度,可以推断它们之间的关系。这种方法无需训练,避免了对模型性能的损害。
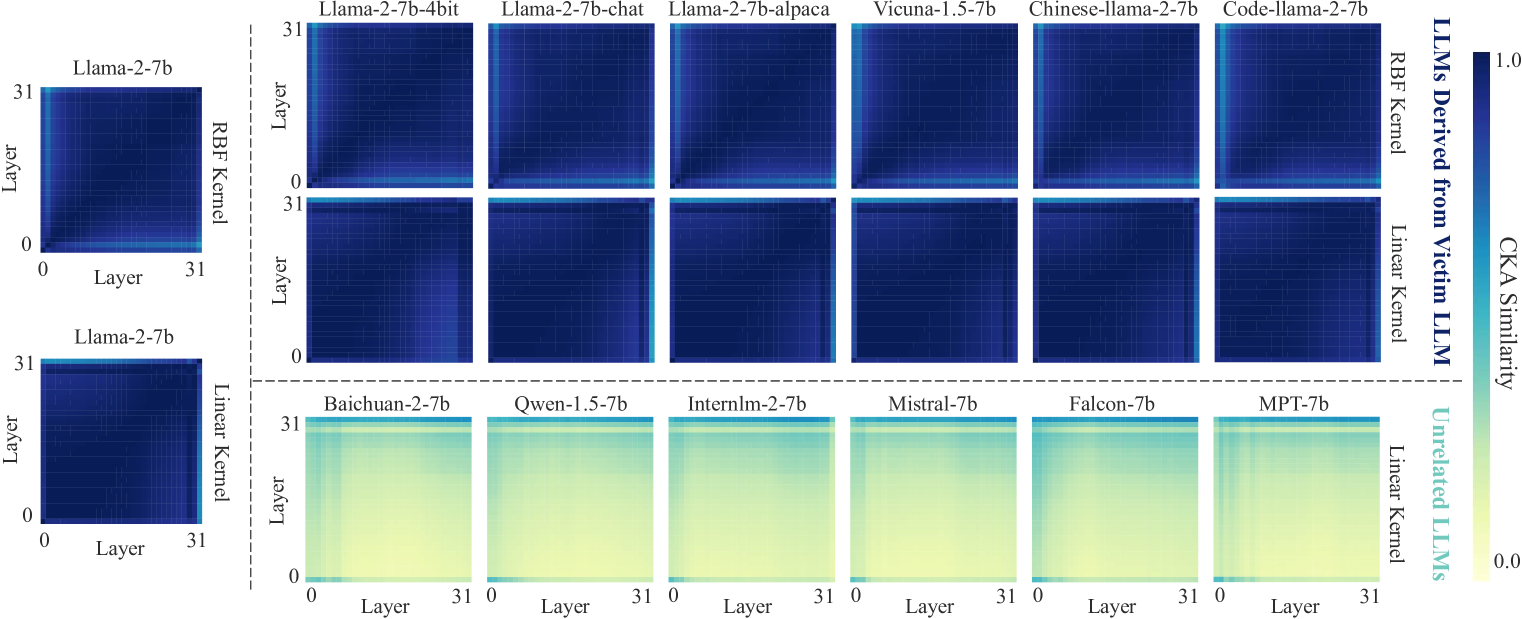
技术框架:REEF的整体框架非常简洁。首先,选取一批样本作为输入。然后,将这些样本分别输入到嫌疑模型和受害模型中,提取它们在特定层的特征表示。接着,计算这两个特征表示之间的中心核对齐(Centered Kernel Alignment, CKA)相似度。最后,根据CKA相似度的值来判断两个模型之间的关系。如果CKA相似度较高,则认为嫌疑模型很可能是基于受害模型开发的。
关键创新:REEF的关键创新在于利用了LLM的特征表示来进行知识产权保护,并且提出了一种免训练的方法。与需要额外训练或修改模型结构的方法相比,REEF更加简单高效,并且不会影响模型的通用性能。此外,REEF对微调、剪枝、模型合并和置换等攻击手段具有鲁棒性,能够有效应对各种潜在的侵权行为。
关键设计:REEF的关键设计包括:1) 选择合适的特征表示层:论文可能探索了不同层的特征表示对结果的影响,并选择了最具有区分性的层。2) 使用中心核对齐(CKA)作为相似度度量:CKA能够有效地衡量两个特征表示之间的相似性,并且对特征表示的尺度和偏移不敏感。3) 设定合理的相似度阈值:根据实验结果,设定一个合适的CKA相似度阈值,用于判断两个模型之间的关系。
🖼️ 关键图片

📊 实验亮点
REEF在多种攻击场景下表现出良好的鲁棒性,包括微调、剪枝、模型合并和置换等。实验结果表明,即使在这些攻击手段下,REEF仍然能够准确地识别出嫌疑模型与受害模型之间的关系,证明了其在知识产权保护方面的有效性。
🎯 应用场景
REEF可应用于开源LLM的知识产权保护,帮助模型所有者和第三方机构识别潜在的侵权行为。例如,模型开发者可以使用REEF来验证其模型是否被他人非法使用或修改。此外,REEF还可以用于评估不同模型之间的相似性,从而促进模型共享和合作。
📄 摘要(原文)
Protecting the intellectual property of open-source Large Language Models (LLMs) is very important, because training LLMs costs extensive computational resources and data. Therefore, model owners and third parties need to identify whether a suspect model is a subsequent development of the victim model. To this end, we propose a training-free REEF to identify the relationship between the suspect and victim models from the perspective of LLMs' feature representations. Specifically, REEF computes and compares the centered kernel alignment similarity between the representations of a suspect model and a victim model on the same samples. This training-free REEF does not impair the model's general capabilities and is robust to sequential fine-tuning, pruning, model merging, and permutations. In this way, REEF provides a simple and effective way for third parties and models' owners to protect LLMs' intellectual property together. The code is available at https://github.com/tmylla/REEF.