Semi-supervised Fine-tuning for Large Language Models
作者: Junyu Luo, Xiao Luo, Xiusi Chen, Zhiping Xiao, Wei Ju, Ming Zhang
分类: cs.CL, cs.AI
发布日期: 2024-10-17 (更新: 2025-02-19)
备注: Github Repo: https://github.com/luo-junyu/SemiEvol
期刊: NAACL 2025
💡 一句话要点
提出SemiEvol框架,通过半监督微调提升大语言模型在有限标注数据下的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 半监督学习 大语言模型 微调 知识传播 协同学习
📋 核心要点
- 监督微调依赖大量标注数据,但在实际应用中,标注数据往往稀缺,限制了大语言模型的性能。
- SemiEvol框架通过双层知识传播和协同学习机制,有效利用标注和未标注数据,提升模型性能。
- 实验结果表明,SemiEvol在多个数据集上显著优于传统监督微调和自进化方法,具有实际应用价值。
📝 摘要(中文)
监督微调(SFT)对于将大型语言模型(LLM)适配到特定领域或任务至关重要。然而,在实际应用中,可用的标注数据量有限,这对SFT产生令人满意的结果构成了严峻挑战。因此,非常需要一种能够充分利用标注和未标注数据进行LLM微调的数据高效框架。为此,我们引入了一种半监督微调(SemiFT)任务和一个名为SemiEvol的框架,该框架以一种传播和选择的方式进行LLM对齐。在知识传播方面,SemiEvol采用双层方法,通过模型权重和上下文两种方式将知识从标注数据传播到未标注数据。在知识选择方面,SemiEvol结合了一种协同学习机制,选择更高质量的伪响应样本。我们使用GPT-4o-mini和Llama-3.1在七个通用或特定领域的数据集上进行了实验,证明了模型在目标数据上的性能得到了显著提高。此外,我们将SemiEvol与SFT和自进化方法进行了比较,突出了其在混合数据场景中的实用性。
🔬 方法详解
问题定义:论文旨在解决在标注数据有限的情况下,如何有效微调大型语言模型(LLM)的问题。现有监督微调(SFT)方法严重依赖大量高质量的标注数据,当标注数据不足时,模型性能会显著下降。因此,如何利用未标注数据来辅助LLM微调,提高模型在目标任务上的泛化能力,是本文要解决的核心问题。
核心思路:SemiEvol的核心思路是利用半监督学习的思想,通过知识传播和知识选择两个阶段,将标注数据中的知识传递到未标注数据中,并从中选择高质量的伪标签数据进行训练。这种方法旨在充分利用未标注数据的信息,弥补标注数据不足的缺陷,从而提升LLM的微调效果。
技术框架:SemiEvol框架主要包含两个阶段:知识传播和知识选择。在知识传播阶段,采用双层方法,包括基于模型权重的知识传播和基于上下文的知识传播。基于模型权重的知识传播是指使用标注数据微调后的模型直接对未标注数据进行预测,生成伪标签。基于上下文的知识传播是指利用上下文学习(In-Context Learning)的方式,将标注数据作为提示,引导模型生成未标注数据的伪标签。在知识选择阶段,采用协同学习机制,使用多个模型对未标注数据进行预测,选择多个模型预测一致性高的样本作为高质量的伪标签数据。
关键创新:SemiEvol的关键创新在于其双层知识传播和协同学习机制。双层知识传播能够更全面地利用标注数据中的知识,提高伪标签的质量。协同学习机制能够有效地筛选出高质量的伪标签数据,避免噪声数据对模型训练产生负面影响。与传统的半监督学习方法不同,SemiEvol更注重利用LLM自身的强大能力,通过上下文学习等方式来生成伪标签。
关键设计:在知识传播阶段,论文采用了两种不同的方法来生成伪标签,分别是基于模型权重的预测和基于上下文学习的预测。在知识选择阶段,论文使用了多个模型进行协同学习,并采用一致性度量来选择高质量的伪标签数据。具体的参数设置和损失函数等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片


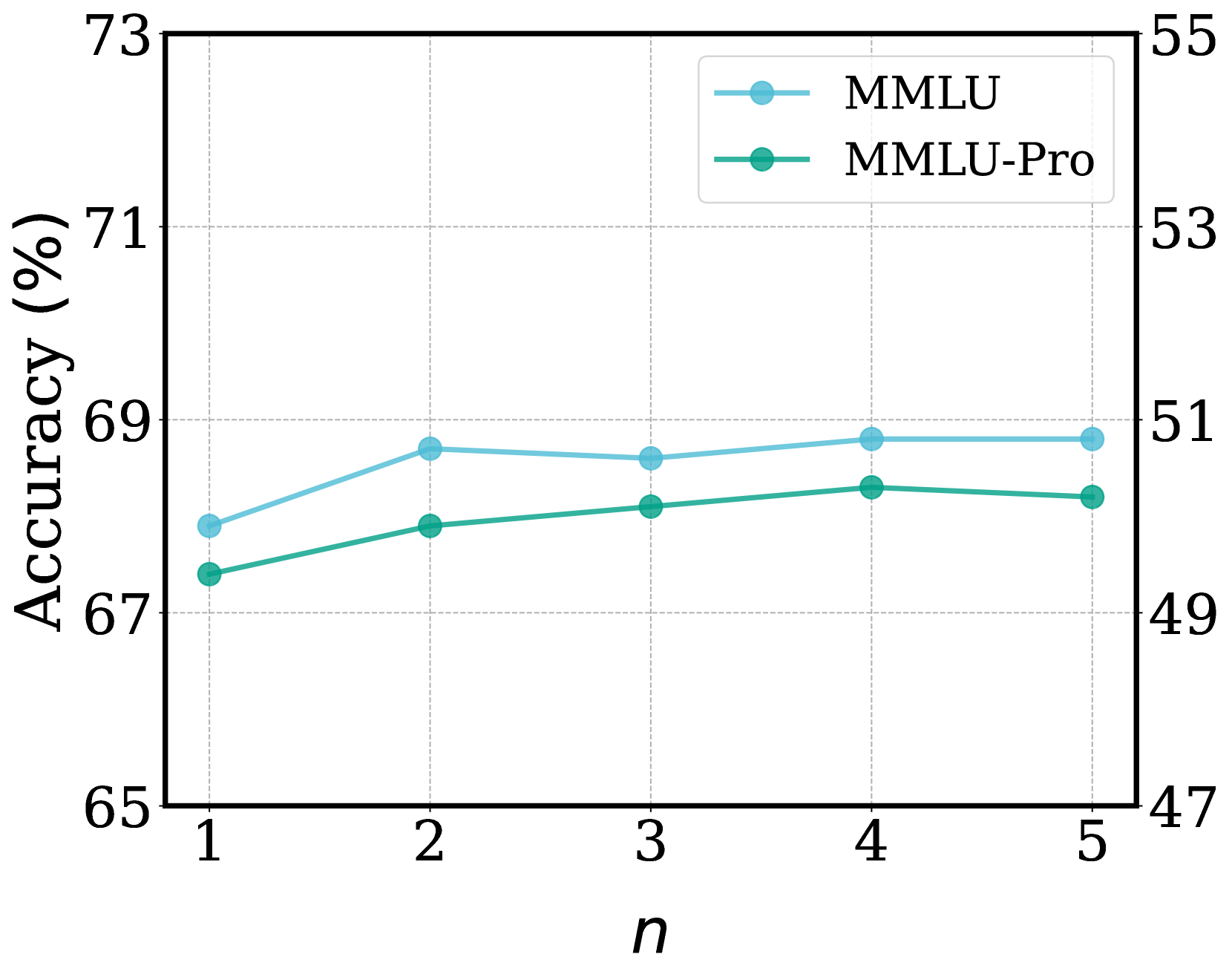
📊 实验亮点
实验结果表明,SemiEvol在七个通用或特定领域的数据集上显著优于传统的监督微调(SFT)和自进化方法。具体性能提升数据未在摘要中给出,属于未知信息。但结论表明,SemiEvol能够有效利用未标注数据,提升模型在目标数据上的性能,尤其是在标注数据有限的情况下。
🎯 应用场景
SemiEvol框架可广泛应用于各种需要对LLM进行微调的场景,尤其是在标注数据稀缺的领域,如医疗、金融、法律等。该方法能够有效提升模型在特定领域的性能,降低对大量标注数据的依赖,具有重要的实际应用价值。未来,该方法可以进一步扩展到多模态数据和更复杂的任务中。
📄 摘要(原文)
Supervised fine-tuning (SFT) is crucial in adapting large language model (LLMs) to a specific domain or task. However, only a limited amount of labeled data is available in practical applications, which poses a severe challenge for SFT in yielding satisfactory results. Therefore, a data-efficient framework that can fully exploit labeled and unlabeled data for LLM fine-tuning is highly anticipated.Towards this end, we introduce a semi-supervised fine-tuning(SemiFT) task and a framework named SemiEvol for LLM alignment from a propagate-and-select manner. For knowledge propagation, SemiEvol adopts a bi-level approach, propagating knowledge from labeled data to unlabeled data through both in-weight and in-context methods. For knowledge selection, SemiEvol incorporates a collaborative learning mechanism, selecting higher-quality pseudo-response samples. We conducted experiments using GPT-4o-mini and Llama-3.1 on seven general or domain-specific datasets, demonstrating significant improvements in model performance on target data. Furthermore, we compared SemiEvol with SFT and self-evolution methods, highlighting its practicality in hybrid data scenarios.