Learning Multimodal Cues of Children's Uncertainty
作者: Qi Cheng, Mert İnan, Rahma Mbarki, Grace Grmek, Theresa Choi, Yiming Sun, Kimele Persaud, Jenny Wang, Malihe Alikhani
分类: cs.CL, cs.CV, cs.CY, cs.HC
发布日期: 2024-10-17
备注: SIGDIAL 2023
💡 一句话要点
构建儿童不确定性多模态线索数据集,并提出模型预测儿童不确定性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 儿童不确定性 多模态学习 人机交互 认知协调 数据集构建
📋 核心要点
- 现有的AI系统在理解用户不确定性方面存在不足,尤其是在儿童交互场景下,缺乏相关数据和模型。
- 本文构建了一个新的多模态数据集,标注了儿童在任务中的不确定性线索,并分析了不确定性与任务难度和表现的关系。
- 提出了一个多模态机器学习模型,利用实时视频片段预测儿童的不确定性,并在实验中验证了其有效性。
📝 摘要(中文)
理解不确定性在达成共识中起着关键作用,这对于与用户协作解决问题或引导用户理解复杂概念的多模态AI系统尤为重要。本文首次提出了一个与发展心理学和认知心理学家合作标注的数据集,用于研究不确定性的非语言线索。随后,分析了数据,研究了不确定性的不同作用及其与任务难度和表现的关系。最后,提出了一个多模态机器学习模型,该模型可以根据参与者的实时视频片段预测不确定性,并且发现该模型优于基线多模态Transformer模型。这项工作为人类与人类以及人类与AI之间的认知协调研究提供了信息,并对姿势理解和生成具有广泛的影响。数据集和代码将在完成必要的同意书和数据表后公开。
🔬 方法详解
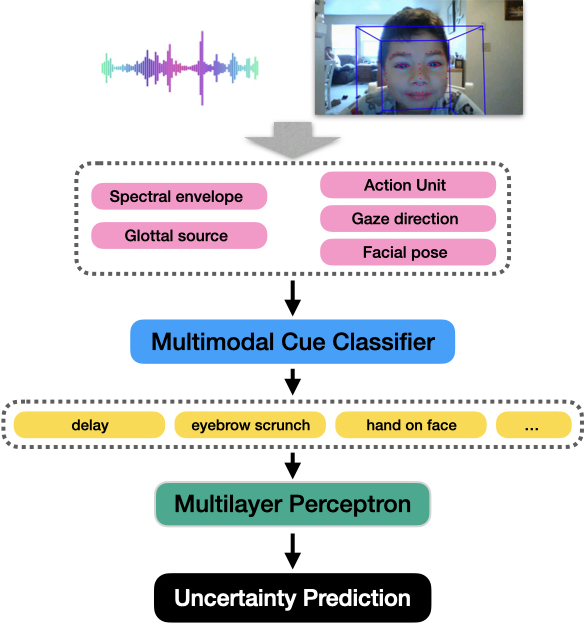
问题定义:论文旨在解决AI系统难以理解儿童在交互过程中的不确定性表达的问题。现有的方法缺乏针对儿童不确定性表达的数据集,并且模型无法有效利用多模态信息(如面部表情、肢体动作等)来准确预测儿童的不确定性状态。
核心思路:论文的核心思路是通过构建一个包含儿童不确定性表达的多模态数据集,并设计一个能够有效融合多模态信息的机器学习模型,从而提高AI系统对儿童不确定性的理解能力。通过分析数据集,可以深入了解不确定性与任务难度和表现之间的关系,为模型设计提供指导。
技术框架:整体框架包括数据收集与标注、数据分析和模型构建三个主要阶段。首先,收集儿童在完成特定任务时的视频数据,并与心理学家合作进行不确定性标注。然后,对标注数据进行分析,研究不确定性的不同类型及其与任务难度和表现的关系。最后,基于分析结果,构建一个多模态机器学习模型,该模型以实时视频片段作为输入,预测儿童的不确定性状态。
关键创新:论文的关键创新在于:1) 首次构建了一个专门针对儿童不确定性表达的多模态数据集,为相关研究提供了宝贵的数据资源。2) 提出了一个能够有效融合多模态信息的机器学习模型,提高了不确定性预测的准确率。3) 深入分析了不确定性与任务难度和表现之间的关系,为模型设计和应用提供了理论依据。
关键设计:论文提出的多模态模型可能采用了Transformer架构,并针对儿童不确定性表达的特点进行了优化。具体的网络结构、损失函数和训练策略等技术细节在摘要中未提及,属于未知信息。数据集标注的具体方法(例如,标注的类别、标注人员的培训等)也属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文提出了一个多模态机器学习模型,用于预测儿童的不确定性。实验结果表明,该模型优于基线多模态Transformer模型,但具体的性能数据和提升幅度在摘要中未提及,属于未知信息。该模型能够有效利用视频片段中的多模态信息,提高不确定性预测的准确率。
🎯 应用场景
该研究成果可应用于教育、儿童心理学、人机交互等领域。例如,可以开发智能辅导系统,根据儿童的不确定性表达,提供个性化的学习指导。此外,该研究还可以帮助开发更自然、更具同理心的人机交互界面,提升用户体验。未来,该研究有望促进人机协作在儿童教育和心理健康领域的应用。
📄 摘要(原文)
Understanding uncertainty plays a critical role in achieving common ground (Clark et al.,1983). This is especially important for multimodal AI systems that collaborate with users to solve a problem or guide the user through a challenging concept. In this work, for the first time, we present a dataset annotated in collaboration with developmental and cognitive psychologists for the purpose of studying nonverbal cues of uncertainty. We then present an analysis of the data, studying different roles of uncertainty and its relationship with task difficulty and performance. Lastly, we present a multimodal machine learning model that can predict uncertainty given a real-time video clip of a participant, which we find improves upon a baseline multimodal transformer model. This work informs research on cognitive coordination between human-human and human-AI and has broad implications for gesture understanding and generation. The anonymized version of our data and code will be publicly available upon the completion of the required consent forms and data sheets.