Learning Metadata-Agnostic Representations for Text-to-SQL In-Context Example Selection
作者: Chuhong Mai, Ro-ee Tal, Thahir Mohamed
分类: cs.CL
发布日期: 2024-10-17
备注: Accepted to NeurIPS 2024 Table Representation Learning workshop
💡 一句话要点
提出MARLO,用于文本到SQL的上下文学习示例选择,提升泛化能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到SQL 上下文学习 元数据无关 表示学习 查询结构
📋 核心要点
- 现有文本到SQL的上下文学习方法依赖于通用嵌入,难以捕捉任务特定信息,导致示例选择次优。
- MARLO通过对自然语言问题和SQL查询进行对齐表示学习,利用查询结构建模查询意图,避免过度依赖数据库元数据。
- 实验表明,MARLO在Spider基准测试中优于通用嵌入模型和其他元数据掩码方法,提高了执行准确率并降低了推理延迟。
📝 摘要(中文)
本文提出了一种用于文本到SQL上下文学习(ICL)的元数据无关表示学习方法MARLO。ICL是一种强大的范式,大型语言模型(LLM)可以通过添加到提示中的任务演示获益。然而,选择最佳演示并非易事,特别是对于输入和输出分布不同的复杂或多模态任务。我们假设形成输入的特定任务表示是关键。MARLO使用查询结构来建模查询意图,而不过度索引底层数据库元数据(即问题或查询中引用的数据库的表、列或特定于领域的实体)。这使得MARLO能够选择在结构和语义上与任务相关的示例,而不是与特定领域或问题措辞虚假相关的示例。在基于问题相似性检索示例时,MARLO在Spider基准测试中表现出优于通用嵌入模型的性能(平均执行准确率提高+2.9个百分点)。它也优于下一个最佳的元数据信息掩码方法,平均执行准确率提高+0.8个百分点,同时显著降低了推理延迟。
🔬 方法详解
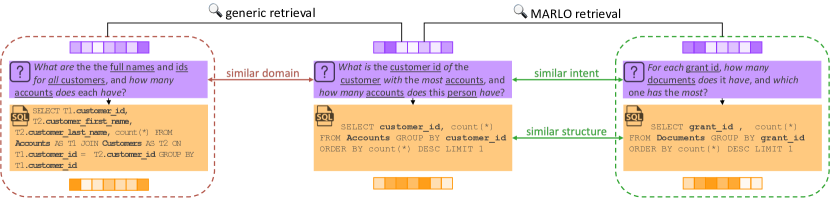
问题定义:现有文本到SQL的上下文学习方法在选择示例时,容易受到数据库元数据(如表名、列名)的影响,导致选择的示例与目标问题在结构和语义上不相关。现有方法要么依赖于通用嵌入,无法捕捉任务特定信息,要么简单地掩盖元数据,但效果有限且会增加推理延迟。因此,需要一种能够学习元数据无关的、任务特定表示的方法,以提高示例选择的准确性和效率。
核心思路:MARLO的核心思路是学习一种共享的嵌入空间,在该空间中,自然语言问题和SQL查询的表示能够对齐。为了实现这一点,MARLO利用SQL查询的结构来建模查询意图,同时避免过度依赖数据库元数据。通过这种方式,MARLO能够选择在结构和语义上与任务相关的示例,而不是仅仅因为共享某些元数据而相关的示例。
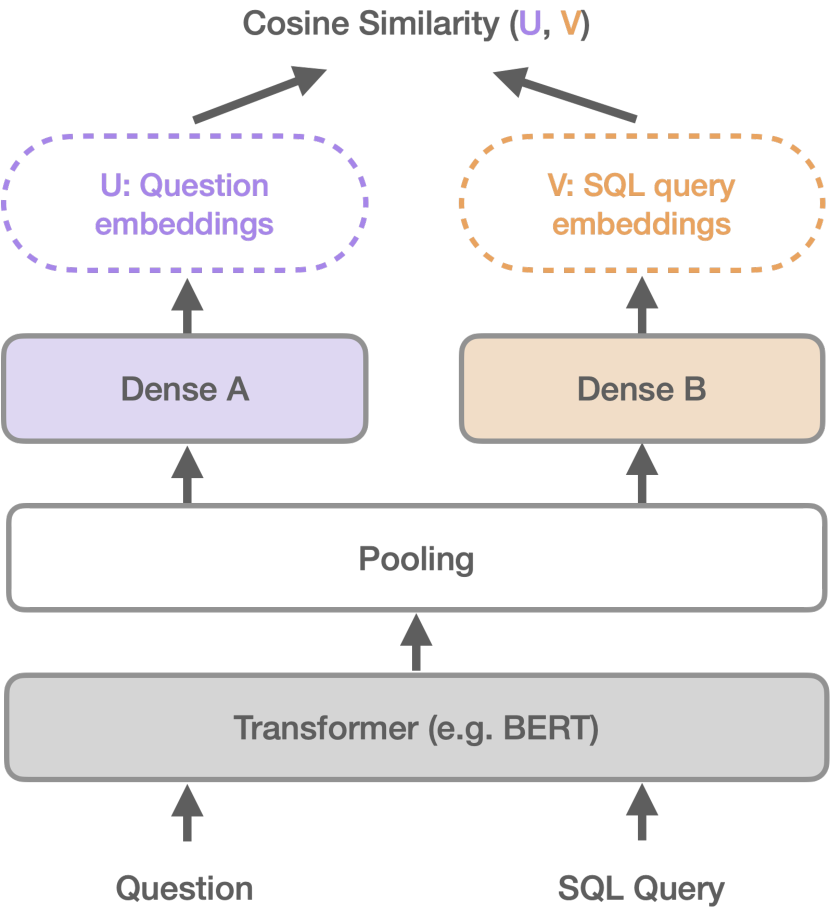
技术框架:MARLO的技术框架主要包括以下几个步骤:1) 使用预训练的语言模型(如BERT)对自然语言问题和SQL查询进行编码;2) 利用SQL查询的抽象语法树(AST)来提取查询结构信息;3) 将问题和查询的编码表示与查询结构信息相结合,得到最终的表示;4) 使用对比学习的目标函数,训练模型,使得相似的问题和查询在嵌入空间中距离更近,不相似的问题和查询距离更远。
关键创新:MARLO的关键创新在于其元数据无关的表示学习方法。与现有方法不同,MARLO不是简单地掩盖元数据,而是通过学习查询结构来建模查询意图,从而避免了对特定数据库元数据的过度依赖。这种方法使得MARLO能够更好地泛化到不同的数据库和领域。
关键设计:MARLO的关键设计包括:1) 使用SQL查询的AST来提取查询结构信息,例如选择的列、使用的聚合函数等;2) 使用对比学习的目标函数,鼓励相似的问题和查询具有相似的表示;3) 使用负采样技术,提高训练效率;4) 通过实验调整超参数,例如学习率、批大小等,以获得最佳性能。
🖼️ 关键图片
📊 实验亮点
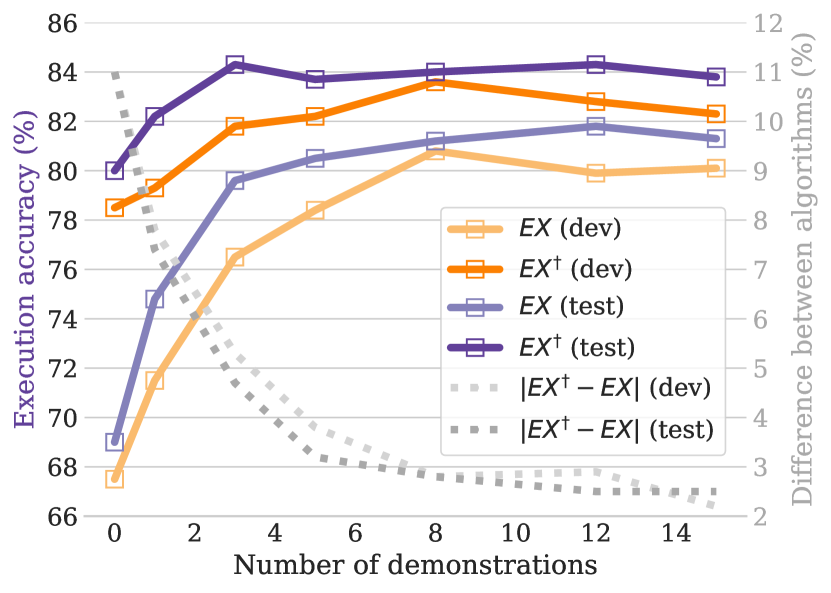
在Spider基准测试中,MARLO的执行准确率比通用嵌入模型平均提高了2.9个百分点,比下一个最佳的元数据掩码方法平均提高了0.8个百分点。同时,MARLO还显著降低了推理延迟,使其更适合实际应用。
🎯 应用场景
MARLO可应用于各种需要文本到SQL转换的场景,例如智能助手、数据库查询接口、数据分析平台等。通过提高示例选择的准确性,MARLO可以显著提升文本到SQL模型的性能,降低人工干预的需求,并促进更广泛的数据库应用。
📄 摘要(原文)
In-context learning (ICL) is a powerful paradigm where large language models (LLMs) benefit from task demonstrations added to the prompt. Yet, selecting optimal demonstrations is not trivial, especially for complex or multi-modal tasks where input and output distributions differ. We hypothesize that forming task-specific representations of the input is key. In this paper, we propose a method to align representations of natural language questions and those of SQL queries in a shared embedding space. Our technique, dubbed MARLO - Metadata-Agnostic Representation Learning for Text-tO-SQL - uses query structure to model querying intent without over-indexing on underlying database metadata (i.e. tables, columns, or domain-specific entities of a database referenced in the question or query). This allows MARLO to select examples that are structurally and semantically relevant for the task rather than examples that are spuriously related to a certain domain or question phrasing. When used to retrieve examples based on question similarity, MARLO shows superior performance compared to generic embedding models (on average +2.9\%pt. in execution accuracy) on the Spider benchmark. It also outperforms the next best method that masks metadata information by +0.8\%pt. in execution accuracy on average, while imposing a significantly lower inference latency.