Boosting LLM Translation Skills without General Ability Loss via Rationale Distillation
作者: Junhong Wu, Yang Zhao, Yangyifan Xu, Bing Liu, Chengqing Zong
分类: cs.CL
发布日期: 2024-10-17
💡 一句话要点
提出 RaDis:通过理由蒸馏提升LLM翻译能力,同时避免通用能力损失
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 机器翻译 持续学习 理由蒸馏 知识保留
📋 核心要点
- 传统微调方法提升LLM翻译能力时,易导致通用能力丧失和安全性问题。
- RaDis方法通过生成理由进行自我蒸馏,在训练中保留通用知识和安全原则。
- 实验表明,RaDis在提升翻译性能的同时,有效维护了LLM的通用能力。
📝 摘要(中文)
大型语言模型(LLMs)在众多NLP任务中取得了显著成果,但在机器翻译方面仍面临挑战。传统的翻译改进方法通常涉及使用平行语料库对LLM进行微调。然而,直接微调往往会导致灾难性地遗忘指令遵循能力和与人类偏好的一致性,从而损害其广泛的通用能力并引入潜在的安全风险。这些能力是使用专有的、不可用的训练数据开发的,使得现有的持续指令调优方法无效。为了解决这个问题,我们提出了一种名为RaDis(理由蒸馏)的新方法。RaDis利用LLM强大的生成能力为训练数据创建理由,然后“重放”这些理由以防止遗忘。这些理由封装了通用知识和安全原则,充当自我蒸馏目标来调节训练过程。通过联合训练参考翻译和自我生成的理由,模型可以学习新的翻译技能,同时保持其整体通用能力。大量实验表明,我们的方法提高了机器翻译性能,同时保持了LLM在其他任务中的更广泛能力。这项工作为创建更通用的LLM提供了一条途径,使其在专门任务中表现出色,同时又不损害通用性和安全性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在机器翻译任务中,通过微调提升翻译能力时,容易遗忘其原有的通用能力和指令遵循能力的问题。现有方法直接使用平行语料库进行微调,导致模型在其他任务上的表现显著下降,并且可能引入安全风险。
核心思路:论文的核心思路是利用LLM自身强大的生成能力,为训练数据生成“理由”(Rationales),这些理由包含了通用知识和安全原则。在微调过程中,不仅训练模型生成正确的翻译,还训练模型生成这些理由,从而起到自我蒸馏的作用,防止模型遗忘重要的通用能力。
技术框架:RaDis方法包含以下几个主要步骤:1) 使用LLM为平行语料库中的每个样本生成理由,理由解释了为什么源语言应该翻译成目标语言。2) 构建包含源语言、目标语言和理由的三元组数据集。3) 使用该数据集对LLM进行微调,微调的目标是同时生成正确的翻译和对应的理由。4) 在推理阶段,模型只需要生成翻译,不需要生成理由。
关键创新:RaDis的关键创新在于使用自我生成的理由作为蒸馏目标,从而在微调过程中保留LLM的通用能力。与传统的微调方法相比,RaDis不需要额外的通用能力数据集,而是利用LLM自身的知识来指导训练过程。这种方法避免了对通用能力数据集的依赖,并且可以更好地适应不同的任务和领域。
关键设计:在理由生成阶段,论文使用了提示工程(Prompt Engineering)来引导LLM生成高质量的理由。在微调阶段,论文使用了交叉熵损失函数来训练模型生成正确的翻译和理由。具体来说,损失函数包含两部分:翻译损失和理由损失。总损失是这两部分损失的加权和。论文还探索了不同的理由生成策略和损失函数权重,以找到最佳的训练配置。
🖼️ 关键图片
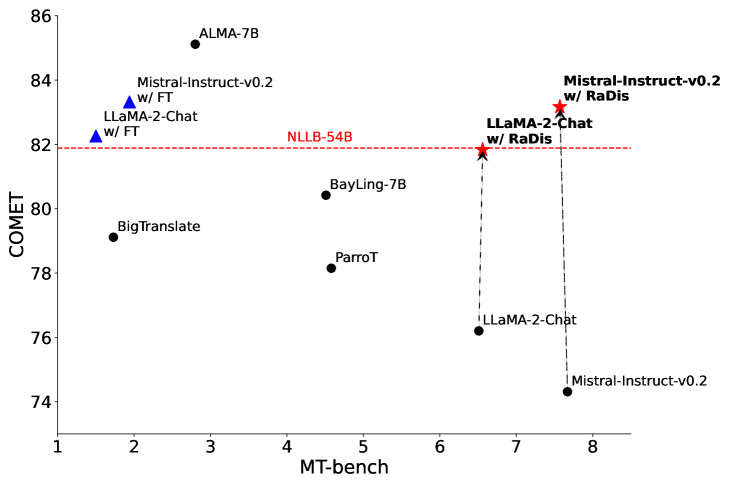


📊 实验亮点
实验结果表明,RaDis方法在提升机器翻译性能的同时,有效保留了LLM的通用能力。具体来说,RaDis在多个翻译数据集上取得了显著的提升,并且在指令遵循和安全评估等任务上的表现与原始LLM相当,甚至有所提升。这表明RaDis方法成功地避免了灾难性遗忘问题,并且能够有效地利用LLM自身的知识来指导训练过程。
🎯 应用场景
该研究成果可应用于各种需要定制化LLM的场景,例如特定领域的机器翻译、智能客服、内容生成等。通过RaDis方法,可以训练出在特定任务上表现出色,同时又保持通用能力的LLM,从而提高工作效率和用户体验。此外,该方法还有助于提高LLM的安全性,防止模型生成有害或不当的内容。
📄 摘要(原文)
Large Language Models (LLMs) have achieved impressive results across numerous NLP tasks but still encounter difficulties in machine translation. Traditional methods to improve translation have typically involved fine-tuning LLMs using parallel corpora. However, vanilla fine-tuning often leads to catastrophic forgetting of the instruction-following capabilities and alignment with human preferences, compromising their broad general abilities and introducing potential security risks. These abilities, which are developed using proprietary and unavailable training data, make existing continual instruction tuning methods ineffective. To overcome this issue, we propose a novel approach called RaDis (Rationale Distillation). RaDis harnesses the strong generative capabilities of LLMs to create rationales for training data, which are then "replayed" to prevent forgetting. These rationales encapsulate general knowledge and safety principles, acting as self-distillation targets to regulate the training process. By jointly training on both reference translations and self-generated rationales, the model can learn new translation skills while preserving its overall general abilities. Extensive experiments demonstrate that our method enhances machine translation performance while maintaining the broader capabilities of LLMs across other tasks. This work presents a pathway for creating more versatile LLMs that excel in specialized tasks without compromising generality and safety.