Can MLLMs Understand the Deep Implication Behind Chinese Images?
作者: Chenhao Zhang, Xi Feng, Yuelin Bai, Xinrun Du, Jinchang Hou, Kaixin Deng, Guangzeng Han, Qinrui Li, Bingli Wang, Jiaheng Liu, Xingwei Qu, Yifei Zhang, Qixuan Zhao, Yiming Liang, Ziqiang Liu, Feiteng Fang, Min Yang, Wenhao Huang, Chenghua Lin, Ge Zhang, Shiwen Ni
分类: cs.CL, cs.AI, cs.CV, cs.CY
发布日期: 2024-10-17
备注: 32 pages,18 figures. Project Page: https://cii-bench.github.io/ Code: https://github.com/MING_X/CII-Bench Dataset: https://huggingface.co/datasets/m-a-p/CII-Bench
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出CII-Bench基准,评估多模态大语言模型对中文图像深层含义的理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 中文图像理解 文化理解 基准数据集 情感分析
📋 核心要点
- 现有基准缺乏对多模态大语言模型(MLLM)理解中文图像深层含义能力的高阶评估。
- CII-Bench通过收集中国互联网图像和中国传统文化图像,并人工标注答案,来评估MLLM的理解能力。
- 实验表明,MLLM在CII-Bench上的表现与人类存在差距,尤其是在理解中国传统文化图像方面。
📝 摘要(中文)
随着多模态大语言模型(MLLM)能力的不断提高,对MLLM进行更高阶能力评估的需求也在增加。然而,目前缺乏评估MLLM对中文视觉内容进行更高阶感知和理解的工作。为了填补这一空白,我们推出了中文图像含义理解基准CII-Bench,旨在评估MLLM对中文图像的更高阶感知和理解能力。与现有基准相比,CII-Bench在几个方面脱颖而出。首先,为了确保中文语境的真实性,CII-Bench中的图像来源于中国互联网并经过人工审核,相应的答案也是人工制作的。此外,CII-Bench还包含代表中国传统文化的图像,例如中国著名的传统绘画,可以深刻反映模型对中国传统文化的理解。通过在多个MLLM上对CII-Bench进行的大量实验,我们取得了重要的发现。最初,观察到MLLM在CII-Bench上的表现与人类之间存在显著差距。MLLM的最高准确率达到64.4%,而人类的平均准确率为78.2%,最高可达81.0%。其次,MLLM在中国传统文化图像上的表现较差,表明它们在理解高层语义方面存在局限性,并且缺乏对中国传统文化的深入知识库。最后,观察到当图像情感提示被纳入提示中时,大多数模型的准确性都会提高。我们相信CII-Bench将使MLLM能够更好地理解中文语义和中国特定的图像,从而推动迈向专家级通用人工智能(AGI)的进程。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)对中文图像深层含义理解能力评估不足的问题。现有方法缺乏针对中文文化背景的图像数据集,无法有效评估MLLM对中国文化、习俗和隐含意义的理解程度。这阻碍了MLLM在中文环境下的应用和发展。
核心思路:论文的核心思路是构建一个专门针对中文图像含义理解的基准数据集CII-Bench。该数据集包含来自中国互联网的真实图像和代表中国传统文化的图像,并由人工标注答案。通过在该数据集上评估MLLM的表现,可以更全面地了解MLLM对中文图像深层含义的理解能力。
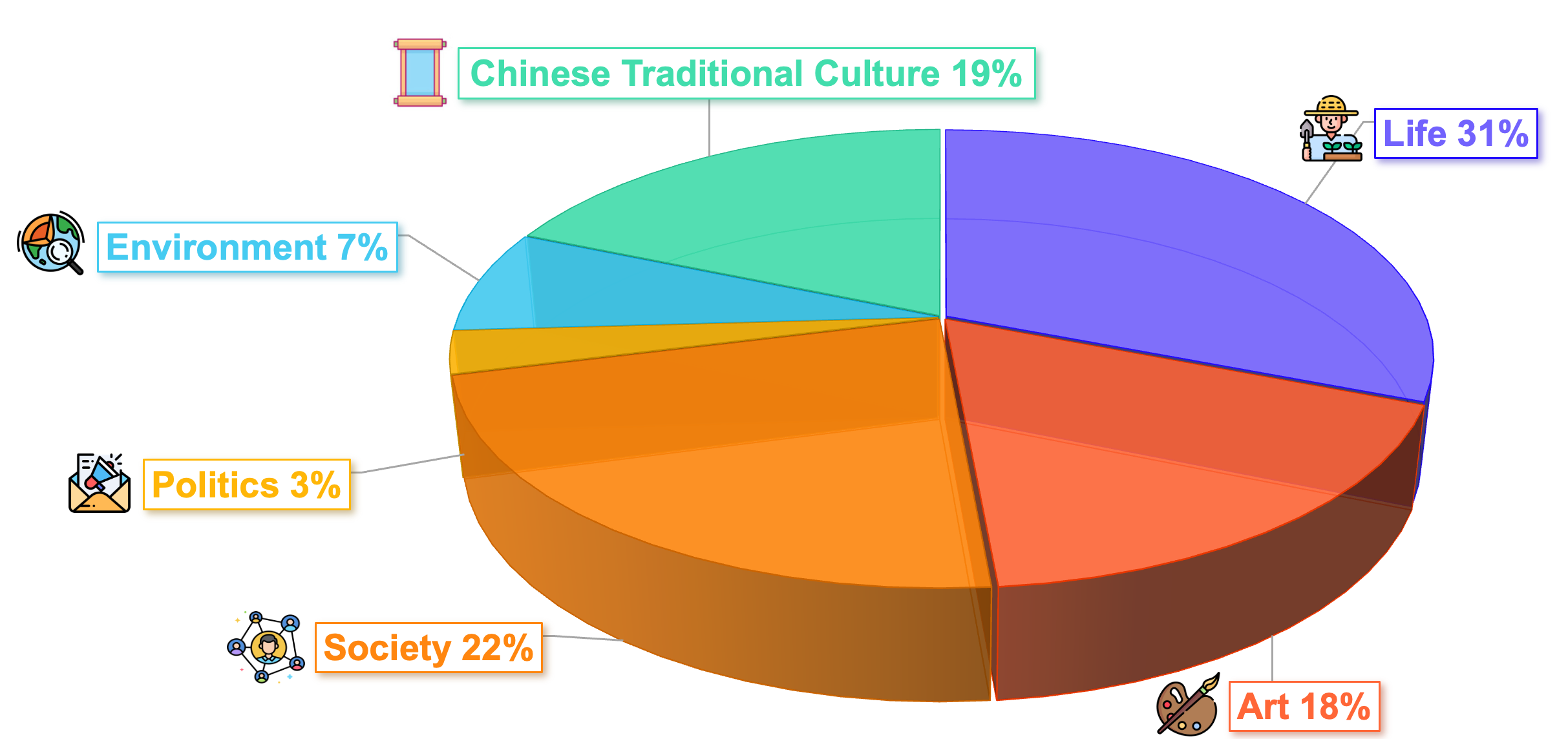
技术框架:CII-Bench的构建流程主要包括以下几个阶段:1) 图像收集:从中国互联网和文化遗产资源中收集图像,确保图像的多样性和代表性。2) 人工标注:由专家团队对图像进行分析,并标注图像所蕴含的深层含义,包括文化背景、情感色彩、象征意义等。3) 基准测试:选择多个主流的MLLM模型,在CII-Bench上进行测试,并分析模型的表现。4) 结果分析:对测试结果进行深入分析,找出MLLM在理解中文图像深层含义方面的优势和不足。
关键创新:CII-Bench的关键创新在于其专注于评估MLLM对中文图像深层含义的理解能力。与现有数据集相比,CII-Bench更注重图像的文化背景和隐含意义,能够更有效地评估MLLM在中文环境下的表现。此外,CII-Bench还包含了中国传统文化图像,可以评估MLLM对中国传统文化的理解程度。
关键设计:CII-Bench的数据集包含两部分:来自中国互联网的图像和代表中国传统文化的图像。图像的选择标准包括图像的清晰度、代表性和多样性。人工标注过程由专家团队进行,确保标注的准确性和一致性。评估指标包括准确率、召回率和F1值等。在实验中,论文使用了多个主流的MLLM模型,并对模型的参数进行了优化。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MLLM在CII-Bench上的最高准确率为64.4%,而人类的平均准确率为78.2%,最高可达81.0%。MLLM在中国传统文化图像上的表现明显低于其他图像,表明其缺乏对中国传统文化的深入理解。加入图像情感提示后,大多数模型的准确率有所提高,说明情感信息对理解图像含义有重要作用。
🎯 应用场景
CII-Bench可用于评估和提升多模态大语言模型对中文图像的理解能力,尤其是在文化理解和情感分析方面。这有助于开发更智能、更符合中国文化背景的AI应用,例如智能客服、文化遗产保护、社交媒体内容审核等。未来,该基准可以扩展到其他亚洲文化,促进跨文化交流和理解。
📄 摘要(原文)
As the capabilities of Multimodal Large Language Models (MLLMs) continue to improve, the need for higher-order capability evaluation of MLLMs is increasing. However, there is a lack of work evaluating MLLM for higher-order perception and understanding of Chinese visual content. To fill the gap, we introduce the Chinese Image Implication understanding Benchmark, CII-Bench, which aims to assess the higher-order perception and understanding capabilities of MLLMs for Chinese images. CII-Bench stands out in several ways compared to existing benchmarks. Firstly, to ensure the authenticity of the Chinese context, images in CII-Bench are sourced from the Chinese Internet and manually reviewed, with corresponding answers also manually crafted. Additionally, CII-Bench incorporates images that represent Chinese traditional culture, such as famous Chinese traditional paintings, which can deeply reflect the model's understanding of Chinese traditional culture. Through extensive experiments on CII-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on CII-Bench. The highest accuracy of MLLMs attains 64.4%, where as human accuracy averages 78.2%, peaking at an impressive 81.0%. Subsequently, MLLMs perform worse on Chinese traditional culture images, suggesting limitations in their ability to understand high-level semantics and lack a deep knowledge base of Chinese traditional culture. Finally, it is observed that most models exhibit enhanced accuracy when image emotion hints are incorporated into the prompts. We believe that CII-Bench will enable MLLMs to gain a better understanding of Chinese semantics and Chinese-specific images, advancing the journey towards expert artificial general intelligence (AGI). Our project is publicly available at https://cii-bench.github.io/.