Modeling Future Conversation Turns to Teach LLMs to Ask Clarifying Questions
作者: Michael J. Q. Zhang, W. Bradley Knox, Eunsol Choi
分类: cs.CL
发布日期: 2024-10-17 (更新: 2025-03-18)
备注: Presented at ICLR 2025
💡 一句话要点
通过建模未来对话轮次,提升LLM提问澄清问题的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 澄清问题 对话建模 偏好学习 开放域问答
📋 核心要点
- 现有LLM在处理模糊用户请求时,倾向于预设单一解释,导致用户体验不佳。
- 论文提出通过模拟未来对话轮次,为LLM的响应分配偏好标签,鼓励提问澄清问题。
- 实验表明,该方法在开放域QA任务中,能有效提升LLM提问澄清问题的能力,F1值提升5%。
📝 摘要(中文)
大型语言模型(LLM)经常需要响应高度模糊的用户请求。在这种情况下,LLM的最佳响应可能是提出一个澄清问题以获取更多信息。现有的LLM通常通过预设对模糊请求的单一解释来进行响应,这会让意图进行不同解释的用户感到沮丧。我们推测这是由于当前偏好数据标注实践造成的,其中LLM响应仅根据其先前的上下文进行评估。为了解决这个问题,我们通过模拟其在未来轮次中的预期结果来分配偏好标签。这使得LLM能够学习在未来轮次中生成针对每个用户解释量身定制的响应时,提出澄清问题。在具有多个注释的开放域问答数据集上,我们根据系统提出澄清问题以恢复每个用户的解释和预期答案的能力来评估系统。我们将使用我们提出的偏好标签方法训练的系统与仅基于先前上下文分配偏好的标准方法进行比较。我们的方法在针对每个查询的不同解释的答案集测量的F1值上实现了5%的改进,表明了建模未来对话轮次的价值。我们进一步证明,我们的方法可用于训练模型来明智地确定何时提出澄清问题,并在不需要澄清时直接回答问题。在我们的实验中,我们发现我们的方法在对此类判断的准确性方面比现有方法提高了3%。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在面对模糊用户请求时,无法有效提问澄清问题的问题。现有方法通常只基于先前的上下文评估LLM的响应,导致LLM倾向于预设单一解释,忽略了用户可能存在的其他意图,从而降低了用户体验。
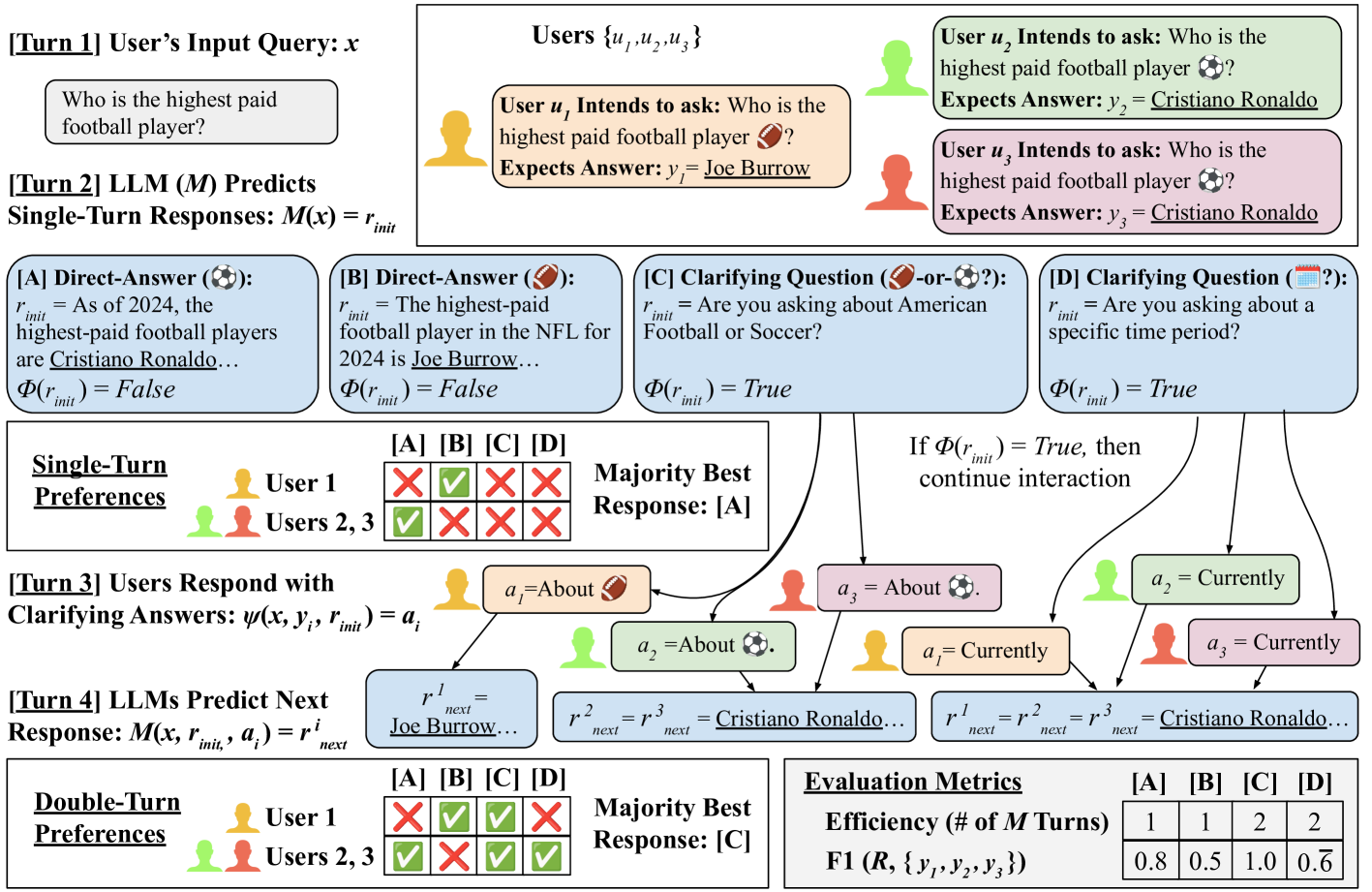
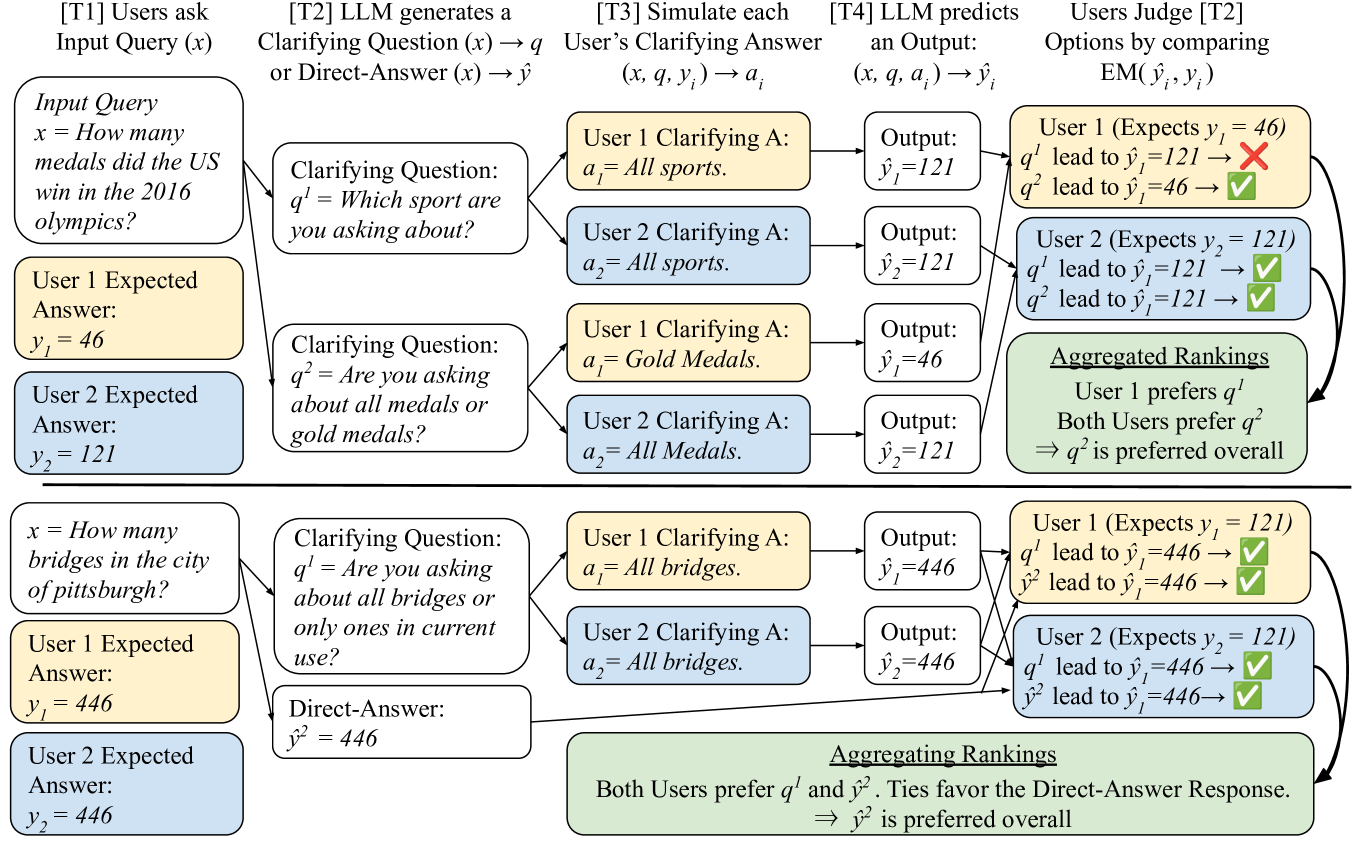
核心思路:论文的核心思路是通过建模未来对话轮次来改进LLM的训练方式。具体来说,不是仅仅基于当前上下文来评估LLM的响应,而是模拟LLM提出澄清问题后,用户给出不同回答,以及LLM基于这些回答给出最终答案的过程。通过这种方式,LLM可以学习到在不同用户意图下,哪些澄清问题能够带来更好的最终结果。
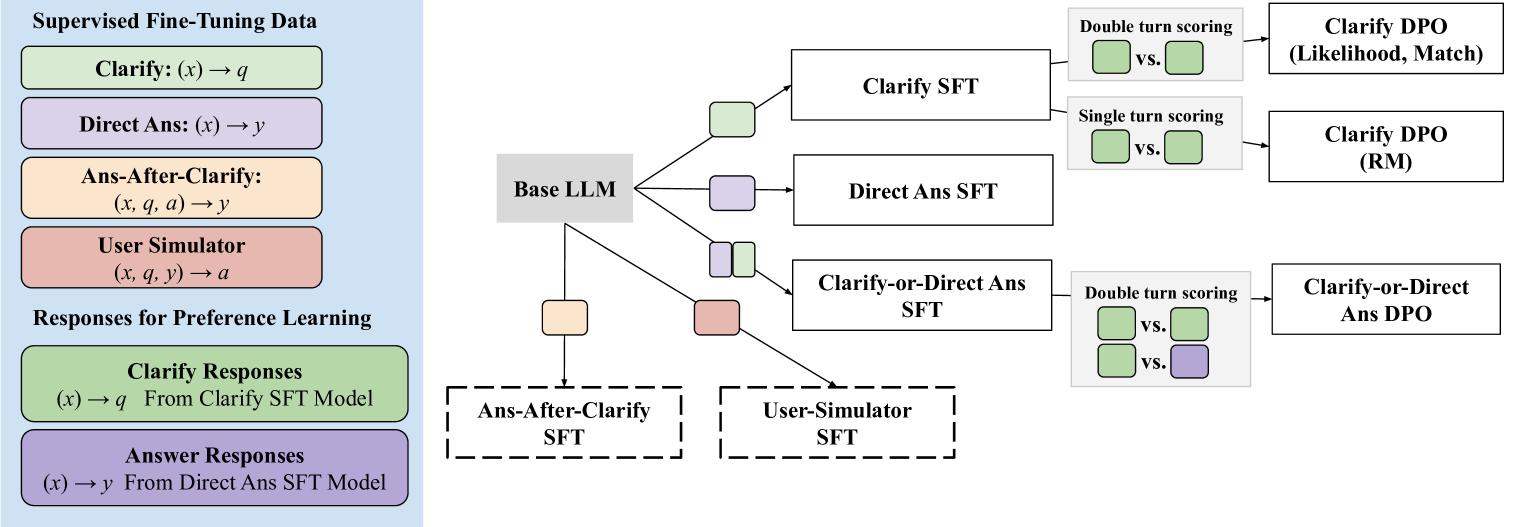
技术框架:整体框架包含以下几个阶段:1) LLM接收到模糊的用户请求;2) LLM生成一个或多个可能的澄清问题;3) 模拟用户对每个澄清问题给出不同的回答;4) LLM基于每个澄清问题和用户回答,生成最终答案;5) 基于最终答案的质量,为LLM的初始响应(包括是否提问澄清问题,以及提问哪个澄清问题)分配偏好标签。这个偏好标签会用于训练LLM。
关键创新:最重要的技术创新点在于偏好标签的分配方式。传统的偏好标签分配方式只考虑了LLM的初始响应和先前的上下文,而论文提出的方法则考虑了未来对话轮次的影响。通过模拟未来对话轮次,LLM可以学习到哪些澄清问题能够带来更好的最终结果,从而更好地适应用户的不同意图。
关键设计:论文的关键设计在于如何有效地模拟未来对话轮次。具体来说,论文使用了具有多个注释的开放域QA数据集,这些注释代表了用户对同一问题的不同理解。论文利用这些不同的注释来模拟用户对澄清问题的不同回答,并基于这些回答生成最终答案。此外,论文还设计了一种损失函数,用于鼓励LLM在需要澄清时提出澄清问题,并在不需要澄清时直接回答问题。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在开放域QA数据集上,针对不同解释的答案集,F1值提升了5%。此外,该方法还能提升LLM判断是否需要提问澄清问题的准确性,相比现有方法提高了3%。这些结果表明,建模未来对话轮次能够有效提升LLM提问澄清问题的能力。
🎯 应用场景
该研究成果可应用于各种需要与用户进行自然语言交互的场景,例如智能客服、虚拟助手、教育机器人等。通过提升LLM提问澄清问题的能力,可以更准确地理解用户意图,提供更个性化、更有效的服务,从而提升用户满意度和使用体验。未来,该技术有望在人机协作、智能决策等领域发挥重要作用。
📄 摘要(原文)
Large language models (LLMs) must often respond to highly ambiguous user requests. In such cases, the LLM's best response may be to ask a clarifying question to elicit more information. Existing LLMs often respond by presupposing a single interpretation of such ambiguous requests, frustrating users who intended a different interpretation. We speculate this is caused by current preference data labeling practice, where LLM responses are evaluated only on their prior contexts. To address this, we assign preference labels by simulating their expected outcomes in future turns. This allows LLMs to learn to ask clarifying questions when it can generate responses that are tailored to each user interpretation in future turns. On open-domain QA datasets with multiple annotations, we evaluate systems based on their ability to ask clarifying questions to recover each user's interpretation and expected answer. We compare systems trained using our proposed preference labeling methods against standard methods, which assign preferences based on only prior context. Our method achieves a 5% improvement in F1 measured against the answer set from different interpretations of each query, showing the value of modeling future conversation turns. We further demonstrate that our method can be used to train models to judiciously determine when to ask clarifying questions, directly answering the question when clarification is unnecessary. In our experiments, we find that our method achieves a 3% improvement in accuracy of such judgments over existing methods.