Aggregation Artifacts in Subjective Tasks Collapse Large Language Models' Posteriors
作者: Georgios Chochlakis, Alexandros Potamianos, Kristina Lerman, Shrikanth Narayanan
分类: cs.CL, cs.AI
发布日期: 2024-10-17 (更新: 2025-05-26)
备注: 16 pages, 12 figures, 3 tables
期刊: Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5513-5528, Albuquerque, New Mexico, April 2025
DOI: 10.18653/v1/2025.naacl-long.284
💡 一句话要点
揭示主观任务数据聚合伪影如何影响大语言模型后验分布
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 上下文学习 主观任务 数据聚合 标注伪影 后验分布 情感分析
📋 核心要点
- 现有研究表明,大语言模型的上下文学习(ICL)在主观任务中过度依赖先验知识,而非真正学习。
- 该研究的核心在于探究数据聚合方式是否是导致ICL在主观任务中表现不佳的因素之一。
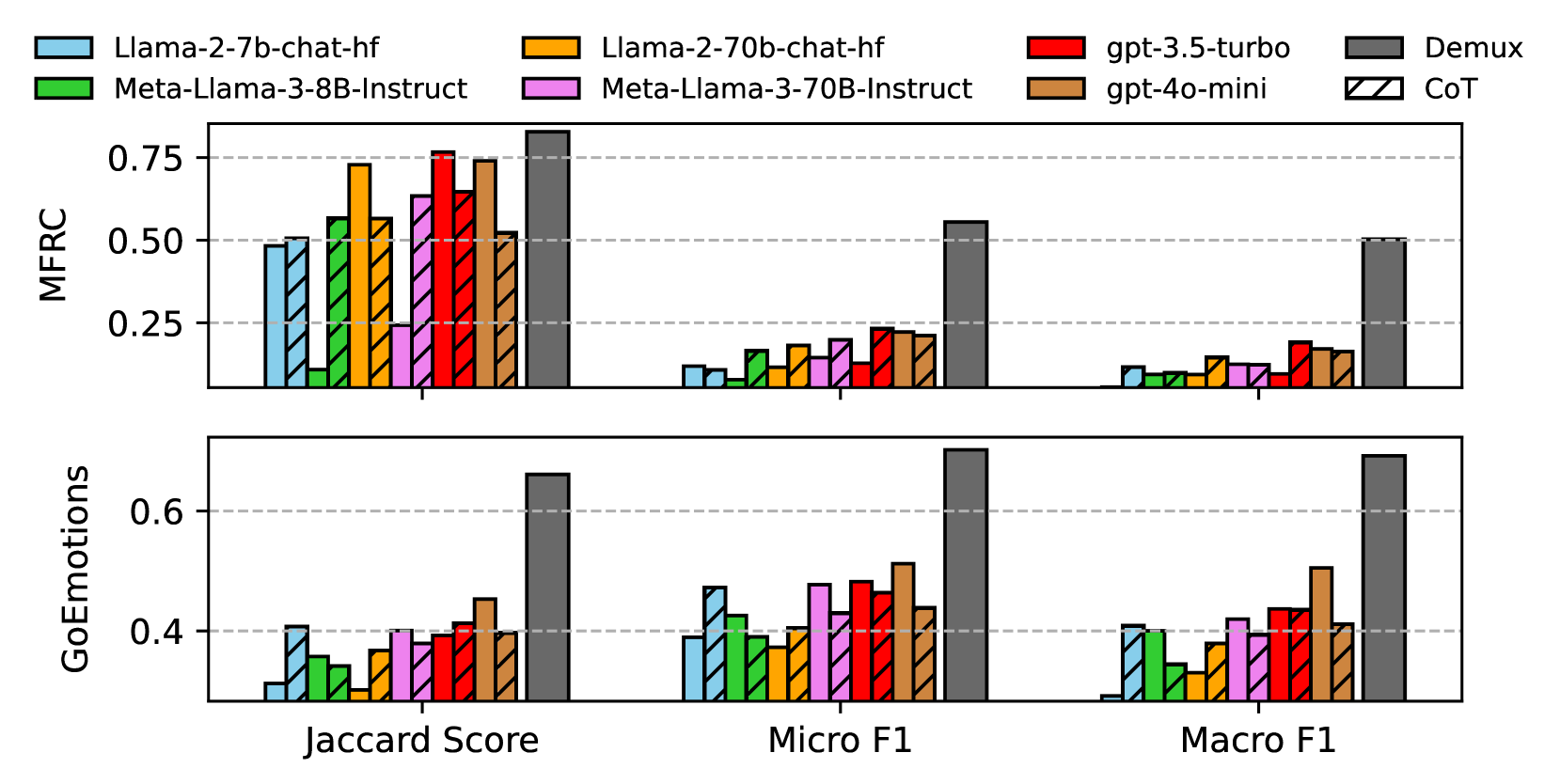
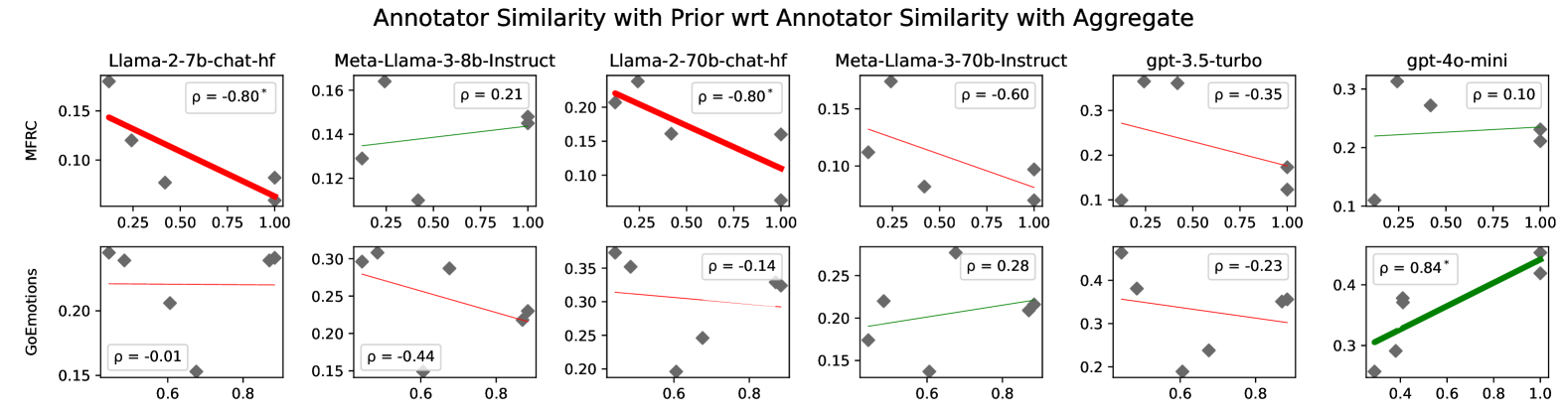
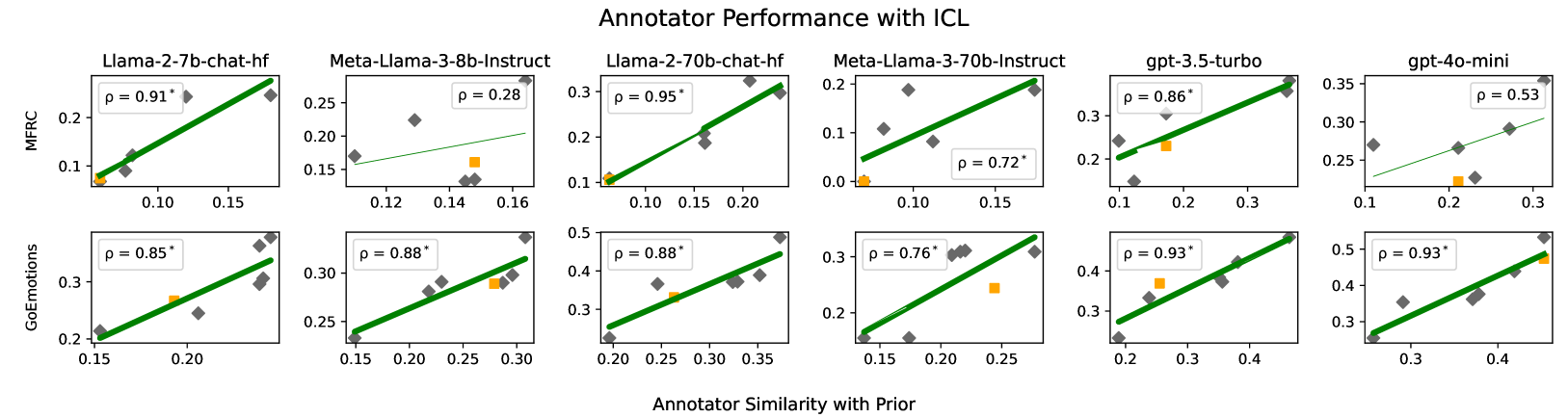
- 实验结果表明,数据聚合会引入噪声,影响模型性能,并发现少数标注者可能与LLM更好地对齐。
📝 摘要(中文)
上下文学习(ICL)已成为利用大型语言模型(LLM)执行自然语言任务的主要方法。预训练期间获得的知识对于这种少样本能力至关重要,它为模型提供了任务先验。然而,最近的研究表明,ICL主要依赖于检索任务先验,而不是“学习”执行任务。这种局限性在情感和道德等复杂的、主观的领域中尤为明显,在这些领域中,先验会显著影响后验预测。本文研究了这是否是相应数据集中使用的聚合造成的,在这些数据集中,试图组合低一致性的、不同的标注可能会导致标注伪影,从而在提示中产生有害的噪声。此外,我们通过将研究建立在适当的、定量的LLM先验度量基础上,评估了后验对某些标注者的偏差。结果表明,聚合是主观任务建模中的一个混淆因素,并提倡关注个体建模。然而,聚合并不能解释ICL与现有技术之间的全部差距,这意味着此类任务中的其他因素也解释了观察到的现象。最后,通过严格研究标注者级别的标签,我们发现少数标注者既可以更好地与LLM对齐,他们的观点也可以得到进一步放大。
🔬 方法详解
问题定义:论文旨在研究在主观任务中,数据聚合方式对大语言模型(LLM)上下文学习(ICL)性能的影响。现有方法在构建主观任务数据集时,通常采用聚合多个标注者结果的方式,但这种方式可能会引入噪声,掩盖个体差异,导致LLM无法有效学习任务。
核心思路:论文的核心思路是,数据聚合过程可能产生“伪影”,即由聚合过程引入的、与真实任务无关的噪声。这些伪影会干扰LLM的学习,使其过度依赖先验知识,而非真正理解任务。因此,论文建议关注个体标注者的观点,而非简单地聚合所有标注。
技术框架:论文的研究框架主要包括以下几个步骤: 1. 选择主观任务数据集,例如情感分析、道德判断等。 2. 分析数据集的标注一致性,评估聚合过程可能引入的噪声。 3. 使用LLM进行ICL实验,比较不同聚合方式下的模型性能。 4. 分析LLM的后验分布,评估其对不同标注者的偏好。 5. 研究个体标注者的标签与LLM预测结果之间的关系。
关键创新:论文的关键创新在于: 1. 提出了数据聚合伪影的概念,并将其与LLM在主观任务中的表现联系起来。 2. 强调了关注个体标注者观点的重要性,而非简单地聚合所有标注。 3. 提出了评估LLM对不同标注者偏好的方法。
关键设计:论文的关键设计包括: 1. 选择具有代表性的主观任务数据集,并进行详细的标注一致性分析。 2. 设计合理的ICL实验,评估不同聚合方式下的模型性能。 3. 使用定量指标评估LLM的后验分布,例如KL散度等。 4. 分析个体标注者的标签与LLM预测结果之间的相关性,例如皮尔逊相关系数等。
🖼️ 关键图片
📊 实验亮点
研究结果表明,数据聚合是主观任务建模中的一个混淆因素,聚合过程引入的噪声会影响LLM的性能。论文还发现,少数标注者可能与LLM更好地对齐,他们的观点可以被进一步放大。虽然聚合不能完全解释ICL与SOTA之间的差距,但强调了其在主观任务中的重要性。
🎯 应用场景
该研究成果可应用于改进主观任务数据集的构建方法,例如情感分析、观点挖掘、道德判断等。通过关注个体标注者的观点,可以减少数据聚合带来的噪声,提高LLM在这些任务中的性能。此外,该研究还可以帮助我们更好地理解LLM的偏见,并设计更公平、更可靠的AI系统。
📄 摘要(原文)
In-context Learning (ICL) has become the primary method for performing natural language tasks with Large Language Models (LLMs). The knowledge acquired during pre-training is crucial for this few-shot capability, providing the model with task priors. However, recent studies have shown that ICL predominantly relies on retrieving task priors rather than "learning" to perform tasks. This limitation is particularly evident in complex subjective domains such as emotion and morality, where priors significantly influence posterior predictions. In this work, we examine whether this is the result of the aggregation used in corresponding datasets, where trying to combine low-agreement, disparate annotations might lead to annotation artifacts that create detrimental noise in the prompt. Moreover, we evaluate the posterior bias towards certain annotators by grounding our study in appropriate, quantitative measures of LLM priors. Our results indicate that aggregation is a confounding factor in the modeling of subjective tasks, and advocate focusing on modeling individuals instead. However, aggregation does not explain the entire gap between ICL and the state of the art, meaning other factors in such tasks also account for the observed phenomena. Finally, by rigorously studying annotator-level labels, we find that it is possible for minority annotators to both better align with LLMs and have their perspectives further amplified.