Cerberus: Efficient Inference with Adaptive Parallel Decoding and Sequential Knowledge Enhancement
作者: Yuxuan Liu, Wenyuan Li, Laizhong Cui, Hailiang Yang
分类: cs.CL, cs.AI
发布日期: 2024-10-17
💡 一句话要点
Cerberus:通过自适应并行解码和序列知识增强实现高效LLM推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 并行解码 自适应解码 序列知识增强 高效推理
📋 核心要点
- 现有并行解码方法难以兼顾预测精度和并行执行效率,导致性能瓶颈。
- Cerberus通过门控机制自适应选择解码方式,并设计新的解码头引入序列知识。
- 实验表明,Cerberus相比自回归解码加速高达2.12倍,且优于Medusa。
📝 摘要(中文)
大型语言模型(LLMs)由于依赖自回归解码,在推理速度方面常常面临瓶颈。最近,并行解码在提高推理效率方面显示出巨大的潜力。然而,我们发现现有并行解码框架存在两个关键问题:(1)解码头未能平衡预测准确性和执行并行性;(2)并行解码并非通用解决方案,在一些具有挑战性的解码步骤中可能会带来不必要的开销。为了解决这些问题,我们提出了Cerberus,一个自适应并行解码框架,引入门控机制,使LLM能够在每个解码步骤自适应地选择合适的解码方法,同时引入一种新的解码头范式,在保持执行并行性的同时引入序列知识。实验结果表明,与自回归解码相比,Cerberus可以实现高达2.12倍的加速,并且优于领先的并行解码框架Medusa,加速提升10%-30%,并具有卓越的生成质量。
🔬 方法详解
问题定义:现有的大型语言模型推理速度受限于自回归解码的串行性质。并行解码虽然可以加速推理,但现有方法存在两个主要问题:一是解码头在预测准确性和并行度之间难以平衡;二是并行解码并非在所有情况下都适用,在某些复杂场景下反而会引入额外的计算开销。因此,需要一种能够自适应地选择解码方式,并且能够有效利用并行计算资源的推理框架。
核心思路:Cerberus的核心思路是使LLM能够在每个解码步骤自适应地选择合适的解码方法,从而在保证生成质量的同时,最大化推理速度。此外,Cerberus还引入了一种新的解码头范式,该范式在保持执行并行性的同时,能够有效地利用序列知识,进一步提高预测准确性。
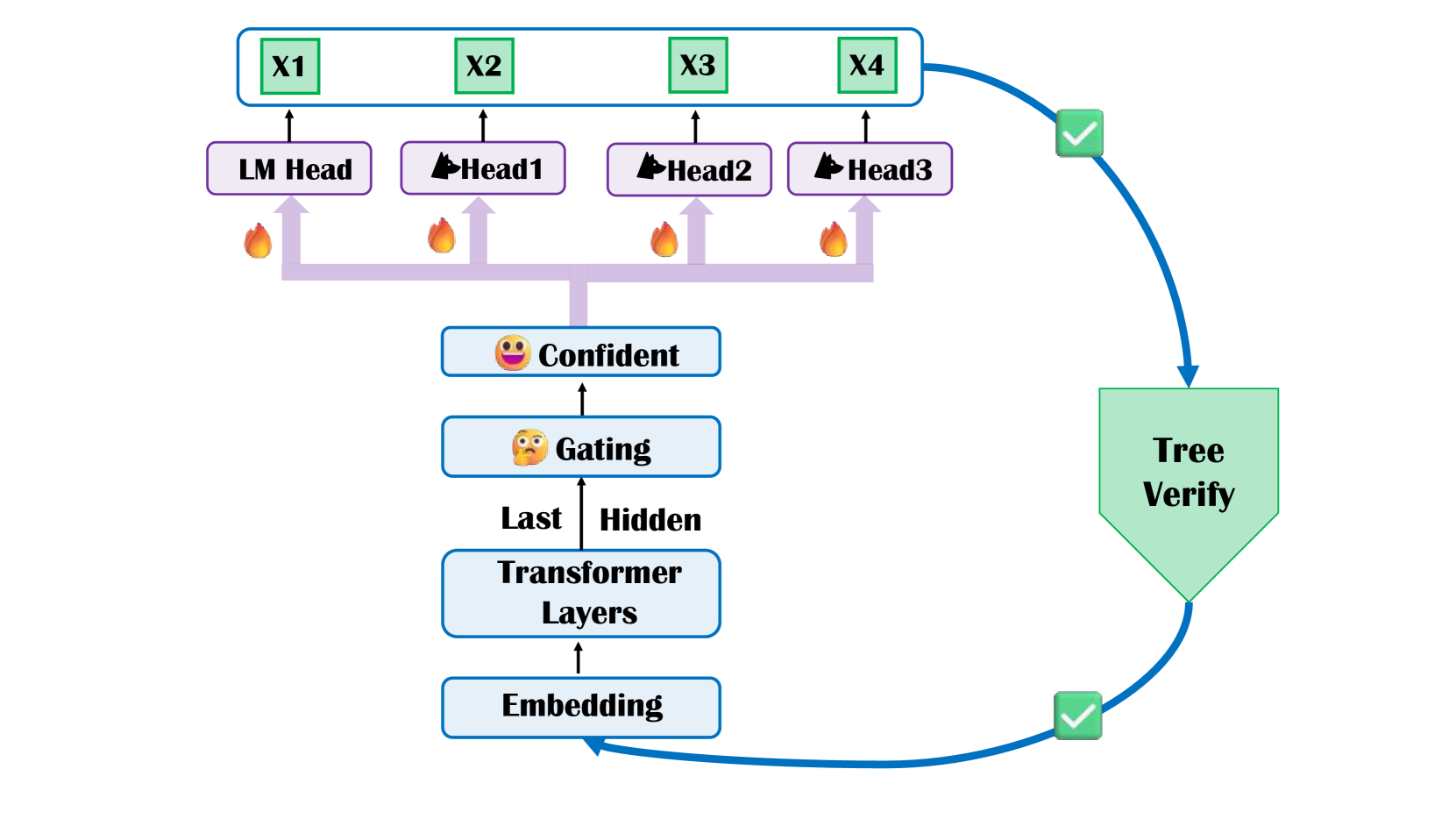
技术框架:Cerberus框架主要包含两个核心模块:自适应解码选择模块和序列知识增强的并行解码头。自适应解码选择模块通过门控机制,根据当前解码步骤的上下文信息,动态地选择使用并行解码或自回归解码。序列知识增强的并行解码头则在并行解码的过程中,引入序列依赖信息,从而提高预测的准确性。整体流程为:输入文本 -> LLM编码 -> 自适应解码选择 -> 并行/自回归解码 -> 输出文本。
关键创新:Cerberus的关键创新在于其自适应解码选择机制和序列知识增强的并行解码头。自适应解码选择机制能够根据不同的解码步骤动态地选择最合适的解码方式,避免了并行解码在所有情况下都适用的局限性。序列知识增强的并行解码头则在并行解码的过程中,有效地利用了序列依赖信息,提高了预测的准确性。与现有方法相比,Cerberus能够更好地平衡预测准确性和推理速度。
关键设计:自适应解码选择模块使用一个门控网络,该网络以当前解码步骤的上下文信息作为输入,输出一个概率值,该概率值表示使用并行解码的概率。序列知识增强的并行解码头通过引入一个小的序列模型(例如,Transformer层)来捕捉序列依赖信息,并将该信息融入到并行解码的预测结果中。具体的损失函数和网络结构细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片

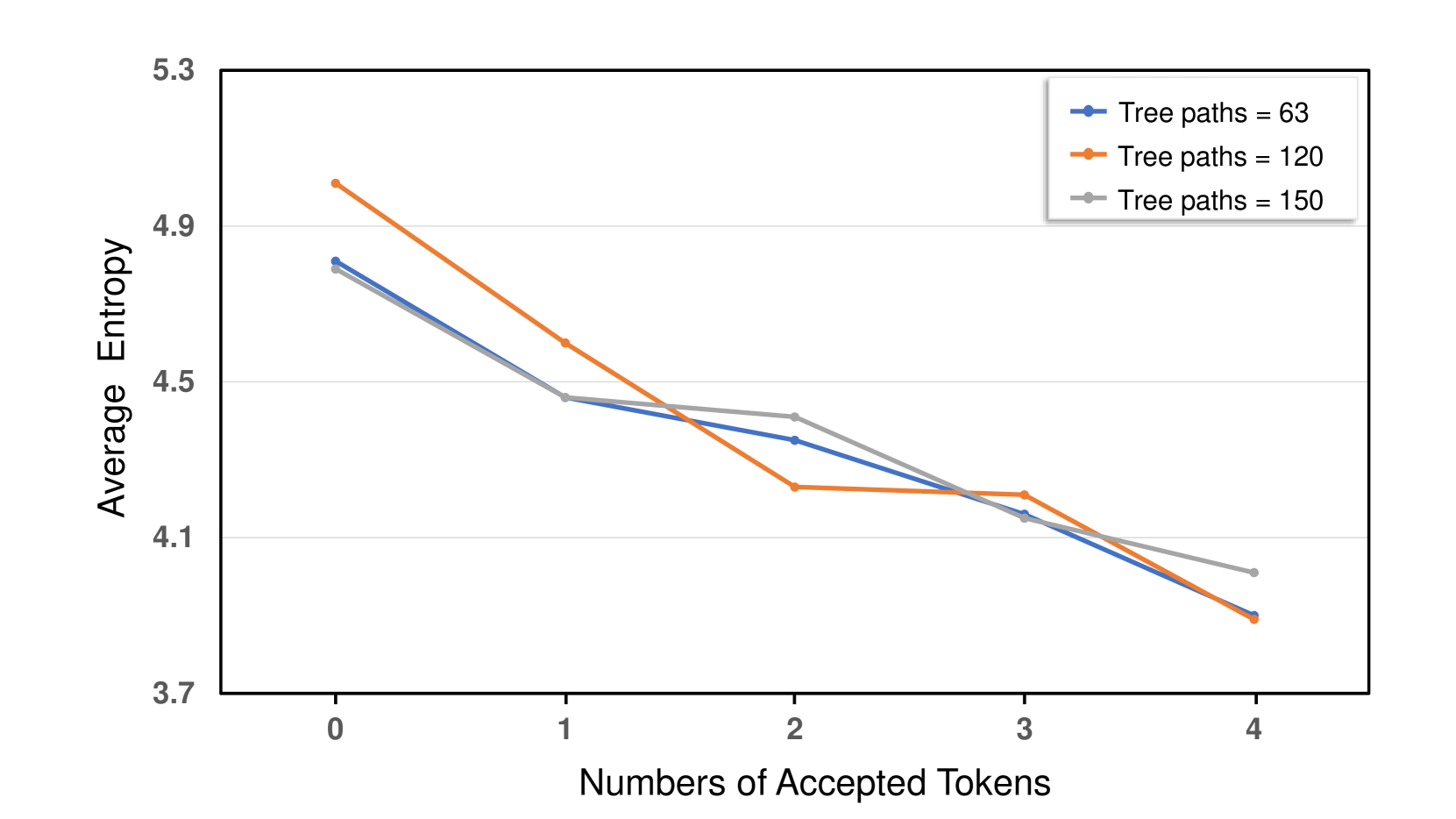
📊 实验亮点
Cerberus在实验中表现出色,与自回归解码相比,实现了高达2.12倍的加速。同时,Cerberus也优于领先的并行解码框架Medusa,加速提升了10%-30%,并且生成质量更优。这些结果表明,Cerberus在提高LLM推理效率方面具有显著优势。
🎯 应用场景
Cerberus可应用于各种需要快速推理的大型语言模型应用场景,例如实时对话系统、机器翻译、文本摘要、代码生成等。通过提高推理效率,Cerberus可以降低部署成本,提升用户体验,并促进LLM在资源受限环境中的应用。未来,该技术有望进一步扩展到其他序列生成任务中。
📄 摘要(原文)
Large language models (LLMs) often face a bottleneck in inference speed due to their reliance on auto-regressive decoding. Recently, parallel decoding has shown significant promise in enhancing inference efficiency. However, we have identified two key issues with existing parallel decoding frameworks: (1) decoding heads fail to balance prediction accuracy and the parallelism of execution, and (2) parallel decoding is not a universal solution, as it can bring unnecessary overheads at some challenging decoding steps. To address these issues, we propose Cerberus, an adaptive parallel decoding framework introduces the gating mechanism to enable the LLMs to adaptively choose appropriate decoding approaches at each decoding step, along with introducing a new paradigm of decoding heads that introduce the sequential knowledge while maintaining execution parallelism. The experiment results demonstrate that the Cerberus can achieve up to 2.12x speed up compared to auto-regressive decoding, and outperforms one of the leading parallel decoding frameworks, Medusa, with a 10% - 30% increase in acceleration and superior generation quality.