Learning to Route LLMs with Confidence Tokens
作者: Yu-Neng Chuang, Prathusha Kameswara Sarma, Parikshit Gopalan, John Boccio, Sara Bolouki, Xia Hu, Helen Zhou
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-10-17 (更新: 2025-06-19)
💡 一句话要点
提出Self-REF,通过置信度令牌提升LLM在下游任务中的可靠性和准确性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 置信度评估 自反思学习 错误反馈 路由学习
📋 核心要点
- 现有LLM在实际应用中缺乏可靠的置信度评估机制,难以判断其输出是否可信,尤其在高风险场景下。
- Self-REF通过引入置信度令牌,并利用错误反馈进行训练,使LLM能够更准确地表达自身答案的置信度。
- 实验表明,相比传统方法,Self-REF在下游路由和拒绝学习任务中显著提升了LLM的准确性和可靠性。
📝 摘要(中文)
大型语言模型(LLMs)在多个任务中表现出令人印象深刻的性能,并越来越多地部署在实际应用中。然而,尤其是在高风险环境中,了解LLM的输出何时可能不可靠至关重要。根据答案是否可信,系统可以选择将问题路由给其他专家,或者退回到安全的默认行为。本文研究了LLM在多大程度上可以可靠地表明对其答案的置信度,以及这种置信度的概念如何转化为下游准确性的提高。我们提出了一种基于错误反馈的自反思(Self-REF)的轻量级训练策略,以教导LLM以可靠的方式表达对其答案是否正确的置信度。Self-REF将置信度令牌引入LLM,从中可以提取置信度分数。与诸如口头表达置信度和检查令牌概率等传统方法相比,我们通过实验证明,置信度令牌在下游路由和拒绝学习任务中显示出显着改进。
🔬 方法详解
问题定义:论文旨在解决LLM在实际应用中缺乏可靠的置信度评估机制的问题。现有方法,如口头表达置信度和检查token概率,无法准确反映LLM的真实置信水平,导致在高风险场景下难以判断其输出是否可信,从而影响决策。
核心思路:论文的核心思路是训练LLM学会使用特定的“置信度令牌”来表达其对答案正确性的置信度。通过引入这些令牌,并结合错误反馈进行训练,使LLM能够更准确地校准其置信度输出,从而提高下游任务的性能。
技术框架:Self-REF框架主要包含以下几个阶段:1) 在LLM中引入特殊的置信度令牌;2) 使用包含正确答案和错误答案的数据集对LLM进行训练;3) 在训练过程中,根据LLM的答案是否正确,给予不同的反馈信号,引导LLM学习如何使用置信度令牌来表达其置信度;4) 从置信度令牌中提取置信度分数,用于下游任务,如路由和拒绝学习。
关键创新:Self-REF的关键创新在于引入了置信度令牌,并结合错误反馈进行训练。与传统的置信度评估方法相比,Self-REF能够更直接地训练LLM表达其置信度,从而避免了对LLM内部状态的间接推断,提高了置信度评估的准确性。
关键设计:Self-REF的关键设计包括:1) 置信度令牌的选择:选择与任务相关的、易于学习的令牌;2) 错误反馈的设计:根据答案的正确性,给予不同的奖励或惩罚信号,引导LLM学习如何使用置信度令牌;3) 置信度分数的提取:设计合适的函数,将置信度令牌的输出转换为置信度分数,用于下游任务。
🖼️ 关键图片

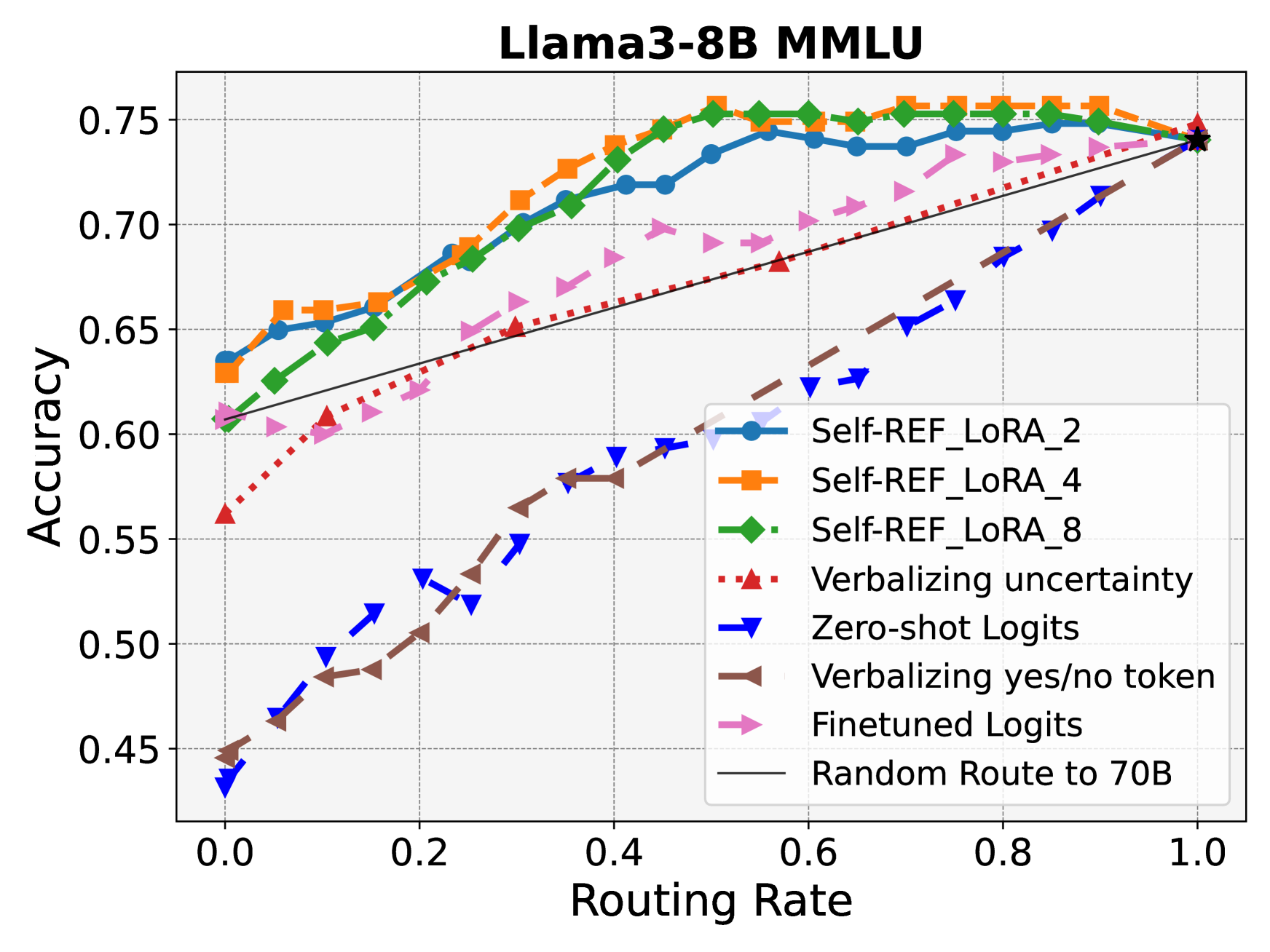

📊 实验亮点
实验结果表明,Self-REF在下游路由和拒绝学习任务中显著优于传统方法。例如,在某个数据集上,Self-REF可以将LLM的准确率提高10%以上,同时显著降低了错误决策的概率。此外,Self-REF的训练过程相对轻量级,易于部署和应用。
🎯 应用场景
该研究成果可应用于各种需要LLM提供可靠输出的场景,例如医疗诊断、金融风控、法律咨询等。通过置信度评估,系统可以将问题路由给更专业的专家,或者采取更保守的策略,从而降低错误决策的风险,提高系统的整体可靠性。未来,该方法可以进一步扩展到其他类型的任务和模型,并与其他置信度评估方法相结合,以实现更鲁棒的性能。
📄 摘要(原文)
Large language models (LLMs) have demonstrated impressive performance on several tasks and are increasingly deployed in real-world applications. However, especially in high-stakes settings, it becomes vital to know when the output of an LLM may be unreliable. Depending on whether an answer is trustworthy, a system can then choose to route the question to another expert, or otherwise fall back on a safe default behavior. In this work, we study the extent to which LLMs can reliably indicate confidence in their answers, and how this notion of confidence can translate into downstream accuracy gains. We propose Self-Reflection with Error-based Feedback (Self-REF), a lightweight training strategy to teach LLMs to express confidence in whether their answers are correct in a reliable manner. Self-REF introduces confidence tokens into the LLM, from which a confidence score can be extracted. Compared to conventional approaches such as verbalizing confidence and examining token probabilities, we demonstrate empirically that confidence tokens show significant improvements in downstream routing and rejection learning tasks.