Atomic Calibration of LLMs in Long-Form Generations
作者: Caiqi Zhang, Ruihan Yang, Zhisong Zhang, Xinting Huang, Sen Yang, Dong Yu, Nigel Collier
分类: cs.CL, cs.AI
发布日期: 2024-10-17 (更新: 2025-11-20)
备注: ACL 2025 KnowFM Oral / AACL-IJCNLP 2025
💡 一句话要点
提出原子校准方法,评估LLM在长文本生成中细粒度的幻觉问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 长文本生成 置信度校准 幻觉问题 原子校准
📋 核心要点
- 现有LLM置信度校准主要集中在短文本任务的宏观层面,无法有效评估长文本中细粒度的幻觉问题。
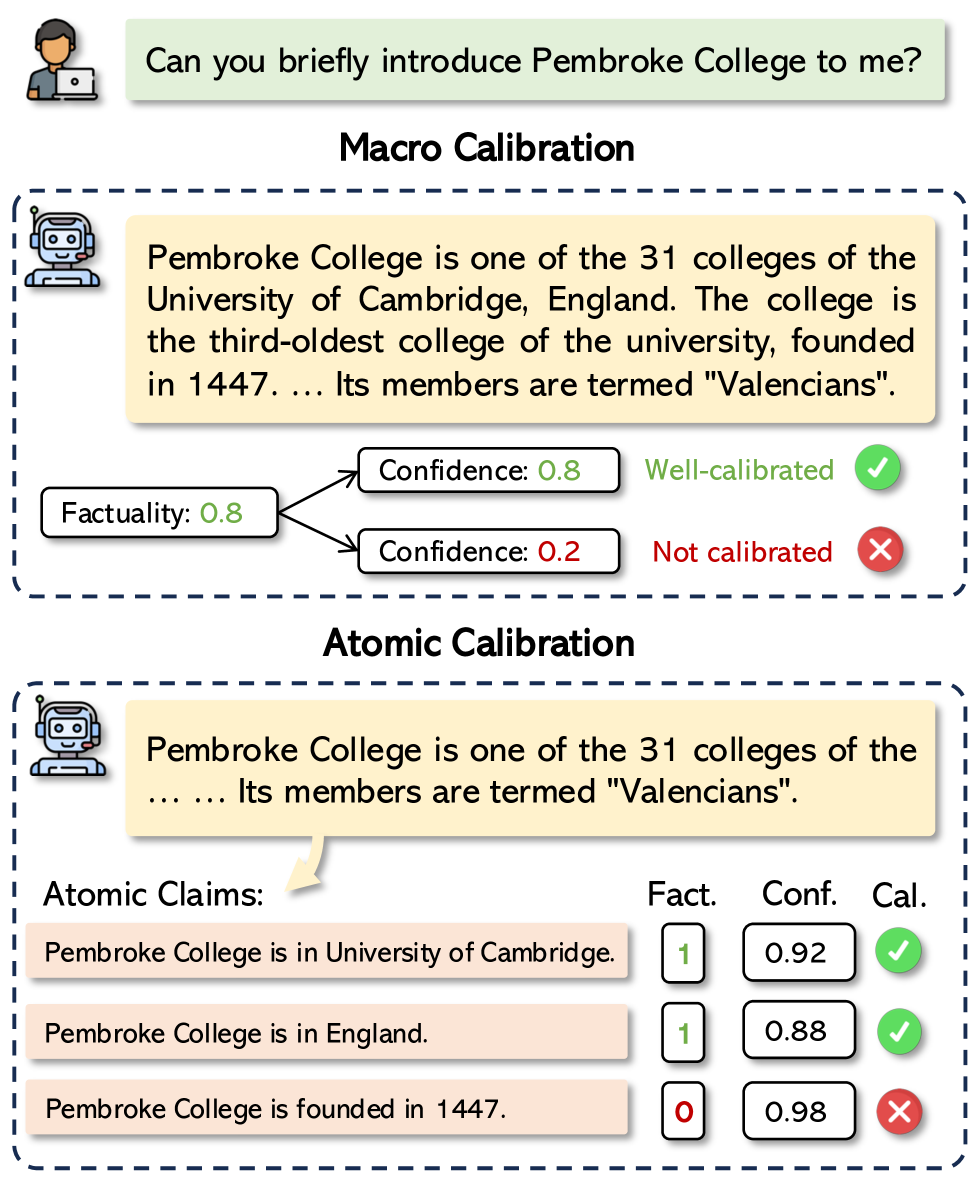
- 论文提出原子校准方法,将长文本分解为原子声明,在细粒度层面评估LLM的事实性置信度。
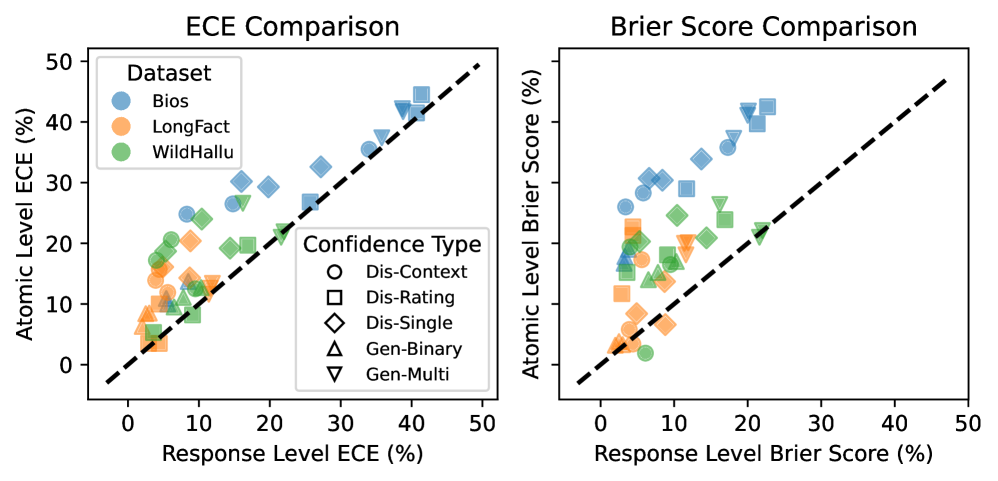
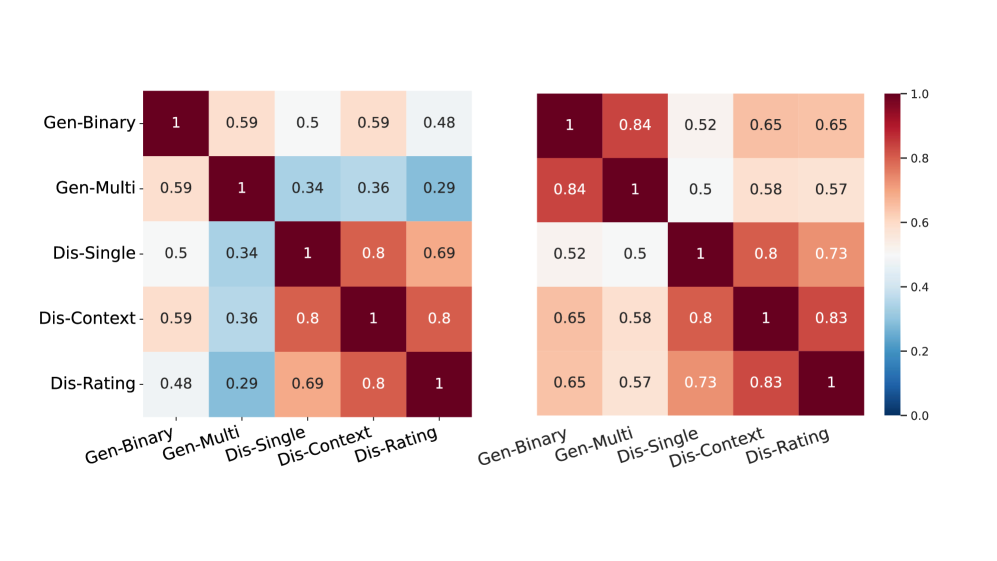
- 实验表明LLM在原子级别校准效果较差,原子校准揭示了置信度方法对齐和生成过程中置信度变化的模式。
📝 摘要(中文)
大型语言模型(LLMs)常常出现幻觉问题,这对实际应用构成了重大挑战。置信度校准是幻觉的有效指标,因此对于提高LLMs的可信度至关重要。先前的工作主要集中在使用单一响应级别分数(宏校准)的短文本任务上,这不足以应对可能包含准确和不准确声明的长文本输出。本文系统地研究了原子校准,通过将长文本响应分解为原子声明,从而在细粒度级别评估事实性校准。此外,我们将现有的置信度提取方法分为判别式和生成式两种类型,并提出了两种新的置信度融合策略来提高校准效果。实验表明,LLMs在长文本生成过程中,原子级别的校准效果较差。更重要的是,原子校准揭示了关于置信度方法对齐以及生成过程中置信度变化的深刻模式。这为长文本生成中置信度估计的未来研究方向提供了启示。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在长文本生成中存在的幻觉问题,并提升模型的可信度。现有方法主要关注短文本任务,采用单一响应级别的置信度评分(宏校准),无法有效检测和评估长文本中可能存在的细粒度错误信息(原子声明级别的错误)。因此,如何对长文本生成进行细粒度的置信度校准是本文要解决的核心问题。
核心思路:论文的核心思路是将长文本响应分解为多个原子声明,并在原子声明级别上进行事实性校准。通过这种细粒度的评估方式,可以更准确地识别长文本生成中的幻觉问题,并为后续的置信度提升提供更精确的指导。同时,论文还研究了不同置信度提取方法(判别式和生成式)的特点,并提出了新的置信度融合策略。
技术框架:论文的技术框架主要包括以下几个步骤:1) 长文本生成:使用LLM生成长文本响应。2) 原子声明分解:将生成的长文本响应分解为多个原子声明。3) 置信度提取:使用判别式或生成式方法提取每个原子声明的置信度。4) 置信度融合:使用提出的融合策略将不同方法的置信度进行融合。5) 校准评估:使用原子校准方法评估LLM的事实性校准效果。
关键创新:论文最重要的技术创新点在于提出了原子校准方法,这是一种细粒度的置信度校准方法,可以有效评估LLM在长文本生成中的幻觉问题。与现有宏校准方法相比,原子校准能够更准确地识别长文本中的错误信息,并为后续的置信度提升提供更精确的指导。此外,论文还提出了两种新的置信度融合策略,进一步提升了校准效果。
关键设计:论文的关键设计包括:1) 原子声明分解策略:如何将长文本分解为合适的原子声明,需要考虑声明的粒度和完整性。2) 置信度提取方法选择:根据任务特点选择合适的判别式或生成式置信度提取方法。3) 置信度融合策略设计:如何有效地融合不同方法的置信度,需要考虑不同方法的特点和权重。4) 校准评估指标选择:选择合适的校准评估指标,如ECE(Expected Calibration Error)和MCE(Maximum Calibration Error),来评估校准效果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM在长文本生成过程中,原子级别的校准效果明显差于宏观级别。通过原子校准,论文揭示了不同置信度提取方法在长文本生成中的表现差异,以及生成过程中置信度的变化趋势。这些发现为未来研究长文本生成中的置信度估计和幻觉抑制提供了重要的参考。
🎯 应用场景
该研究成果可应用于各种需要LLM生成长文本的场景,例如自动报告生成、文章创作、问答系统等。通过提高LLM在长文本生成中的置信度校准,可以减少幻觉问题,提高生成文本的可靠性和可信度,从而增强用户体验和决策支持。
📄 摘要(原文)
Large language models (LLMs) often suffer from hallucinations, posing significant challenges for real-world applications. Confidence calibration, as an effective indicator of hallucination, is thus essential to enhance the trustworthiness of LLMs. Prior work mainly focuses on short-form tasks using a single response-level score (macro calibration), which is insufficient for long-form outputs that may contain both accurate and inaccurate claims. In this work, we systematically study atomic calibration, which evaluates factuality calibration at a fine-grained level by decomposing long responses into atomic claims. We further categorize existing confidence elicitation methods into discriminative and generative types, and propose two new confidence fusion strategies to improve calibration. Our experiments demonstrate that LLMs exhibit poorer calibration at the atomic level during long-form generation. More importantly, atomic calibration uncovers insightful patterns regarding the alignment of confidence methods and the changes of confidence throughout generation. This sheds light on future research directions for confidence estimation in long-form generation.