FaithBench: A Diverse Hallucination Benchmark for Summarization by Modern LLMs
作者: Forrest Sheng Bao, Miaoran Li, Renyi Qu, Ge Luo, Erana Wan, Yujia Tang, Weisi Fan, Manveer Singh Tamber, Suleman Kazi, Vivek Sourabh, Mike Qi, Ruixuan Tu, Chenyu Xu, Matthew Gonzales, Ofer Mendelevitch, Amin Ahmad
分类: cs.CL, cs.AI
发布日期: 2024-10-17
🔗 代码/项目: GITHUB
💡 一句话要点
FaithBench:针对现代LLM摘要幻觉的多元化评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 摘要生成 幻觉检测 评测基准 检索增强生成
📋 核心要点
- 现有LLM摘要幻觉评估缺乏多样性和时效性,难以全面评估新型LLM。
- FaithBench构建包含多种LLM生成的、具有挑战性的幻觉摘要数据集,并进行人工标注。
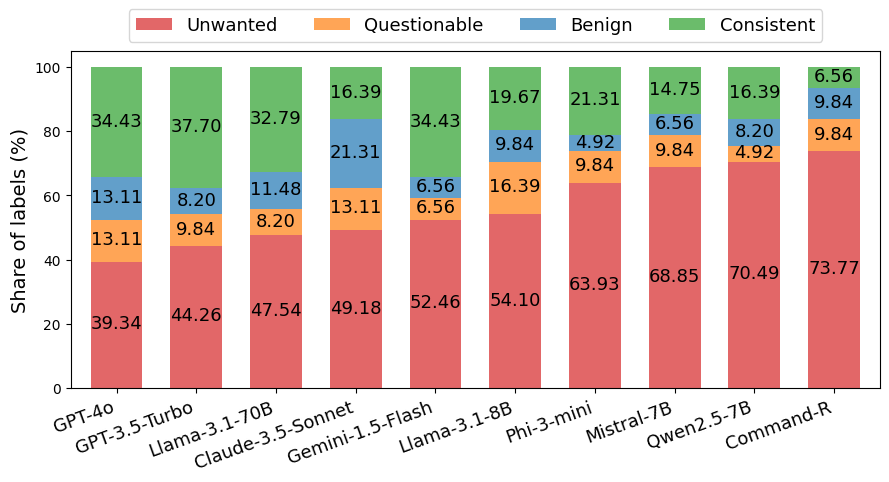
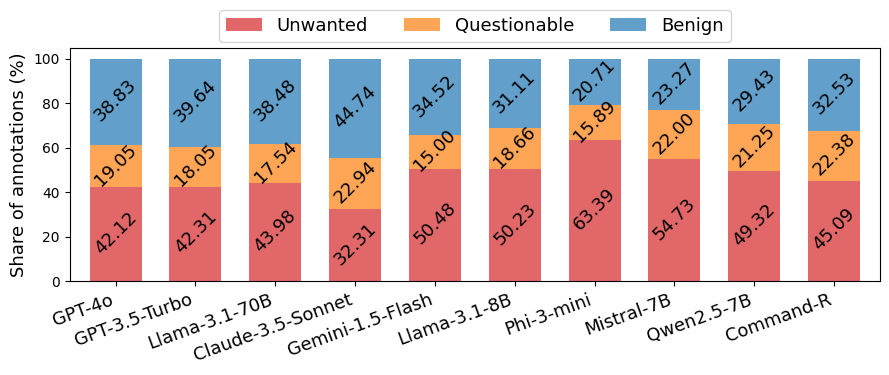
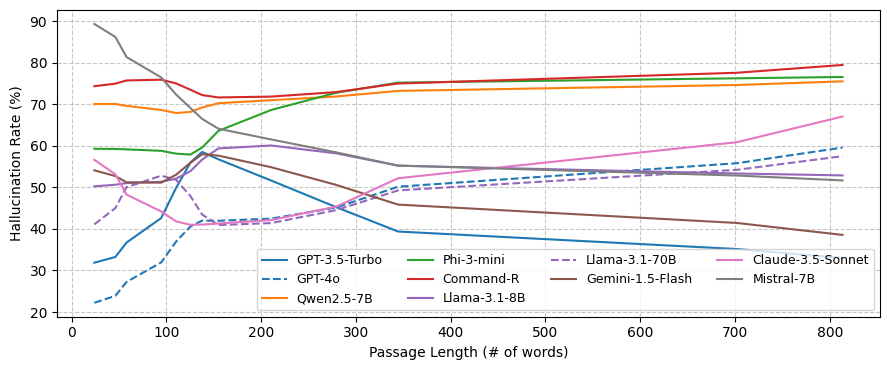
- 实验表明,即使是GPT-4o和GPT-3.5-Turbo等先进模型仍存在幻觉,且现有检测模型准确率有限。
📝 摘要(中文)
大型语言模型(LLM)最常见的任务之一是摘要,尤其是在检索增强生成(RAG)等应用中。然而,现有对LLM生成摘要中幻觉的评估,以及对幻觉检测模型的评估,都缺乏对所考虑的LLM和LLM家族的多样性和新近性。本文介绍了FaithBench,这是一个摘要幻觉基准,包含来自8个不同家族的10个现代LLM产生的具有挑战性的幻觉,并由人类专家进行ground truth标注。“具有挑战性”指的是那些流行的、最先进的幻觉检测模型(包括GPT-4o-as-a-judge)在判断上存在分歧的摘要。我们的结果表明GPT-4o和GPT-3.5-Turbo产生的幻觉最少。然而,即使是最好的幻觉检测模型在FaithBench上的准确率也接近50%,表明未来仍有很大的改进空间。该项目代码库位于https://github.com/vectara/FaithBench。
🔬 方法详解
问题定义:论文旨在解决现有LLM摘要幻觉评估基准缺乏多样性和时效性的问题。现有方法难以充分评估新型LLM的幻觉问题,导致对LLM摘要能力的评估不准确。此外,现有的幻觉检测模型在面对复杂和具有挑战性的幻觉时,表现不佳。
核心思路:论文的核心思路是构建一个包含来自多个现代LLM家族的、具有挑战性的幻觉摘要数据集,并由人工专家进行标注,从而提供一个更全面、更具挑战性的评估基准。通过引入多样化的LLM和具有挑战性的幻觉样本,可以更准确地评估LLM的摘要能力和幻觉检测模型的性能。
技术框架:FaithBench的构建流程主要包括以下几个阶段:1) 选择多个现代LLM家族,并从中选取具有代表性的LLM;2) 使用这些LLM生成摘要;3) 收集生成的摘要,并由人工专家进行标注,标注摘要中是否存在幻觉;4) 筛选出具有挑战性的幻觉样本,即那些现有幻觉检测模型难以达成一致的样本;5) 构建最终的FaithBench基准数据集。
关键创新:FaithBench的关键创新在于其数据集的多样性和挑战性。与现有基准相比,FaithBench包含了更多现代LLM家族,覆盖了更广泛的LLM架构和训练方法。此外,FaithBench专注于那些现有幻觉检测模型难以达成一致的幻觉样本,从而提高了评估的难度和区分度。
关键设计:FaithBench的关键设计包括:1) 选择具有代表性的LLM家族,例如GPT系列、Llama系列等;2) 使用多种摘要方法生成摘要,例如抽取式摘要、生成式摘要等;3) 采用多轮人工标注,确保标注的准确性和一致性;4) 使用多种幻觉检测模型进行初步筛选,选择那些模型之间存在分歧的样本。
🖼️ 关键图片
📊 实验亮点
FaithBench评估结果显示,即使是GPT-4o和GPT-3.5-Turbo等先进LLM仍会产生幻觉。同时,现有最佳幻觉检测模型在FaithBench上的准确率接近50%,表明幻觉检测仍有很大的提升空间。该基准为未来LLM摘要和幻觉检测研究提供了重要的参考。
🎯 应用场景
FaithBench可用于评估和比较不同LLM的摘要能力,并促进幻觉检测模型的发展。该基准可以帮助研究人员更好地理解LLM的幻觉问题,并开发更有效的缓解方法。此外,FaithBench还可以应用于RAG等实际应用中,提高LLM生成摘要的质量和可靠性。
📄 摘要(原文)
Summarization is one of the most common tasks performed by large language models (LLMs), especially in applications like Retrieval-Augmented Generation (RAG). However, existing evaluations of hallucinations in LLM-generated summaries, and evaluations of hallucination detection models both suffer from a lack of diversity and recency in the LLM and LLM families considered. This paper introduces FaithBench, a summarization hallucination benchmark comprising challenging hallucinations made by 10 modern LLMs from 8 different families, with ground truth annotations by human experts. ``Challenging'' here means summaries on which popular, state-of-the-art hallucination detection models, including GPT-4o-as-a-judge, disagreed on. Our results show GPT-4o and GPT-3.5-Turbo produce the least hallucinations. However, even the best hallucination detection models have near 50\% accuracies on FaithBench, indicating lots of room for future improvement. The repo is https://github.com/vectara/FaithBench