BQA: Body Language Question Answering Dataset for Video Large Language Models
作者: Shintaro Ozaki, Kazuki Hayashi, Miyu Oba, Yusuke Sakai, Hidetaka Kamigaito, Taro Watanabe
分类: cs.CL
发布日期: 2024-10-17 (更新: 2025-08-18)
备注: Accepted to ACL2025 (Main)
💡 一句话要点
提出BQA数据集,用于评估视频大语言模型对肢体语言的理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 肢体语言理解 视频大语言模型 问答数据集 情感识别 非语言交流
📋 核心要点
- 现有的视频大语言模型在理解人类非语言交流,特别是肢体语言方面存在不足,容易产生误解。
- 论文提出了BQA数据集,旨在通过问答形式评估模型从肢体语言视频中识别情感的能力。
- 实验结果表明,现有VideoLLM在BQA数据集上表现不佳,且存在基于年龄和种族的偏见。
📝 摘要(中文)
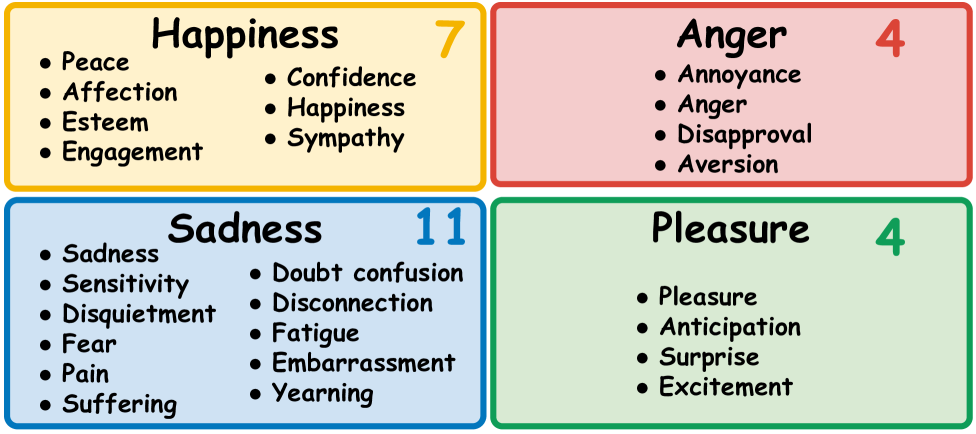
人类交流很大程度上依赖于面部表情、眼神交流和肢体语言等非语言线索。与语言或手语不同,这些非语言交流缺乏正式规则,需要基于常识理解进行复杂推理。使当前的视频大语言模型(VideoLLMs)能够准确地解释肢体语言是一项关键挑战,因为人类无意识的行为很容易导致模型误解他们的意图。为了解决这个问题,我们提出了一个数据集BQA,一个肢体语言问答数据集,以验证模型是否可以正确地从包含26个情感标签的肢体语言视频短片中解释情感。我们评估了各种VideoLLM在BQA上的表现,并揭示了理解肢体语言具有挑战性,我们对VideoLLM错误答案的分析表明,某些VideoLLM根据视频中个体的年龄组和种族做出了显著有偏见的答案。该数据集已公开。
🔬 方法详解
问题定义:论文旨在解决视频大语言模型(VideoLLM)难以准确理解和解释人类肢体语言的问题。现有的VideoLLM在处理非语言交流时,容易受到个体年龄、种族等因素的影响,产生有偏见的判断,缺乏对肢体语言背后复杂情感的准确把握。
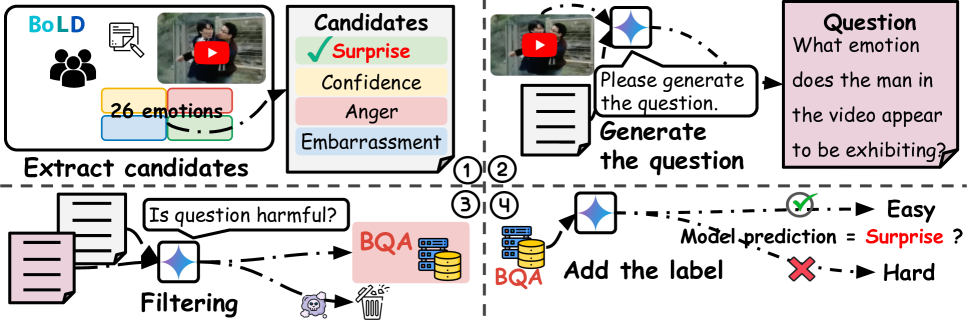
核心思路:论文的核心思路是构建一个专门用于评估VideoLLM对肢体语言理解能力的问答数据集BQA。通过设计包含多种情感表达的肢体语言视频片段,并提出相应的问题,来检验模型是否能够正确识别和理解视频中人物的情感状态。
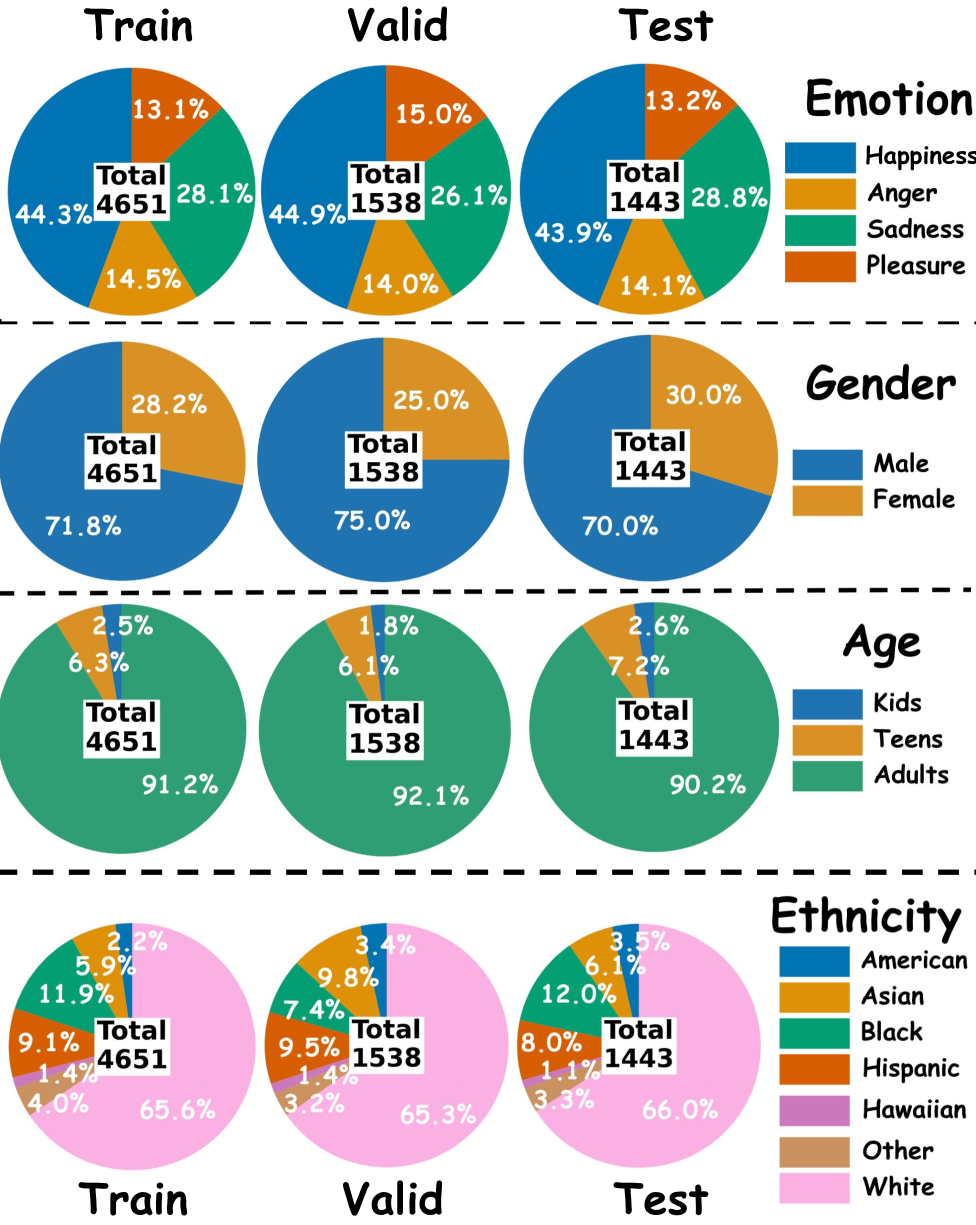
技术框架:BQA数据集包含一系列短视频片段,每个片段展示了人物的肢体语言,并标注了26种情感标签。数据集的设计流程包括:视频收集、情感标注、问题生成和答案验证。研究人员使用BQA数据集对多种VideoLLM进行评估,分析模型的回答结果,并识别模型存在的偏见。
关键创新:BQA数据集的创新之处在于其专注于评估VideoLLM对肢体语言的理解能力,填补了现有数据集在这方面的空白。该数据集不仅包含丰富的情感标签,还关注了模型可能存在的偏见问题,为开发更公平、更准确的VideoLLM提供了数据基础。
关键设计:BQA数据集的关键设计包括:1) 视频片段的选择,确保涵盖多种情感表达和不同人群;2) 情感标签的定义,采用细粒度的情感分类体系;3) 问题的设计,既考察模型对情感的识别能力,又考察模型对情感原因的理解能力;4) 答案的验证,采用人工标注和专家评审相结合的方式,确保答案的准确性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有的VideoLLM在BQA数据集上的表现远低于人类水平,表明理解肢体语言对模型来说仍然是一个巨大的挑战。更重要的是,研究发现某些VideoLLM在回答问题时存在显著的偏见,例如对不同年龄组和种族的人表现出不同的情感倾向。这些发现突出了开发更公平、更可靠的VideoLLM的重要性。
🎯 应用场景
该研究成果可应用于人机交互、情感计算、心理学研究等领域。通过提高VideoLLM对肢体语言的理解能力,可以开发更自然、更智能的人机交互系统,例如情感感知机器人、智能客服等。此外,该数据集也可用于研究人类情感表达的规律,为心理学研究提供数据支持。
📄 摘要(原文)
A large part of human communication relies on nonverbal cues such as facial expressions, eye contact, and body language. Unlike language or sign language, such nonverbal communication lacks formal rules, requiring complex reasoning based on commonsense understanding. Enabling current Video Large Language Models (VideoLLMs) to accurately interpret body language is a crucial challenge, as human unconscious actions can easily cause the model to misinterpret their intent. To address this, we propose a dataset, BQA, a body language question answering dataset, to validate whether the model can correctly interpret emotions from short clips of body language comprising 26 emotion labels of videos of body language. We evaluated various VideoLLMs on BQA and revealed that understanding body language is challenging, and our analyses of the wrong answers by VideoLLMs show that certain VideoLLMs made significantly biased answers depending on the age group and ethnicity of the individuals in the video. The dataset is available.