Your Mixture-of-Experts LLM Is Secretly an Embedding Model For Free
作者: Ziyue Li, Tianyi Zhou
分类: cs.CL, cs.LG
发布日期: 2024-10-14 (更新: 2024-10-16)
备注: Code: https://github.com/tianyi-lab/MoE-Embedding
💡 一句话要点
无需微调!MoE LLM的专家路由权重可作为即用型嵌入模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 文本嵌入 路由权重 大型语言模型 无监督学习 语义相似度 MTEB基准
📋 核心要点
- 现有LLM作为嵌入模型时,通常需要额外的微调,限制了其通用性。
- 论文提出利用MoE LLM中专家路由权重作为嵌入模型,无需额外微调。
- 实验表明,结合路由权重和隐藏状态的MoEE方法,显著提升了嵌入性能。
📝 摘要(中文)
大型语言模型(LLM)在生成任务中表现出色,但其仅解码器架构限制了它们作为嵌入模型的潜力,除非进行进一步的表示微调。这是否与它们作为通用模型的声明相矛盾?为了回答这个问题,我们仔细研究了混合专家(MoE)LLM。我们的研究表明,MoE LLM中的专家路由器可以作为即用型嵌入模型,在各种以嵌入为中心的任务中表现出良好的性能,而无需任何微调。此外,我们广泛的分析表明,MoE路由权重(RW)与LLM的隐藏状态(HS)(一种广泛使用的嵌入)互补。与HS相比,我们发现RW对提示的选择更具鲁棒性,并且侧重于高层语义。受此分析的启发,我们提出了MoEE,它结合了RW和HS,与单独使用两者相比,实现了更好的性能。我们对它们的组合和提示策略的探索揭示了一些新的见解,例如,RW和HS相似度的加权和优于它们连接后的相似度。我们的实验在来自大规模文本嵌入基准(MTEB)的6个嵌入任务和20个数据集上进行。结果表明,MoEE在不进行进一步微调的情况下,显著提高了基于LLM的嵌入性能。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)虽然在生成任务上表现出色,但由于其decoder-only的架构,直接将其用作嵌入模型的效果并不理想,通常需要额外的微调才能获得较好的嵌入表示。现有方法的痛点在于需要额外的计算资源和时间进行微调,限制了LLM的即用性。
核心思路:论文的核心思路是利用MoE(Mixture-of-Experts)LLM中专家路由器的路由权重(Routing Weights, RW)作为一种天然的、无需微调的嵌入表示。作者认为,路由权重反映了输入文本与不同专家之间的关联程度,蕴含了丰富的语义信息,可以作为一种有效的文本嵌入。
技术框架:论文提出的MoEE方法,其整体框架如下:首先,将输入文本输入到MoE LLM中;然后,提取专家路由器的路由权重RW和LLM的隐藏状态HS;最后,将RW和HS进行融合,得到最终的文本嵌入表示。论文探索了多种融合方式,包括拼接(concatenation)和加权求和(weighted sum)。
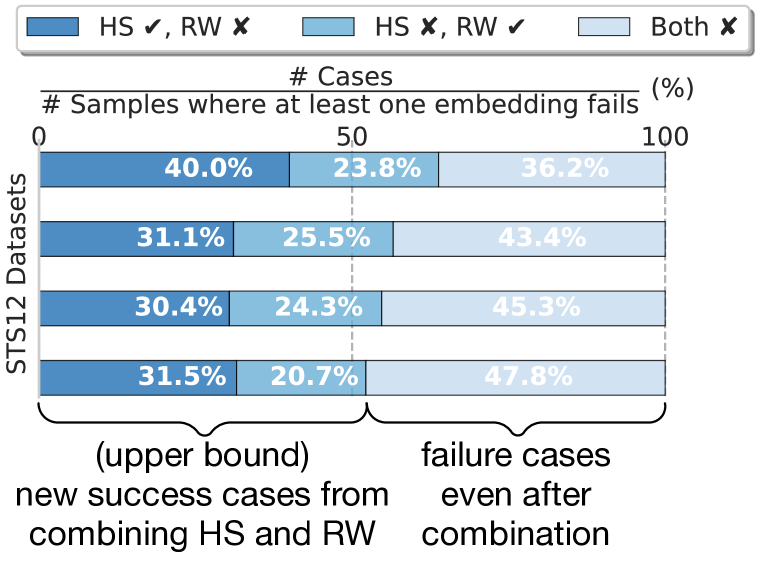
关键创新:论文最重要的技术创新点在于发现并验证了MoE LLM中的路由权重可以作为一种有效的、无需微调的文本嵌入表示。与传统的基于隐藏状态的嵌入方法相比,路由权重对提示的选择更加鲁棒,并且更加关注高层语义信息。此外,论文还提出了结合路由权重和隐藏状态的MoEE方法,进一步提升了嵌入性能。
关键设计:在MoEE方法中,一个关键的设计是路由权重和隐藏状态的融合方式。论文发现,直接拼接RW和HS的效果并不理想,而对它们的相似度进行加权求和可以获得更好的性能。具体的权重参数可以通过实验进行调整。此外,论文还探索了不同的提示策略对嵌入性能的影响,发现合适的提示可以进一步提升嵌入效果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MoE LLM的路由权重可以作为一种有效的文本嵌入表示,无需任何微调。在MTEB基准测试的20个数据集上,MoEE方法显著优于单独使用路由权重或隐藏状态的方法。例如,在某些任务上,MoEE的性能提升超过了5%。此外,实验还表明,MoEE对提示的选择更加鲁棒,并且更加关注高层语义信息。
🎯 应用场景
该研究成果可应用于各种需要文本嵌入的场景,例如文本检索、文本分类、语义相似度计算等。由于无需微调,该方法可以快速部署到新的任务和领域中,降低了使用LLM进行文本嵌入的成本。此外,该研究也为理解MoE LLM的内部机制提供了新的视角。
📄 摘要(原文)
While large language models (LLMs) excel on generation tasks, their decoder-only architecture often limits their potential as embedding models if no further representation finetuning is applied. Does this contradict their claim of generalists? To answer the question, we take a closer look at Mixture-of-Experts (MoE) LLMs. Our study shows that the expert routers in MoE LLMs can serve as an off-the-shelf embedding model with promising performance on a diverse class of embedding-focused tasks, without requiring any finetuning. Moreover, our extensive analysis shows that the MoE routing weights (RW) is complementary to the hidden state (HS) of LLMs, a widely-used embedding. Compared to HS, we find that RW is more robust to the choice of prompts and focuses on high-level semantics. Motivated by the analysis, we propose MoEE combining RW and HS, which achieves better performance than using either separately. Our exploration of their combination and prompting strategy shed several novel insights, e.g., a weighted sum of RW and HS similarities outperforms the similarity on their concatenation. Our experiments are conducted on 6 embedding tasks with 20 datasets from the Massive Text Embedding Benchmark (MTEB). The results demonstrate the significant improvement brought by MoEE to LLM-based embedding without further finetuning.