Denial-of-Service Poisoning Attacks against Large Language Models
作者: Kuofeng Gao, Tianyu Pang, Chao Du, Yong Yang, Shu-Tao Xia, Min Lin
分类: cs.CR, cs.CL
发布日期: 2024-10-14
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于投毒的拒绝服务攻击(P-DoS),突破LLM输出长度限制,提升攻击有效性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 拒绝服务攻击 大型语言模型 投毒攻击 对抗性攻击 模型安全 语音交互 LLM代理
📋 核心要点
- 现有DoS攻击依赖拼写错误或无语义提示,但在语音交互场景下难以实施,且自然指令的重复输出受SFT数据长度限制。
- 提出P-DoS攻击,通过注入精心设计的投毒样本,突破LLM输出长度限制,实现更有效的拒绝服务攻击。
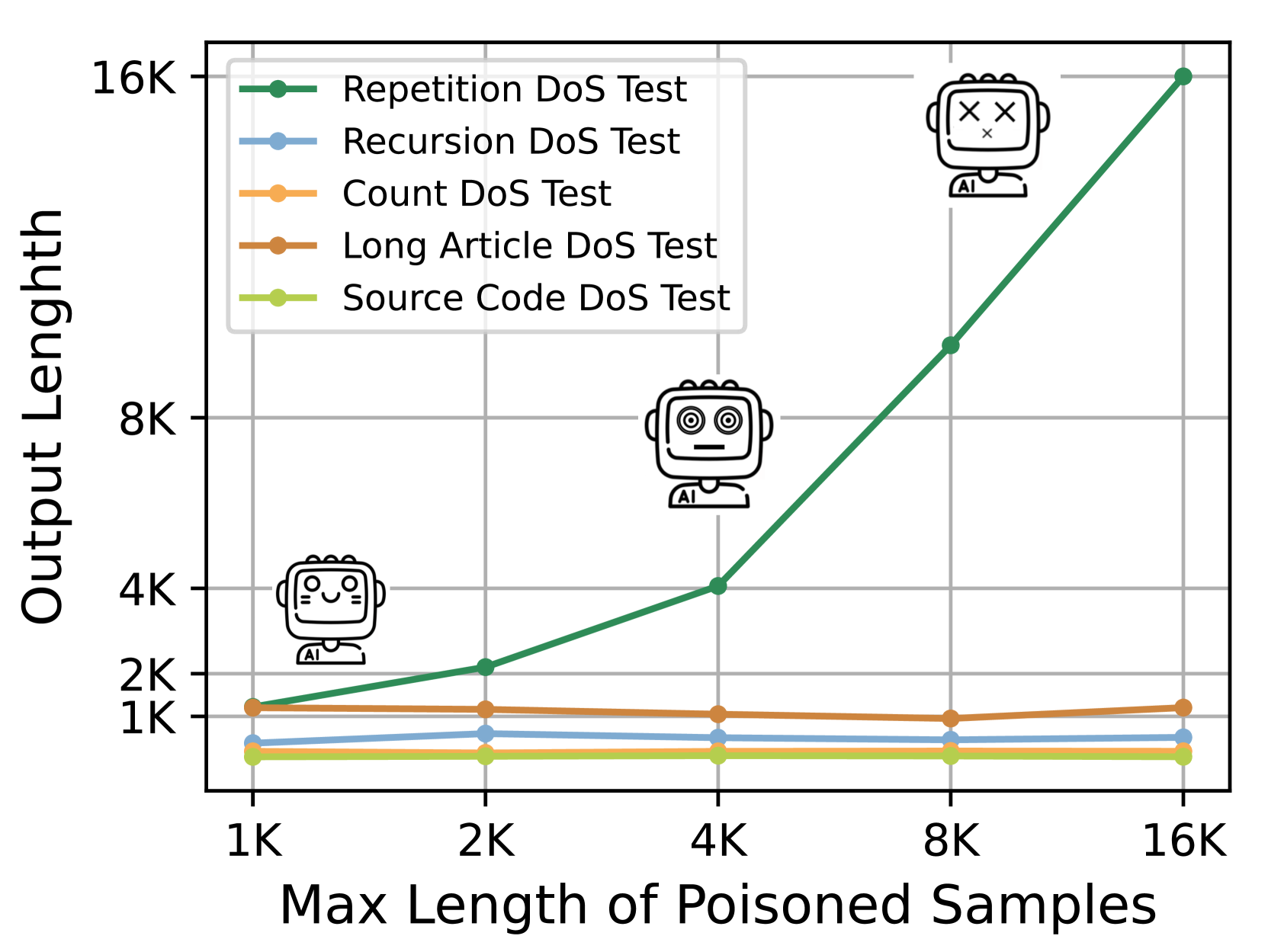
- 实验表明,P-DoS攻击能以低成本攻击GPT-4o等模型,将输出长度从0.5K提升至16K tokens,并扩展到LLM代理。
📝 摘要(中文)
近期研究表明,大型语言模型(LLM)易受拒绝服务(DoS)攻击,恶意输入(如拼写错误或无语义提示)会导致模型无限输出,无法生成[EOS]标记。这些攻击可能导致高延迟,使LLM服务对其他用户或任务不可用。然而,当存在语音转文本接口时(例如,对机器人的语音指令),执行此类DoS攻击变得具有挑战性,因为难以通过语音引入拼写错误或无语义提示。一个简单的DoS攻击是指示模型“不断重复Hello”,但我们观察到,仅依赖自然指令会限制输出长度,该长度受LLM监督微调(SFT)数据的最大长度限制。为了克服这一限制,我们提出了基于投毒的DoS(P-DoS)攻击,证明注入单个为DoS目的设计的投毒样本可以打破输出长度限制。例如,一个投毒样本可以使用不到1美元的成本成功攻击GPT-4o和GPT-4o mini(通过OpenAI的微调API),产生重复输出,直至达到最大推理长度(16K tokens,而投毒前为0.5K)。此外,我们对开源LLM进行了全面的消融研究,并将我们的方法扩展到LLM代理,攻击者可以控制微调数据集和算法。我们的发现强调了迫切需要针对P-DoS攻击的防御措施,以保护LLM的安全。我们的代码可在https://github.com/sail-sg/P-DoS获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在语音交互等场景下,传统拒绝服务(DoS)攻击难以实施,且自然指令重复输出长度受限的问题。现有方法主要依赖于构造包含拼写错误或无意义语句的输入,诱导LLM无限循环输出,但这些方法在语音转文本的场景下难以实现。此外,即使使用自然指令让模型重复输出,其长度也受到监督微调(SFT)数据最大长度的限制,攻击效果不佳。
核心思路:论文的核心思路是利用投毒攻击(Poisoning Attack)来突破LLM的输出长度限制。通过在LLM的微调阶段注入精心设计的恶意样本,使得模型在推理阶段接收到正常输入时,也会产生无限循环的输出,从而达到拒绝服务的目的。这种方法无需依赖特殊的输入构造,也能够突破SFT数据长度的限制。
技术框架:P-DoS攻击主要包含两个阶段:投毒阶段和攻击阶段。在投毒阶段,攻击者首先构造一个包含特定模式的投毒样本,该样本旨在诱导模型产生无限循环的输出。然后,攻击者将该投毒样本注入到LLM的微调数据集中,并使用该数据集对LLM进行微调。在攻击阶段,攻击者向微调后的LLM输入一个正常的查询,由于模型已经被投毒,它会产生无限循环的输出,从而导致拒绝服务。
关键创新:P-DoS攻击的关键创新在于利用投毒攻击来增强LLM的拒绝服务攻击能力。与传统的DoS攻击方法相比,P-DoS攻击不需要构造特殊的输入,也能够突破SFT数据长度的限制,从而实现更有效的攻击。此外,P-DoS攻击还可以扩展到LLM代理,攻击者可以控制微调数据集和算法,从而实现更强大的攻击能力。
关键设计:投毒样本的设计是P-DoS攻击的关键。论文中,投毒样本通常包含一个触发词和一个重复模式。触发词用于激活投毒效果,重复模式则用于诱导模型产生无限循环的输出。例如,一个简单的投毒样本可以是“请重复 ‘Hello’ 直到模型停止”。在微调阶段,需要控制投毒样本的比例,以避免对模型的正常功能产生过大的影响。此外,还可以使用对抗训练等技术来增强投毒效果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,P-DoS攻击能够以极低的成本(小于1美元)成功攻击GPT-4o和GPT-4o mini,将模型的输出长度从0.5K tokens提升至16K tokens,达到了最大推理长度。此外,消融研究验证了P-DoS攻击在开源LLM上的有效性,并成功将其扩展到LLM代理,证明了该攻击方法的通用性和潜在危害。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型在对抗性环境下的鲁棒性。通过模拟P-DoS攻击,可以发现LLM的潜在漏洞,并开发相应的防御机制,例如输入过滤、异常检测和模型强化训练。此外,该研究对于保护基于LLM的语音助手、聊天机器人等应用免受恶意攻击具有重要意义。
📄 摘要(原文)
Recent studies have shown that LLMs are vulnerable to denial-of-service (DoS) attacks, where adversarial inputs like spelling errors or non-semantic prompts trigger endless outputs without generating an [EOS] token. These attacks can potentially cause high latency and make LLM services inaccessible to other users or tasks. However, when there are speech-to-text interfaces (e.g., voice commands to a robot), executing such DoS attacks becomes challenging, as it is difficult to introduce spelling errors or non-semantic prompts through speech. A simple DoS attack in these scenarios would be to instruct the model to "Keep repeating Hello", but we observe that relying solely on natural instructions limits output length, which is bounded by the maximum length of the LLM's supervised finetuning (SFT) data. To overcome this limitation, we propose poisoning-based DoS (P-DoS) attacks for LLMs, demonstrating that injecting a single poisoned sample designed for DoS purposes can break the output length limit. For example, a poisoned sample can successfully attack GPT-4o and GPT-4o mini (via OpenAI's finetuning API) using less than $1, causing repeated outputs up to the maximum inference length (16K tokens, compared to 0.5K before poisoning). Additionally, we perform comprehensive ablation studies on open-source LLMs and extend our method to LLM agents, where attackers can control both the finetuning dataset and algorithm. Our findings underscore the urgent need for defenses against P-DoS attacks to secure LLMs. Our code is available at https://github.com/sail-sg/P-DoS.