Double Jeopardy and Climate Impact in the Use of Large Language Models: Socio-economic Disparities and Reduced Utility for Non-English Speakers
作者: Aivin V. Solatorio, Gabriel Stefanini Vicente, Holly Krambeck, Olivier Dupriez
分类: cs.CL, cs.AI, cs.LG, econ.GN
发布日期: 2024-10-14
备注: Project GitHub repository at https://github.com/worldbank/double-jeopardy-in-llms
💡 一句话要点
揭示大语言模型对非英语用户的双重不利影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 低资源语言 标记化 算法公平性 经济发展 信息获取 跨文化交流
📋 核心要点
- 现有的大语言模型在处理低资源语言时表现不佳,导致非英语用户面临高成本和低效能的双重困境。
- 论文提出通过改进标记化过程和算法设计,旨在降低低收入国家用户的使用成本,提高其语言模型的性能。
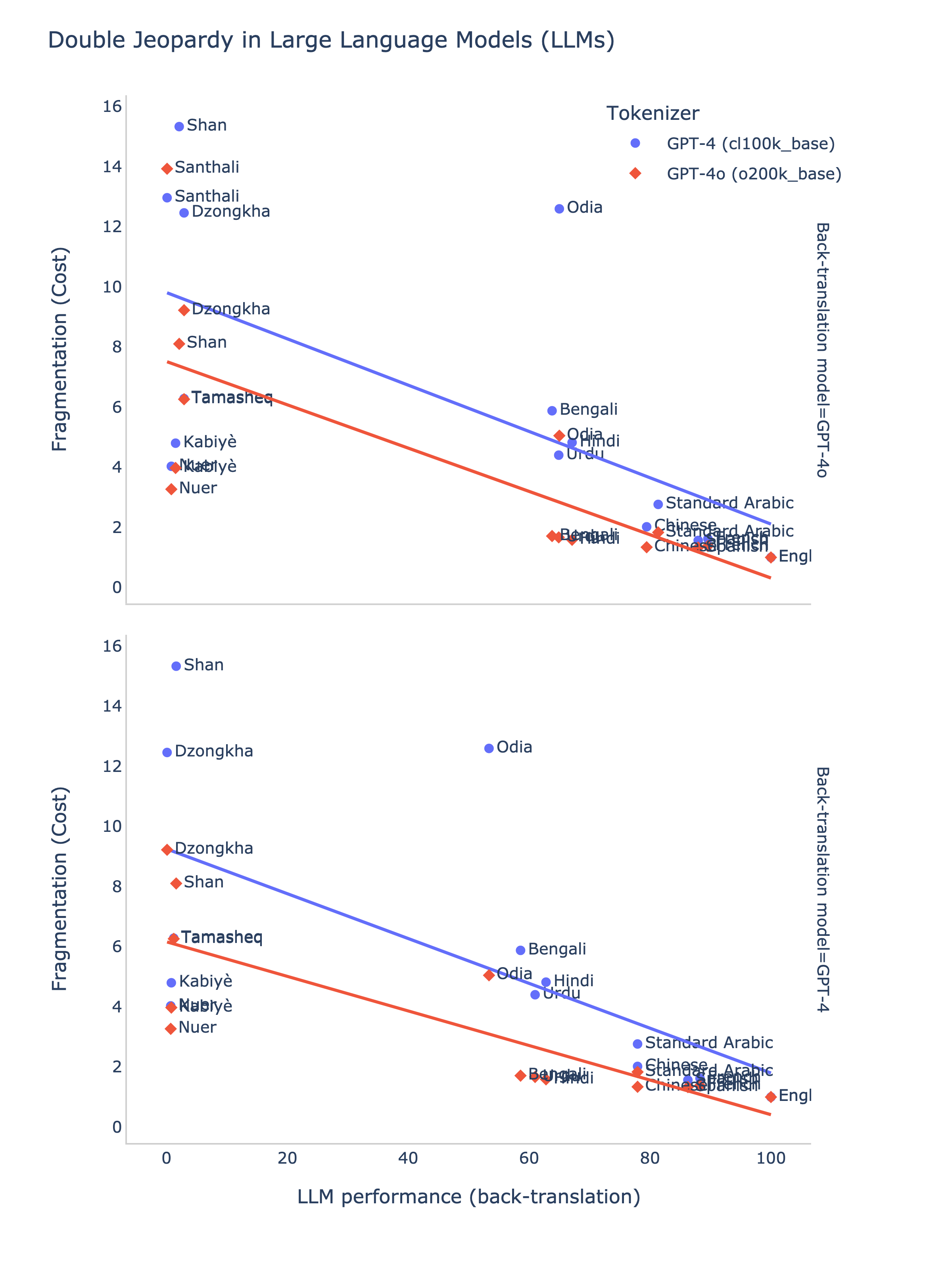
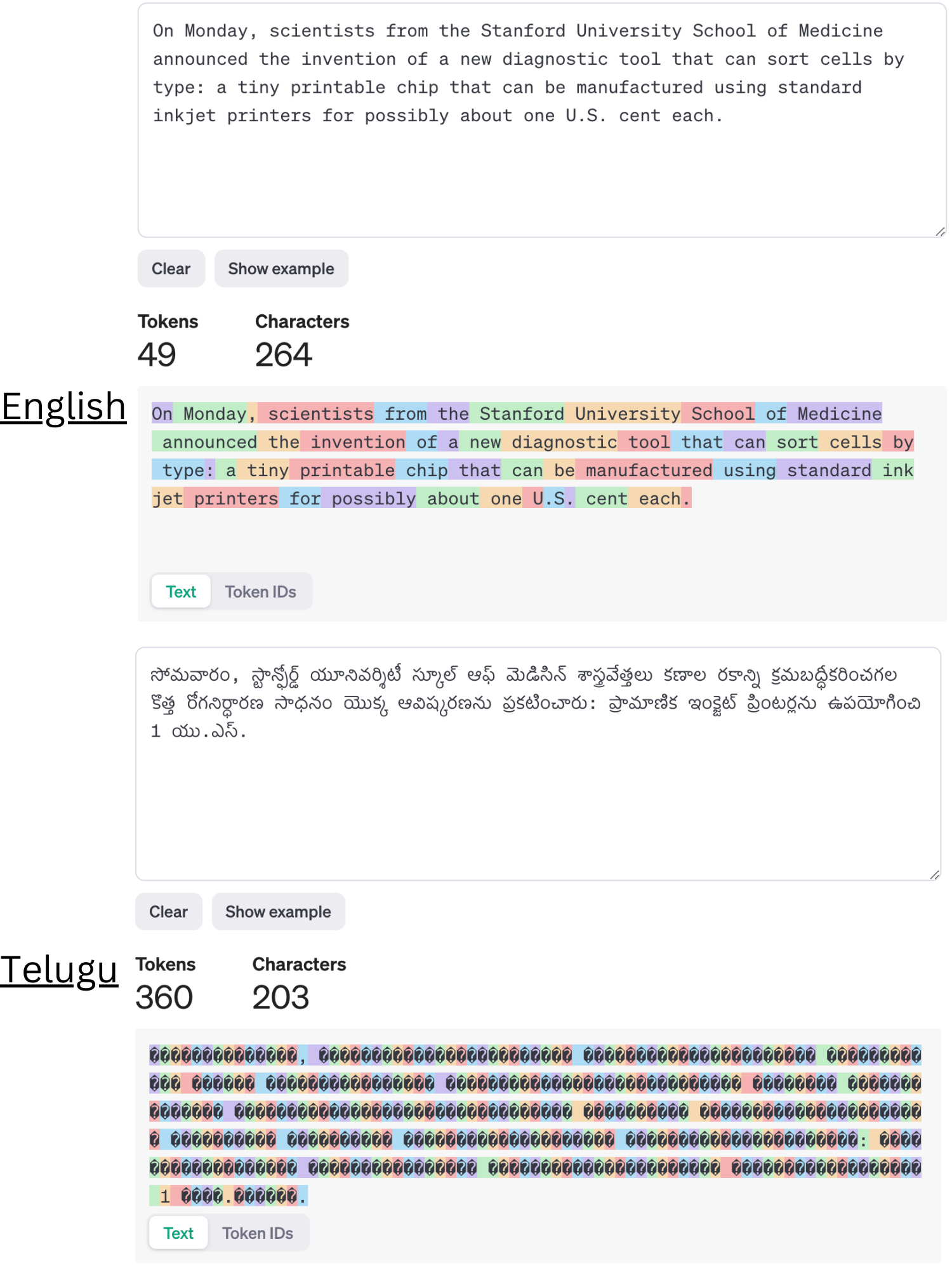
- 研究结果表明,低资源语言用户的使用成本是英语用户的4到6倍,且在翻译任务中表现显著低于英语,凸显了不平等现象。
📝 摘要(中文)
人工智能,尤其是大型语言模型(LLMs),有潜力弥合语言和信息差距,惠及发展中国家的经济。然而,我们对FLORES-200、FLORES+、Ethnologue和世界发展指标数据的分析表明,这些好处主要偏向英语使用者。低收入和中低收入国家的语言使用者在使用OpenAI的GPT模型时面临更高的成本,尤其是在输入处理(标记化)方面。约15亿讲低收入国家语言的人可能面临的成本是英语使用者的4到6倍。LLMs在低资源语言上的表现较差,造成了更高的成本和较差的性能,形成了“双重不利”。此外,低资源语言的标记化碎片化对气候的直接影响也被讨论,强调了公平算法开发的必要性。
🔬 方法详解
问题定义:论文要解决的问题是大型语言模型在低资源语言上的高成本和低性能,现有方法未能有效支持这些语言用户。
核心思路:论文的核心思路是通过优化标记化过程和算法设计,降低低收入国家用户的使用成本,并提升其语言模型的性能。
技术框架:整体架构包括数据收集、标记化优化、模型训练和性能评估四个主要模块。数据收集阶段聚焦于低资源语言的特征,标记化优化阶段则针对不同语言的特性进行调整。
关键创新:最重要的技术创新点在于提出了一种新的标记化策略,能够有效减少低资源语言用户的成本,同时提升模型在这些语言上的表现,与现有方法相比具有显著优势。
关键设计:关键设计包括对标记化算法的参数调整、损失函数的优化,以及网络结构的改进,以适应不同语言的特性,确保模型在低资源语言上的有效性。
🖼️ 关键图片
📊 实验亮点
实验结果显示,低资源语言用户的使用成本是英语用户的4到6倍,且在翻译任务中的表现显著低于英语,表明当前模型在处理低资源语言时存在严重不平等现象。这一发现强调了改进算法的紧迫性。
🎯 应用场景
该研究的潜在应用领域包括多语言翻译、跨文化交流和全球信息获取,尤其是在发展中国家。通过优化大型语言模型的算法,可以为非英语用户提供更公平的技术支持,促进信息的平等获取,进而推动经济发展和社会进步。
📄 摘要(原文)
Artificial Intelligence (AI), particularly large language models (LLMs), holds the potential to bridge language and information gaps, which can benefit the economies of developing nations. However, our analysis of FLORES-200, FLORES+, Ethnologue, and World Development Indicators data reveals that these benefits largely favor English speakers. Speakers of languages in low-income and lower-middle-income countries face higher costs when using OpenAI's GPT models via APIs because of how the system processes the input -- tokenization. Around 1.5 billion people, speaking languages primarily from lower-middle-income countries, could incur costs that are 4 to 6 times higher than those faced by English speakers. Disparities in LLM performance are significant, and tokenization in models priced per token amplifies inequalities in access, cost, and utility. Moreover, using the quality of translation tasks as a proxy measure, we show that LLMs perform poorly in low-resource languages, presenting a ``double jeopardy" of higher costs and poor performance for these users. We also discuss the direct impact of fragmentation in tokenizing low-resource languages on climate. This underscores the need for fairer algorithm development to benefit all linguistic groups.