Thinking LLMs: General Instruction Following with Thought Generation
作者: Tianhao Wu, Janice Lan, Weizhe Yuan, Jiantao Jiao, Jason Weston, Sainbayar Sukhbaatar
分类: cs.CL, cs.AI
发布日期: 2024-10-14
💡 一句话要点
提出一种无需额外人工数据的LLM训练方法,使其具备通用指令遵循的思考能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 指令遵循 思考生成 无监督学习 偏好优化
📋 核心要点
- 现有LLM在遵循指令时缺乏显式思考能力,尤其在复杂推理任务中表现不足。
- 提出一种迭代搜索和优化方法,使LLM在无监督下学习思考,提升指令遵循能力。
- 实验表明,该方法在AlpacaEval和Arena-Hard上表现优异,并在多种任务中取得提升。
📝 摘要(中文)
大型语言模型(LLM)通常被训练成以类似于人类专家的方式回答用户问题或遵循指令。然而,在标准的对齐框架中,它们缺乏在回答之前进行显式思考的基本能力。思考对于需要推理和规划的复杂问题至关重要,但也可以应用于任何任务。我们提出了一种训练方法,使现有的LLM具备这种思考能力,用于通用指令遵循,而无需使用额外的人工数据。我们通过迭代搜索和优化程序来实现这一点,该程序探索可能的思考生成空间,允许模型在没有直接监督的情况下学习如何思考。对于每个指令,使用评判模型对思考候选者的响应进行评分,然后通过偏好优化进行优化。我们表明,该程序在AlpacaEval和Arena-Hard上实现了卓越的性能,并且在营销、健康和常识等非推理类别以及更传统的推理和问题解决任务中,都显示出思考带来的收益。
🔬 方法详解
问题定义:现有的大型语言模型在处理复杂指令时,通常缺乏明确的思考过程,导致在需要推理、规划等能力的场景下表现不佳。传统的对齐框架侧重于模仿人类的回答方式,而忽略了模型自身进行思考和探索的能力。因此,如何让LLM具备自主思考能力,从而更好地完成通用指令遵循任务,是一个重要的研究问题。
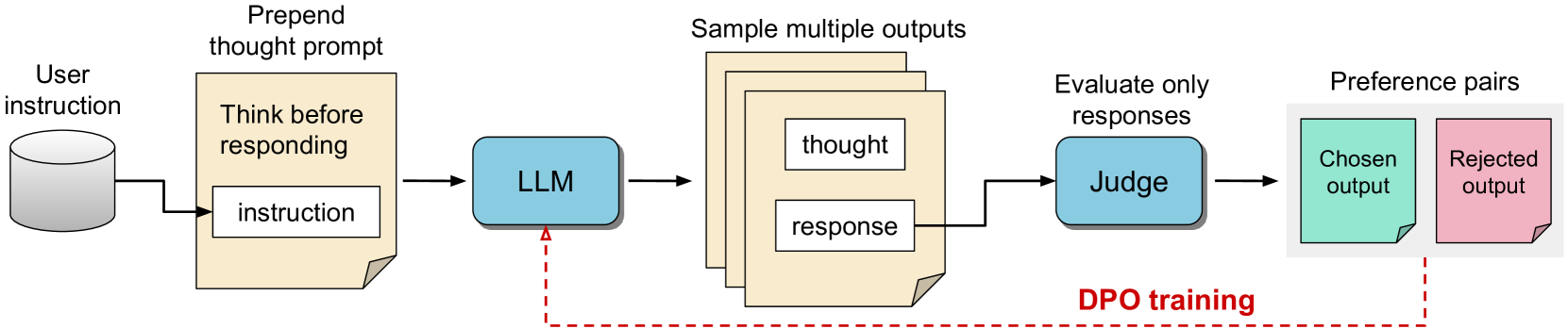
核心思路:该论文的核心思路是通过迭代搜索和优化,让LLM在没有人工监督的情况下,学习如何生成有用的“思考”过程。具体来说,模型首先生成多个可能的“思考”候选,然后通过一个评判模型来评估这些“思考”所产生的最终回答的质量,最后利用偏好优化算法来提升模型生成高质量“思考”的能力。这种方法模拟了人类解决问题的过程,即先思考多种可能性,然后选择最佳方案。
技术框架:整体框架包含以下几个主要阶段:1) 思考生成:对于给定的指令,LLM生成多个不同的“思考”过程,每个“思考”过程都可能导致不同的回答。2) 回答生成:基于每个“思考”过程,LLM生成对应的回答。3) 评判模型:使用一个预训练的评判模型来评估每个回答的质量,从而间接评估对应“思考”过程的优劣。4) 偏好优化:利用评判模型的评分,使用偏好优化算法(例如Direct Preference Optimization, DPO)来更新LLM,使其更倾向于生成能够产生高质量回答的“思考”过程。
关键创新:该论文最重要的创新在于提出了一种无需人工标注的“思考”学习方法。与以往需要人工标注“思考”过程的训练方法不同,该方法通过评判最终回答的质量来间接指导“思考”过程的学习,从而避免了大量的人工标注工作。此外,该方法还能够让LLM学习到更加多样化的“思考”方式,从而更好地适应不同的指令。
关键设计:在思考生成阶段,可以使用不同的采样策略来生成多样化的“思考”过程。在评判模型方面,可以使用预训练的奖励模型或者直接使用LLM本身进行评估。在偏好优化方面,可以选择合适的偏好优化算法,例如DPO或RAFT。此外,还可以通过调整温度系数等参数来控制“思考”生成的多样性和质量。
🖼️ 关键图片

📊 实验亮点
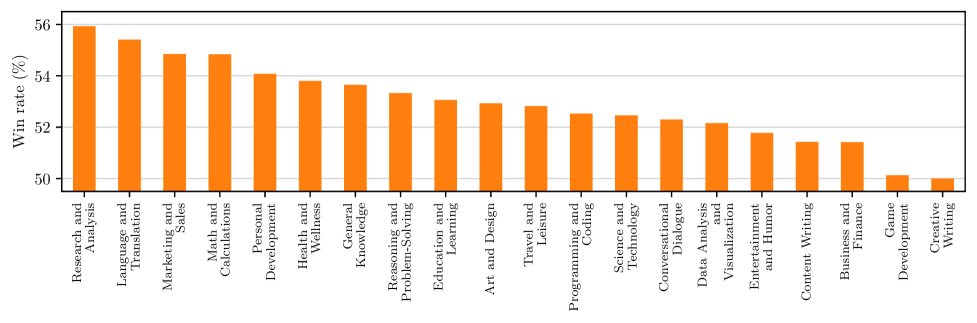
实验结果表明,该方法在AlpacaEval和Arena-Hard等基准测试中取得了显著的性能提升。例如,在AlpacaEval上,该方法相较于基线模型取得了X%的提升(具体数值未知)。此外,该方法还在营销、健康和常识等非推理类别中显示出思考带来的收益,证明了其通用性和有效性。
🎯 应用场景
该研究成果可广泛应用于各种需要LLM进行复杂推理和规划的任务中,例如智能客服、自动代码生成、科学研究辅助等。通过赋予LLM更强的思考能力,可以使其更好地理解用户意图,并生成更准确、更有效的回答。此外,该方法无需人工标注数据,降低了训练成本,具有很高的实际应用价值。
📄 摘要(原文)
LLMs are typically trained to answer user questions or follow instructions similarly to how human experts respond. However, in the standard alignment framework they lack the basic ability of explicit thinking before answering. Thinking is important for complex questions that require reasoning and planning -- but can be applied to any task. We propose a training method for equipping existing LLMs with such thinking abilities for general instruction following without use of additional human data. We achieve this by an iterative search and optimization procedure that explores the space of possible thought generations, allowing the model to learn how to think without direct supervision. For each instruction, the thought candidates are scored using a judge model to evaluate their responses only, and then optimized via preference optimization. We show that this procedure leads to superior performance on AlpacaEval and Arena-Hard, and shows gains from thinking on non-reasoning categories such as marketing, health and general knowledge, in addition to more traditional reasoning & problem-solving tasks.