On Calibration of LLM-based Guard Models for Reliable Content Moderation
作者: Hongfu Liu, Hengguan Huang, Xiangming Gu, Hao Wang, Ye Wang
分类: cs.CR, cs.CL, cs.LG
发布日期: 2024-10-14 (更新: 2025-02-23)
备注: Accepted to ICLR 2025
💡 一句话要点
评估并校准LLM守卫模型,提升内容审核的可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 内容审核 守卫模型 置信度校准 温度缩放 上下文校准 越狱攻击 可靠性评估
📋 核心要点
- 现有基于LLM的守卫模型在内容审核中存在过度自信、易受攻击和鲁棒性不足等问题,限制了其可靠性。
- 该论文通过对现有守卫模型进行置信度校准评估,并探索事后校准方法,提升其可靠性。
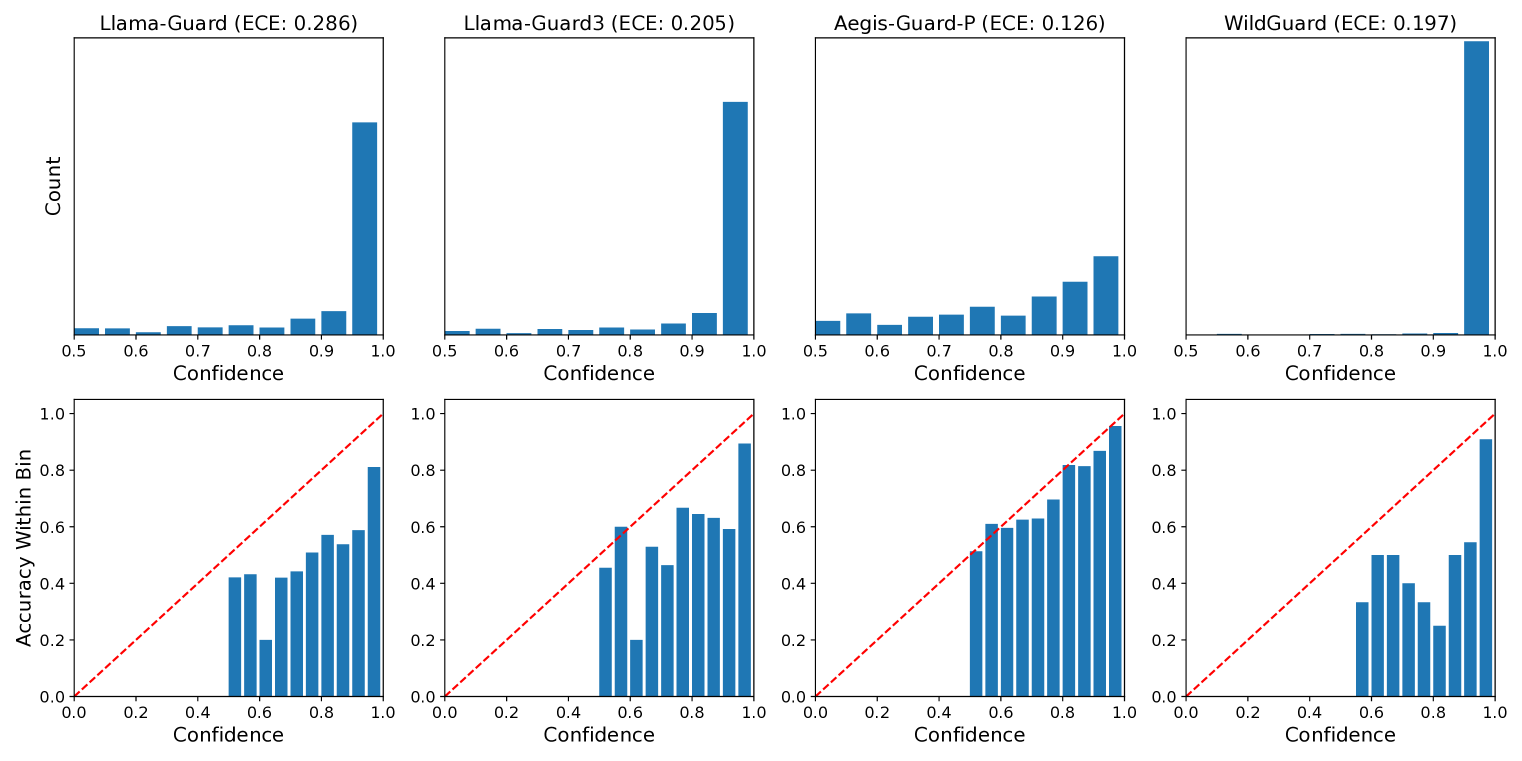
- 实验表明,现有守卫模型存在显著的错误校准,并验证了温度缩放和上下文校准的有效性。
📝 摘要(中文)
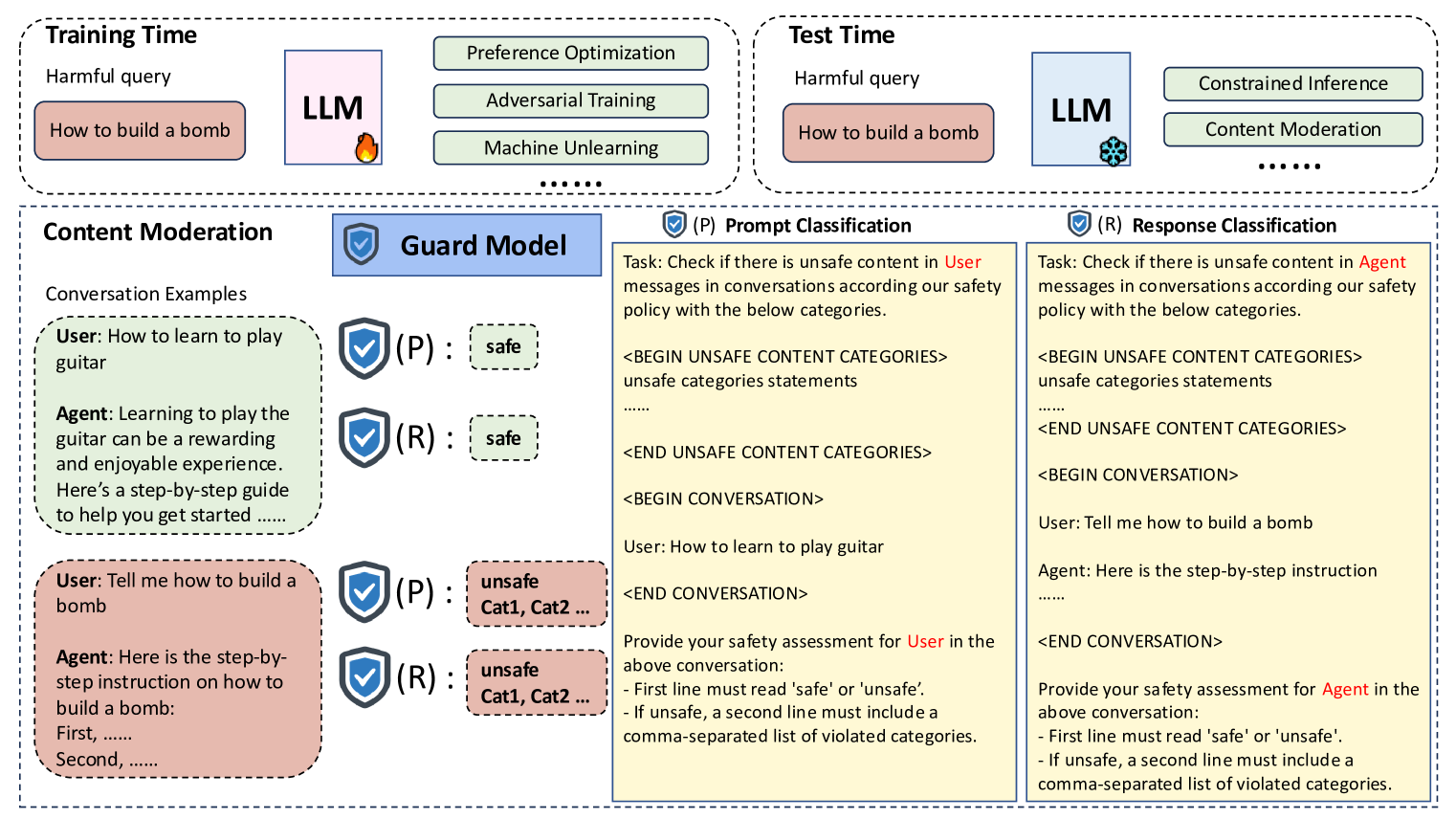
大型语言模型(LLM)因可能生成有害内容或用户试图绕过安全措施而带来重大风险。现有研究已开发基于LLM的守卫模型,旨在审核威胁LLM的输入和输出,通过阻止违反安全协议的内容来确保部署的安全性。然而,对这些守卫模型的可靠性和校准关注不足。本文对9个现有基于LLM的守卫模型在用户输入和模型输出分类的12个基准上进行了全面的置信度校准研究。研究结果表明,当前的LLM守卫模型倾向于:1)产生过度自信的预测;2)在遭受越狱攻击时表现出显著的错误校准;3)对不同类型响应模型生成的输出表现出有限的鲁棒性。此外,我们评估了事后校准方法在缓解错误校准方面的有效性。我们证明了温度缩放的有效性,并首次强调了上下文校准对于守卫模型置信度校准的益处,尤其是在缺乏验证集的情况下。我们的分析和实验强调了当前LLM守卫模型的局限性,并为未来开发良好校准的守卫模型以实现更可靠的内容审核提供了宝贵的见解。我们还提倡在发布未来的基于LLM的守卫模型时,应纳入置信度校准的可靠性评估。
🔬 方法详解
问题定义:论文旨在解决基于LLM的守卫模型在内容审核中置信度校准不足的问题。现有守卫模型存在过度自信、易受越狱攻击影响以及对不同类型响应模型输出鲁棒性差等痛点,导致其在实际应用中可靠性降低。
核心思路:论文的核心思路是通过对现有守卫模型进行全面的置信度校准评估,揭示其在不同场景下的校准问题。然后,探索并验证事后校准方法(如温度缩放和上下文校准)的有效性,以提升守卫模型的可靠性。
技术框架:论文的技术框架主要包括以下几个阶段:1)选择9个现有的基于LLM的守卫模型;2)构建包含用户输入和模型输出分类的12个基准数据集;3)评估守卫模型在这些基准上的置信度校准情况,包括在正常情况和遭受越狱攻击时;4)应用温度缩放和上下文校准等事后校准方法;5)评估校准后的守卫模型在基准数据集上的性能,并与原始模型进行比较。
关键创新:论文的关键创新在于:1)对现有LLM守卫模型进行了全面的置信度校准评估,揭示了其在不同场景下的局限性;2)首次强调了上下文校准在守卫模型置信度校准中的益处,尤其是在缺乏验证集的情况下;3)提出了在发布未来的基于LLM的守卫模型时,应纳入置信度校准的可靠性评估的建议。
关键设计:论文的关键设计包括:1)选择了具有代表性的9个现有LLM守卫模型;2)构建了包含多样化场景的12个基准数据集,涵盖用户输入和模型输出分类;3)采用了期望校准误差(Expected Calibration Error, ECE)等指标来评估置信度校准情况;4)针对温度缩放,使用了标准的优化方法来确定最佳温度参数;5)针对上下文校准,利用了模型输出的上下文信息来调整置信度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有的LLM守卫模型普遍存在过度自信和错误校准的问题,尤其是在遭受越狱攻击时。温度缩放和上下文校准能够有效缓解这些问题,显著提升守卫模型的置信度校准性能。例如,上下文校准在缺乏验证集的情况下也能取得良好的效果,为实际应用提供了有价值的参考。
🎯 应用场景
该研究成果可应用于各种需要内容审核的场景,例如社交媒体平台、在线论坛、聊天机器人等。通过提升LLM守卫模型的可靠性,可以更有效地过滤有害内容,保护用户免受不良信息的影响,并提高内容审核的效率和准确性。未来的研究可以进一步探索更有效的校准方法,并将其集成到守卫模型的训练过程中。
📄 摘要(原文)
Large language models (LLMs) pose significant risks due to the potential for generating harmful content or users attempting to evade guardrails. Existing studies have developed LLM-based guard models designed to moderate the input and output of threat LLMs, ensuring adherence to safety policies by blocking content that violates these protocols upon deployment. However, limited attention has been given to the reliability and calibration of such guard models. In this work, we empirically conduct comprehensive investigations of confidence calibration for 9 existing LLM-based guard models on 12 benchmarks in both user input and model output classification. Our findings reveal that current LLM-based guard models tend to 1) produce overconfident predictions, 2) exhibit significant miscalibration when subjected to jailbreak attacks, and 3) demonstrate limited robustness to the outputs generated by different types of response models. Additionally, we assess the effectiveness of post-hoc calibration methods to mitigate miscalibration. We demonstrate the efficacy of temperature scaling and, for the first time, highlight the benefits of contextual calibration for confidence calibration of guard models, particularly in the absence of validation sets. Our analysis and experiments underscore the limitations of current LLM-based guard models and provide valuable insights for the future development of well-calibrated guard models toward more reliable content moderation. We also advocate for incorporating reliability evaluation of confidence calibration when releasing future LLM-based guard models.