Temperature-Centric Investigation of Speculative Decoding with Knowledge Distillation
作者: Siru Ouyang, Shuohang Wang, Minhao Jiang, Ming Zhong, Donghan Yu, Jiawei Han, Yelong Shen
分类: cs.CL
发布日期: 2024-10-14
备注: EMNLP 2024 Findings
🔗 代码/项目: GITHUB
💡 一句话要点
研究温度对推测解码的影响,提出知识蒸馏在一致温度下的应用以加速高温度生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 推测解码 知识蒸馏 解码温度 语言模型 模型加速
📋 核心要点
- 现有推测解码研究对生成配置,尤其是解码温度的影响理解不足,限制了其在高温度场景下的应用。
- 论文提出在一致温度下进行知识蒸馏,以缓解高温度解码带来的挑战,并探索了域外数据和温度的影响。
- 实验表明,该方法能够有效提升推测解码在高温度生成环境下的效率,为后续研究提供了新思路。
📝 摘要(中文)
推测解码是加速自回归(大型)语言模型推理的关键技术。该方法使用较小的草稿模型来推测一系列token,然后由目标模型评估是否接受。尽管有大量研究旨在提高推测解码的效率,但生成配置(尤其是解码温度)对解码过程的影响仍然知之甚少。本文深入研究了解码温度对推测解码效率的影响。首先,通过知识蒸馏(KD),我们强调了在较高温度下解码的挑战,并证明在一致的温度设置下进行KD可以作为一种补救措施。我们还研究了具有超出范围温度的域外测试集的影响。在此基础上,我们初步尝试进一步提高推测解码的速度,尤其是在高温生成设置中。我们的工作为生成配置如何显著影响推测解码的性能提供了新的见解,并强调需要开发专注于多样化解码配置的方法。代码已公开。
🔬 方法详解
问题定义:论文旨在解决推测解码在高温度生成场景下的效率问题。现有的推测解码方法对解码温度的敏感性较高,尤其是在高温度下,草稿模型的预测质量下降,导致目标模型接受率降低,从而影响整体加速效果。此外,现有方法较少关注不同生成配置(如温度)对推测解码性能的影响,缺乏针对性的优化策略。
核心思路:论文的核心思路是利用知识蒸馏,使草稿模型能够更好地适应目标模型在高温度下的生成分布。通过在一致的温度设置下进行知识蒸馏,可以提高草稿模型在高温度下的预测准确性,从而提高推测解码的接受率和加速效果。同时,论文还探索了域外数据和温度对推测解码的影响,为更鲁棒的推测解码方法设计提供依据。
技术框架:论文的技术框架主要包括以下几个部分:1)使用知识蒸馏训练草稿模型,使其能够模仿目标模型在高温度下的生成行为;2)在推测解码过程中,使用训练好的草稿模型生成候选token序列;3)目标模型对候选token序列进行验证,并根据接受率更新草稿模型;4)实验评估不同温度和数据集下,推测解码的加速效果。
关键创新:论文的关键创新在于:1)首次系统性地研究了解码温度对推测解码性能的影响;2)提出了在一致温度下进行知识蒸馏的方法,以提高草稿模型在高温度下的预测准确性;3)探索了域外数据和温度对推测解码的影响,为更鲁棒的推测解码方法设计提供依据。
关键设计:论文的关键设计包括:1)知识蒸馏的温度设置:选择与目标模型一致的温度进行蒸馏,以保证草稿模型能够学习到目标模型在高温度下的生成分布;2)损失函数的设计:使用交叉熵损失函数来衡量草稿模型和目标模型之间的预测差异;3)实验数据集的选择:使用多个数据集进行评估,包括领域内和领域外的数据,以验证方法的泛化能力。
🖼️ 关键图片

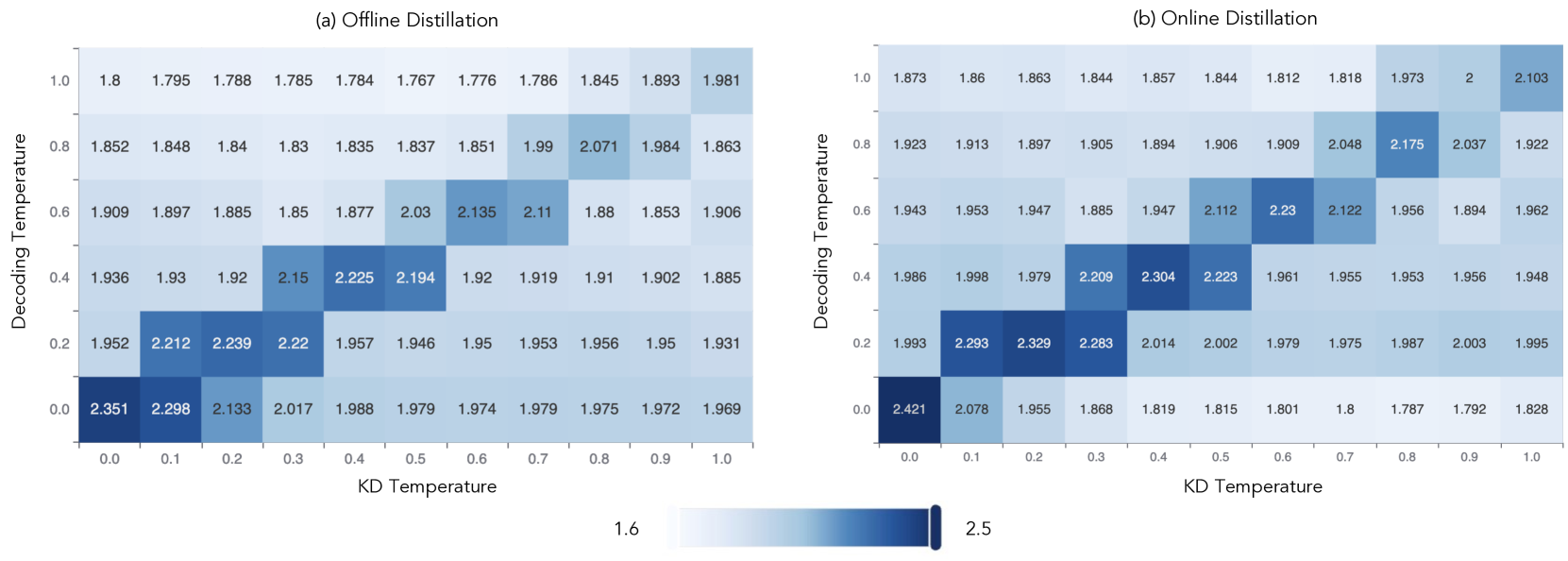

📊 实验亮点
论文通过实验验证了在一致温度下进行知识蒸馏可以有效提高推测解码在高温度生成环境下的效率。具体而言,在高温度设置下,使用知识蒸馏训练的草稿模型相比于未经过蒸馏的模型,能够显著提高目标模型的接受率,从而实现更高的加速效果。此外,论文还发现域外数据和温度对推测解码的性能有显著影响,为后续研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于各种需要加速大型语言模型推理的场景,例如在线对话系统、机器翻译、文本生成等。通过优化推测解码在高温度下的性能,可以提高生成内容的多样性和创造性,同时降低计算成本,具有重要的实际应用价值和商业潜力。
📄 摘要(原文)
Speculative decoding stands as a pivotal technique to expedite inference in autoregressive (large) language models. This method employs a smaller draft model to speculate a block of tokens, which the target model then evaluates for acceptance. Despite a wealth of studies aimed at increasing the efficiency of speculative decoding, the influence of generation configurations on the decoding process remains poorly understood, especially concerning decoding temperatures. This paper delves into the effects of decoding temperatures on speculative decoding's efficacy. Beginning with knowledge distillation (KD), we first highlight the challenge of decoding at higher temperatures, and demonstrate KD in a consistent temperature setting could be a remedy. We also investigate the effects of out-of-domain testing sets with out-of-range temperatures. Building upon these findings, we take an initial step to further the speedup for speculative decoding, particularly in a high-temperature generation setting. Our work offers new insights into how generation configurations drastically affect the performance of speculative decoding, and underscores the need for developing methods that focus on diverse decoding configurations. Code is publically available at https://github.com/ozyyshr/TempSpec.