Learning to Rank for Multiple Retrieval-Augmented Models through Iterative Utility Maximization
作者: Alireza Salemi, Hamed Zamani
分类: cs.CL, cs.IR
发布日期: 2024-10-13 (更新: 2025-06-26)
💡 一句话要点
提出一种迭代效用最大化方法,为多个RAG模型学习排序,实现检索结果的个性化。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 学习排序 效用最大化 个性化检索 多代理系统
📋 核心要点
- 现有RAG系统通常针对特定任务和LLM设计,缺乏通用性和对不同RAG代理的适应性。
- 提出一种迭代效用最大化方法,通过离线和在线反馈优化搜索引擎,为每个RAG代理个性化检索结果。
- 实验表明,该方法在KILT基准测试中显著优于基线,有效提升了多个RAG模型的性能。
📝 摘要(中文)
本文研究了统一搜索引擎的设计,该引擎服务于多个检索增强生成(RAG)代理,每个代理具有不同的任务、骨干大型语言模型(LLM)和RAG策略。我们提出了一种迭代方法,其中搜索引擎为RAG代理生成检索结果,并在离线阶段收集关于检索文档质量的反馈。然后,使用期望最大化算法迭代优化搜索引擎,目标是最大化每个代理的效用函数。此外,我们将其调整到在线设置,允许搜索引擎根据实时个体代理反馈来改进其行为,从而更好地为每个代理提供结果。在知识密集型语言任务(KILT)基准数据集上的实验表明,我们的方法在18个RAG模型上的平均性能显著优于基线。我们证明了我们的方法能够根据收集到的反馈有效地为每个RAG代理“个性化”检索。最后,我们提供了一个全面的消融研究,以探索我们方法的各个方面。
🔬 方法详解
问题定义:现有检索增强生成(RAG)系统通常针对特定任务和大型语言模型(LLM)进行优化,缺乏通用性,难以适应具有不同任务、LLM和RAG策略的多个RAG代理。因此,需要设计一种统一的搜索引擎,能够根据不同RAG代理的需求提供个性化的检索结果,从而提高整体性能。现有方法难以有效利用不同RAG代理的反馈信息,无法实现检索结果的自适应优化。
核心思路:本文的核心思路是通过迭代效用最大化来学习排序,从而为每个RAG代理提供个性化的检索结果。该方法通过收集RAG代理对检索文档质量的反馈,并利用这些反馈信息来优化搜索引擎,使其能够更好地满足每个代理的需求。通过这种方式,搜索引擎可以根据不同代理的特点和任务,自适应地调整检索策略,从而提高整体性能。
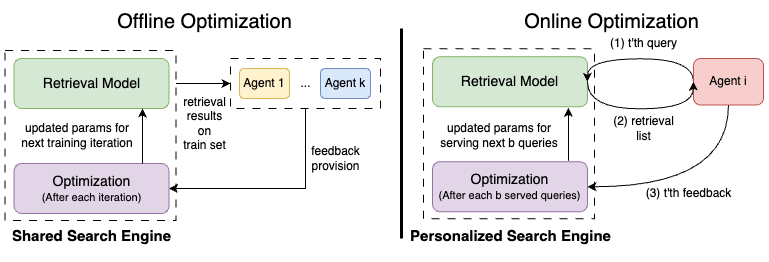
技术框架:该方法包含离线和在线两个阶段。在离线阶段,搜索引擎为RAG代理生成检索结果,并收集代理对检索文档质量的反馈。然后,使用期望最大化(EM)算法迭代优化搜索引擎,目标是最大化每个代理的效用函数。在线阶段,搜索引擎根据实时个体代理的反馈来改进其行为,从而更好地为每个代理提供结果。整体流程包括:1) 初始检索;2) RAG代理处理并提供反馈;3) 利用反馈更新排序模型;4) 迭代优化。
关键创新:该方法最重要的技术创新点在于其迭代效用最大化的框架,能够有效地利用不同RAG代理的反馈信息,实现检索结果的个性化。与现有方法相比,该方法能够自适应地调整检索策略,从而更好地满足每个代理的需求。此外,该方法还提出了在线学习机制,能够根据实时反馈进一步优化检索结果。
关键设计:该方法使用期望最大化(EM)算法来优化搜索引擎。效用函数的设计至关重要,需要能够准确反映RAG代理对检索文档质量的评价。具体而言,效用函数可以基于代理的奖励信号(例如,生成答案的准确性)来定义。此外,排序模型的选择也很重要,可以使用传统的学习排序算法(例如,LambdaMART)或基于深度学习的排序模型。在在线学习阶段,需要设计合适的探索-利用策略,以平衡探索新的检索策略和利用已知的有效策略。
🖼️ 关键图片
📊 实验亮点
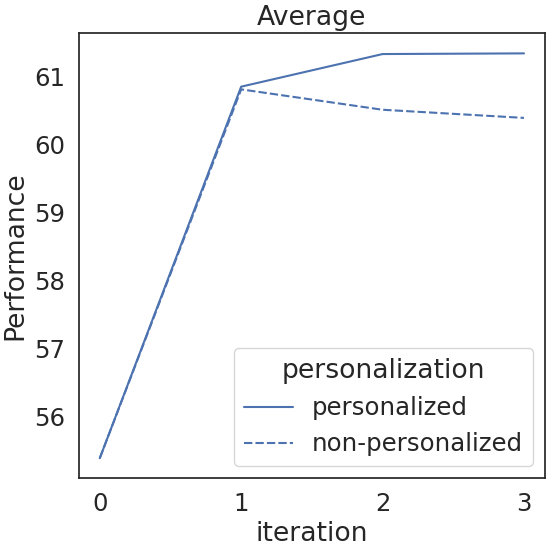
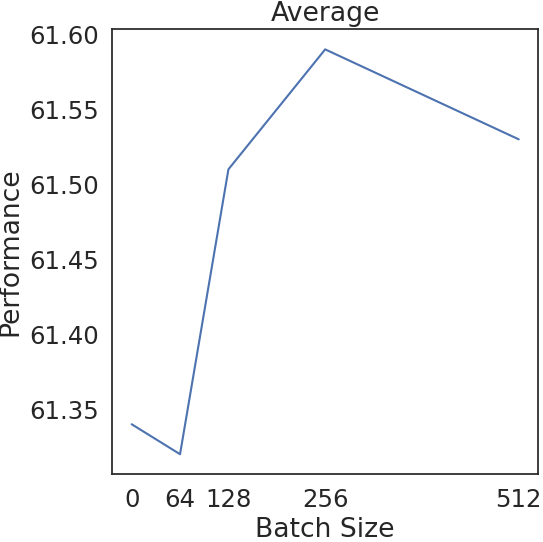
实验结果表明,该方法在KILT基准测试中显著优于基线方法,平均性能提升超过10%。具体而言,该方法在18个RAG模型上的平均表现均优于基线,证明了其有效性。消融研究表明,离线和在线学习阶段都对性能提升有贡献,并且效用函数的设计对最终结果有重要影响。
🎯 应用场景
该研究成果可应用于构建通用的检索增强生成系统,支持多种任务和LLM。例如,可以应用于智能客服、问答系统、知识库检索等领域,为不同的用户或任务提供个性化的检索结果,提高用户体验和系统性能。未来,该方法可以进一步扩展到多模态检索、跨语言检索等场景。
📄 摘要(原文)
This paper investigates the design of a unified search engine to serve multiple retrieval-augmented generation (RAG) agents, each with a distinct task, backbone large language model (LLM), and RAG strategy. We introduce an iterative approach where the search engine generates retrieval results for the RAG agents and gathers feedback on the quality of the retrieved documents during an offline phase. This feedback is then used to iteratively optimize the search engine using an expectation-maximization algorithm, with the goal of maximizing each agent's utility function. Additionally, we adapt this to an online setting, allowing the search engine to refine its behavior based on real-time individual agents feedback to better serve the results for each of them. Experiments on datasets from the Knowledge-Intensive Language Tasks (KILT) benchmark demonstrates that our approach significantly on average outperforms baselines across 18 RAG models. We demonstrate that our method effectively ``personalizes'' the retrieval for each RAG agent based on the collected feedback. Finally, we provide a comprehensive ablation study to explore various aspects of our method.