RMB: Comprehensively Benchmarking Reward Models in LLM Alignment
作者: Enyu Zhou, Guodong Zheng, Binghai Wang, Zhiheng Xi, Shihan Dou, Rong Bao, Wei Shen, Limao Xiong, Jessica Fan, Yurong Mou, Rui Zheng, Tao Gui, Qi Zhang, Xuanjing Huang
分类: cs.CL
发布日期: 2024-10-13 (更新: 2025-04-04)
备注: Accepted by ICLR2025
🔗 代码/项目: GITHUB
💡 一句话要点
RMB:全面评估LLM对齐中奖励模型的基准,揭示现有模型的泛化缺陷。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 LLM对齐 基准测试 泛化能力 生成式模型
📋 核心要点
- 现有奖励模型评估的数据分布有限,评估方法与对齐目标关联性弱,导致评估结果难以反映模型在实际对齐任务中的性能。
- 提出RMB基准,覆盖更广泛的真实场景,采用成对和Best-of-N评估,更贴近实际对齐优化过程,从而更准确地评估奖励模型。
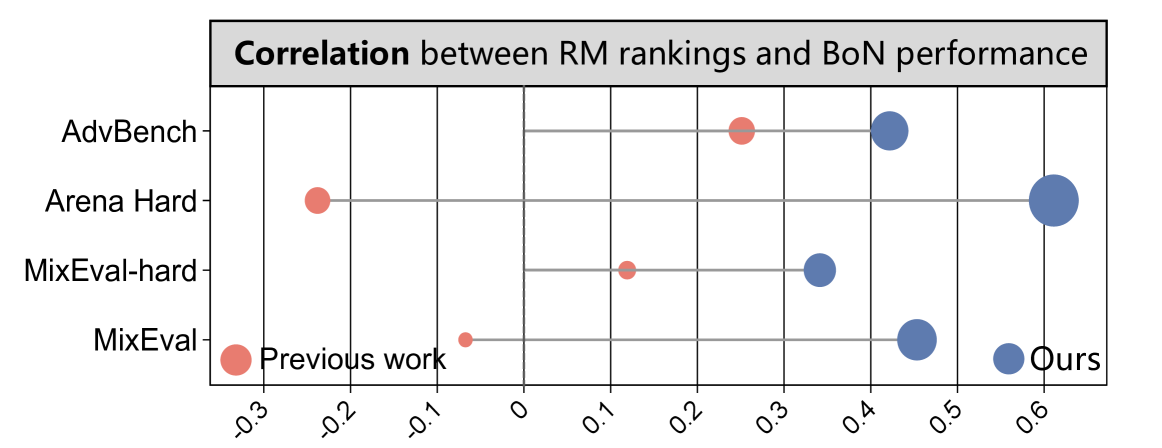
- 实验表明RMB基准与下游对齐任务性能正相关,并揭示了现有奖励模型的泛化缺陷,突出了生成式奖励模型的潜力。
📝 摘要(中文)
奖励模型(RMs)指导大型语言模型(LLMs)的对齐,使其行为符合人类偏好。评估RMs是更好对齐LLMs的关键。然而,由于评估数据的分布有限以及与对齐目标不密切相关的评估方法,当前对RMs的评估可能无法直接反映其对齐性能。为了解决这些限制,我们提出了RMB,一个全面的RM基准,涵盖超过49个真实场景,并包括成对和Best-of-N(BoN)评估,以更好地反映RMs在指导对齐优化方面的有效性。我们证明了我们的基准与下游对齐任务性能之间存在正相关关系。基于我们的基准,我们对最先进的RMs进行了广泛的分析,揭示了先前基准未发现的泛化缺陷,并突出了生成式RMs的潜力。此外,我们深入研究了奖励模型中的开放性问题,特别是检验了多数投票对奖励模型评估的有效性,并分析了生成式RMs的影响因素,包括评估标准和指导方法的影响。我们的评估代码和数据集可在https://github.com/Zhou-Zoey/RMB-Reward-Model-Benchmark获得。
🔬 方法详解
问题定义:现有奖励模型评估方法存在局限性,无法准确反映模型在实际对齐任务中的性能。具体来说,评估数据集覆盖的场景不够广泛,评估指标与对齐目标关联性不强,导致评估结果与实际效果存在偏差。现有方法难以发现奖励模型的泛化缺陷,阻碍了LLM对齐技术的进一步发展。
核心思路:RMB的核心思路是构建一个更全面、更贴近实际应用的奖励模型评估基准。通过扩大评估数据集的覆盖范围,采用更符合对齐目标的评估方法,从而更准确地评估奖励模型的性能,并发现其潜在的泛化缺陷。RMB旨在为奖励模型的研究和开发提供更可靠的评估工具。
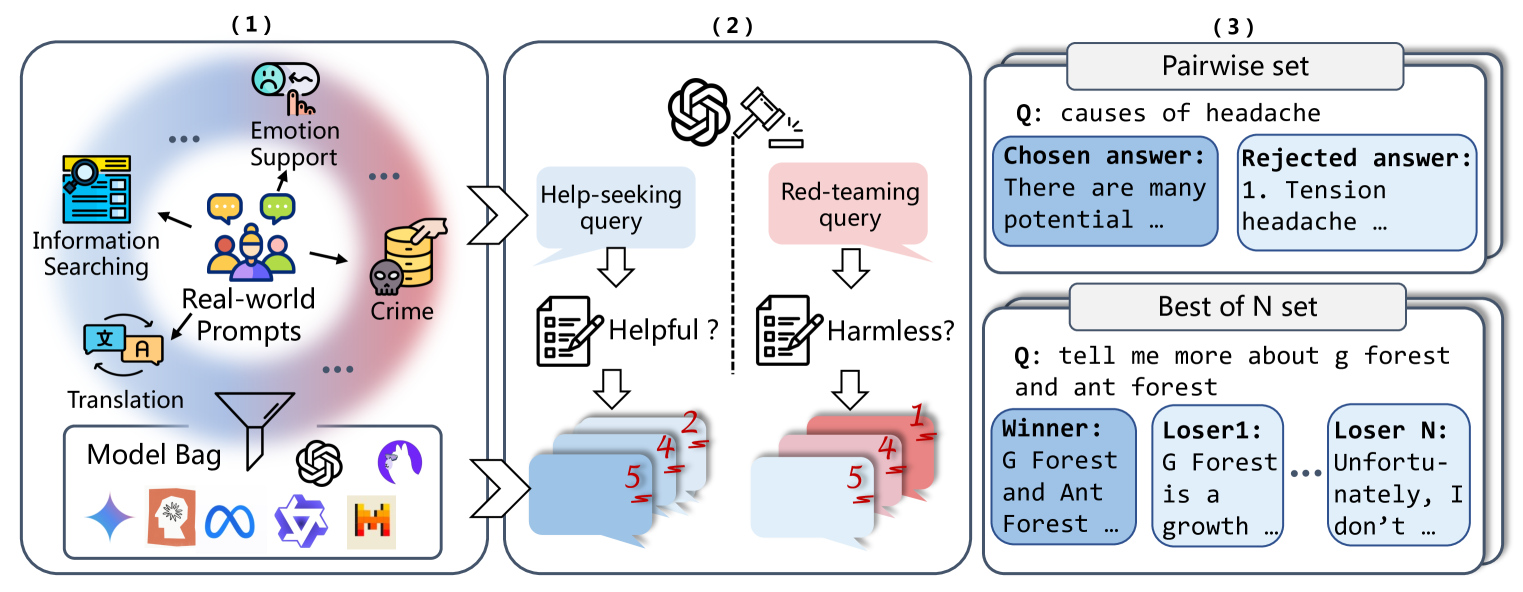
技术框架:RMB基准主要包含以下几个部分:1)构建包含49个真实场景的评估数据集,覆盖更广泛的应用领域;2)采用成对和Best-of-N(BoN)两种评估方法,更贴近实际对齐优化过程;3)设计一套评估指标,用于衡量奖励模型的性能,包括准确率、排序能力等;4)提供评估代码和数据集,方便研究人员使用。
关键创新:RMB的关键创新在于其全面性和实用性。与现有基准相比,RMB覆盖了更广泛的真实场景,采用了更符合对齐目标的评估方法,从而更准确地评估奖励模型的性能。此外,RMB还提供了评估代码和数据集,方便研究人员使用,促进了奖励模型的研究和开发。
关键设计:RMB的关键设计包括:1)数据集的构建,需要精心挑选和标注数据,确保数据的质量和多样性;2)评估方法的选择,需要根据实际应用场景选择合适的评估方法,例如成对比较或Best-of-N;3)评估指标的设计,需要选择能够准确反映奖励模型性能的指标,例如准确率、排序能力等;4)生成式奖励模型的评估,需要考虑评估标准和指导方法的影响。
🖼️ 关键图片

📊 实验亮点
RMB基准揭示了现有奖励模型的泛化缺陷,例如在某些特定场景下性能显著下降。实验表明,RMB基准与下游对齐任务性能之间存在正相关关系,验证了其有效性。此外,研究还发现生成式奖励模型具有潜力,但在评估标准和指导方法方面仍有待进一步研究。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的对齐领域,帮助研究人员更准确地评估和改进奖励模型,从而提升LLM的性能和安全性。RMB基准可以作为评估新奖励模型的标准工具,促进LLM对齐技术的进步。此外,该研究还可以应用于其他需要人类反馈的机器学习任务中。
📄 摘要(原文)
Reward models (RMs) guide the alignment of large language models (LLMs), steering them toward behaviors preferred by humans. Evaluating RMs is the key to better aligning LLMs. However, the current evaluation of RMs may not directly correspond to their alignment performance due to the limited distribution of evaluation data and evaluation methods that are not closely related to alignment objectives. To address these limitations, we propose RMB, a comprehensive RM benchmark that covers over 49 real-world scenarios and includes both pairwise and Best-of-N (BoN) evaluations to better reflect the effectiveness of RMs in guiding alignment optimization. We demonstrate a positive correlation between our benchmark and the downstream alignment task performance. Based on our benchmark, we conduct extensive analysis on the state-of-the-art RMs, revealing their generalization defects that were not discovered by previous benchmarks, and highlighting the potential of generative RMs. Furthermore, we delve into open questions in reward models, specifically examining the effectiveness of majority voting for the evaluation of reward models and analyzing the impact factors of generative RMs, including the influence of evaluation criteria and instructing methods. Our evaluation code and datasets are available at https://github.com/Zhou-Zoey/RMB-Reward-Model-Benchmark.