MIRAGE: Evaluating and Explaining Inductive Reasoning Process in Language Models
作者: Jiachun Li, Pengfei Cao, Zhuoran Jin, Yubo Chen, Kang Liu, Jun Zhao
分类: cs.CL, cs.AI
发布日期: 2024-10-12 (更新: 2025-02-28)
备注: Accepted as ICLR 2025 conference paper (26 pages, 16 tables, 9 figures)
💡 一句话要点
提出MIRAGE数据集,用于评估和解释语言模型中的归纳推理过程。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 归纳推理 大型语言模型 数据集 评估 解释性
📋 核心要点
- 现有工作缺乏对LLM归纳推理能力的全面评估和灵活的测试数据,难以深入分析影响因素。
- MIRAGE数据集通过综合评估归纳和演绎阶段,灵活调整输入分布、任务场景和难度,来分析LLM的归纳推理能力。
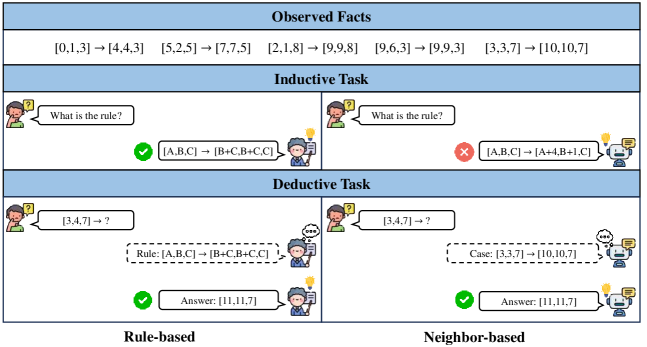
- 实验表明LLM并非优秀的基于规则的推理器,而是更倾向于基于邻近样本进行推理,局部区域内表现较好。
📝 摘要(中文)
本文提出了MIRAGE,一个合成数据集,旨在解决先前工作中存在的局限性,特别是缺乏全面的评估和灵活的测试数据。MIRAGE数据集能够评估大型语言模型(LLM)在归纳和演绎阶段的能力,并允许灵活地改变输入分布、任务场景和任务难度,从而分析影响LLM归纳推理的因素。通过多方面的评估,研究表明LLM在基于规则的推理方面表现不佳。在许多情况下,LLM在进行归纳推理时,并非依赖正确的规则来回答未见过的例子。研究还发现,从不同的提示方法、观察数量和任务形式来看,模型倾向于在没有正确归纳规则的情况下持续进行正确的演绎。此外,LLM擅长基于邻近的推理,在归纳推理过程中,模型倾向于关注特征空间中与当前测试示例接近的观察事实。通过利用这些相似的例子,模型在局部区域内保持强大的归纳能力,从而显著提高其演绎性能。
🔬 方法详解
问题定义:现有研究在评估大型语言模型(LLM)的归纳推理能力时,存在数据集不够全面、测试数据不够灵活的问题。这使得研究人员难以深入分析影响LLM归纳推理的关键因素,例如输入分布、任务场景和任务难度等。因此,需要一个更完善的数据集来更准确地评估和解释LLM的归纳推理过程。
核心思路:本文的核心思路是构建一个合成数据集MIRAGE,该数据集能够全面评估LLM在归纳和演绎两个阶段的推理能力。通过灵活地控制数据集的各种属性(如输入分布、任务场景、任务难度),研究人员可以系统地分析这些因素对LLM归纳推理的影响。此外,MIRAGE的设计允许研究人员探究LLM在进行归纳推理时所依赖的策略,例如是否遵循正确的规则,或者是否更倾向于基于邻近样本进行推理。
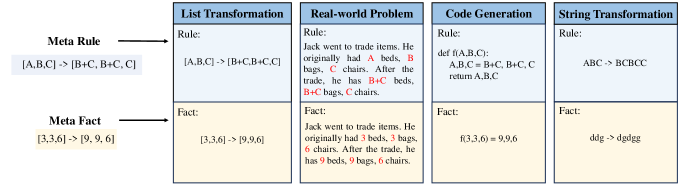
技术框架:MIRAGE数据集的构建框架主要包含以下几个阶段:1) 定义任务:确定需要LLM完成的归纳推理任务类型。2) 生成数据:根据定义的任务,生成包含观察事实和未见示例的数据集。3) 控制变量:灵活调整输入分布、任务场景和任务难度等变量,以评估其对LLM推理能力的影响。4) 评估模型:使用MIRAGE数据集评估LLM在归纳和演绎阶段的性能。5) 解释推理过程:分析LLM的推理过程,例如是否遵循正确的规则,或者是否更倾向于基于邻近样本进行推理。
关键创新:MIRAGE数据集的关键创新在于其能够提供全面且灵活的归纳推理评估。与以往的数据集相比,MIRAGE允许研究人员更精细地控制各种影响因素,从而更深入地了解LLM的归纳推理机制。此外,MIRAGE的设计还允许研究人员探究LLM在推理过程中所依赖的策略,这有助于揭示LLM的内在工作原理。
关键设计:MIRAGE数据集的关键设计包括:1) 多样化的任务场景:包含多种不同类型的归纳推理任务,以评估LLM在不同场景下的泛化能力。2) 可控的输入分布:允许研究人员控制输入数据的分布,以评估LLM对不同分布的适应能力。3) 可变的任务难度:提供不同难度的任务,以评估LLM在不同难度下的表现。4) 详细的标注信息:提供详细的标注信息,包括正确的规则和邻近样本,以便研究人员分析LLM的推理过程。
🖼️ 关键图片
📊 实验亮点
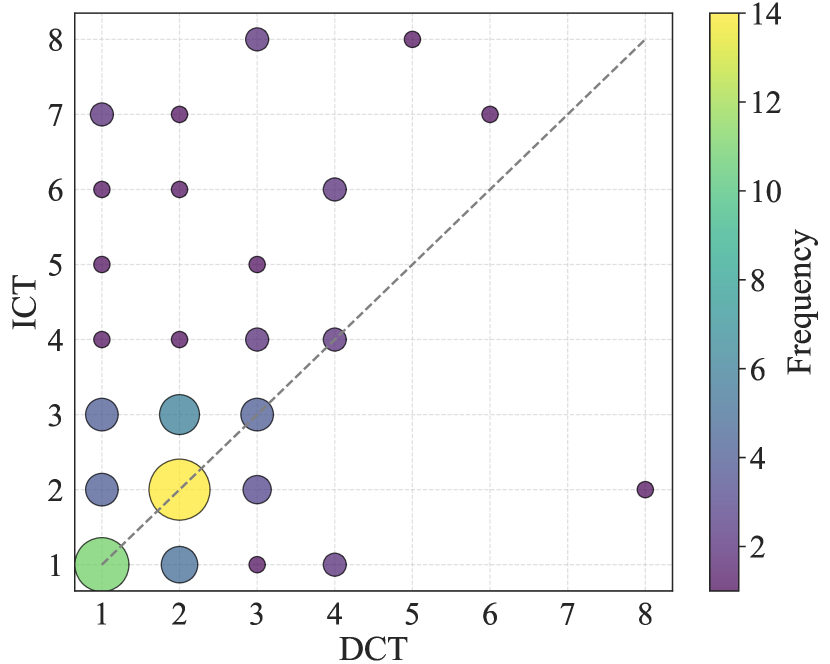
实验结果表明,LLM在进行归纳推理时,并非总是依赖正确的规则,而是更倾向于基于邻近样本进行推理。在局部区域内,LLM的归纳能力较强,能够显著提高演绎性能。例如,通过调整提示方法和观察数量,可以观察到模型在没有正确归纳规则的情况下,仍然能够进行正确的演绎。
🎯 应用场景
该研究成果可应用于提升大型语言模型的推理能力,尤其是在需要从少量样本中进行泛化的场景。例如,在医疗诊断、金融风险评估等领域,模型需要根据有限的数据进行准确的预测和决策。MIRAGE数据集可以帮助研究人员更好地理解和改进LLM的归纳推理能力,从而提高其在这些领域的应用效果。
📄 摘要(原文)
Inductive reasoning is an essential capability for large language models (LLMs) to achieve higher intelligence, which requires the model to generalize rules from observed facts and then apply them to unseen examples. We present MIRAGE, a synthetic dataset that addresses the limitations of previous work, specifically the lack of comprehensive evaluation and flexible test data. In it, we evaluate LLMs' capabilities in both the inductive and deductive stages, allowing for flexible variation in input distribution, task scenario, and task difficulty to analyze the factors influencing LLMs' inductive reasoning. Based on these multi-faceted evaluations, we demonstrate that the LLM is a poor rule-based reasoner. In many cases, when conducting inductive reasoning, they do not rely on a correct rule to answer the unseen case. From the perspectives of different prompting methods, observation numbers, and task forms, models tend to consistently conduct correct deduction without correct inductive rules. Besides, we find that LLMs are good neighbor-based reasoners. In the inductive reasoning process, the model tends to focus on observed facts that are close to the current test example in feature space. By leveraging these similar examples, the model maintains strong inductive capabilities within a localized region, significantly improving its deductive performance.