Rethinking Data Selection at Scale: Random Selection is Almost All You Need
作者: Tingyu Xia, Bowen Yu, Kai Dang, An Yang, Yuan Wu, Yuan Tian, Yi Chang, Junyang Lin
分类: cs.CL, cs.AI
发布日期: 2024-10-12 (更新: 2024-12-09)
💡 一句话要点
大规模SFT数据选择:随机选择性能接近最优,数据多样性至关重要
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大规模SFT 数据选择 随机选择 数据多样性 Token长度过滤 LLM微调 Llama3
📋 核心要点
- 现有数据选择方法难以有效处理大规模SFT场景,无法从中选取具有代表性的子集。
- 研究表明,大规模数据集中,随机选择策略表现接近最优,数据多样性比单纯追求高质量更重要。
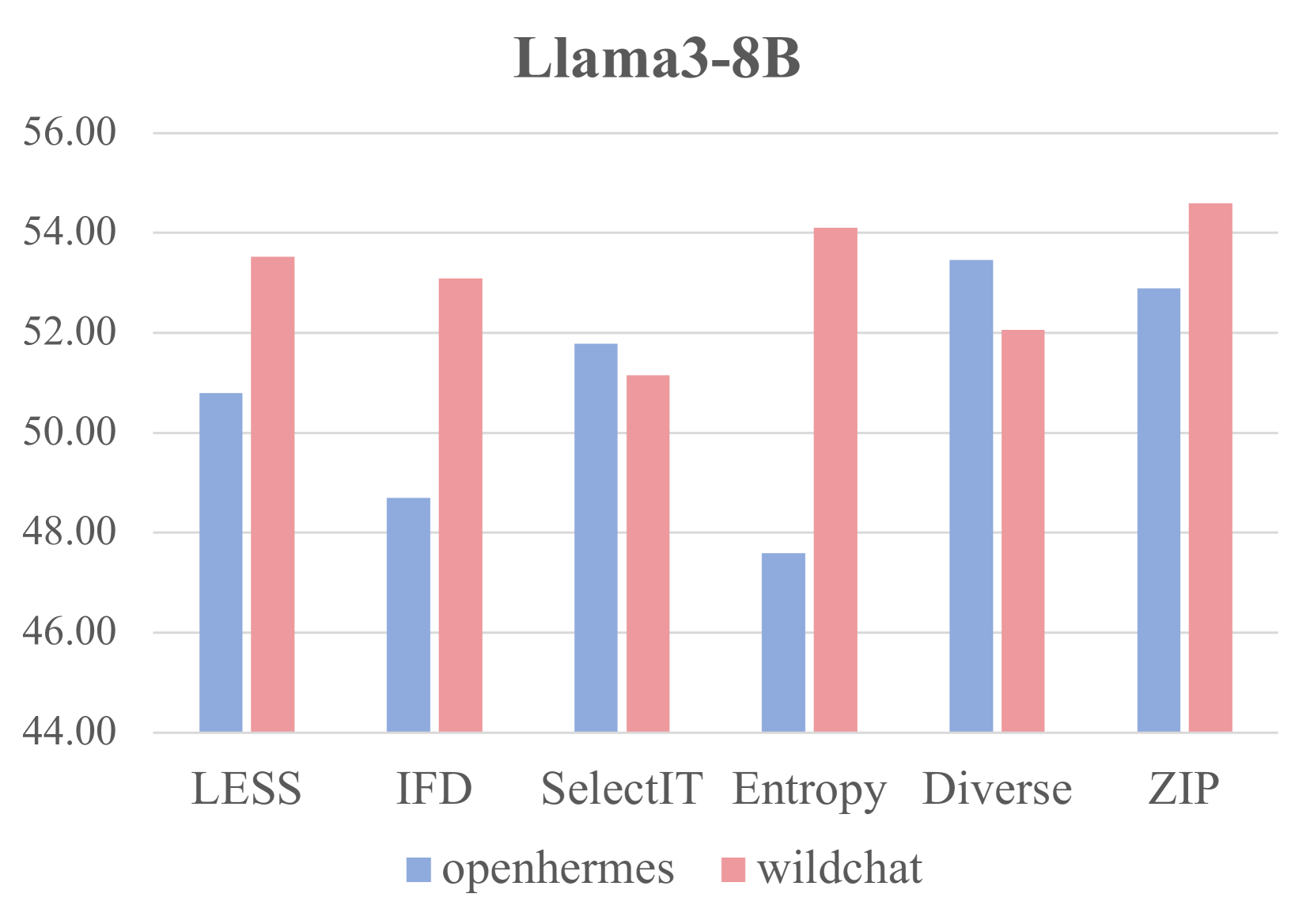
- 通过token长度过滤数据,是一种稳定且高效的改进方法,尤其适用于训练较弱的基础模型。
📝 摘要(中文)
监督式微调(SFT)对于将大型语言模型(LLM)与人类指令对齐至关重要。SFT的主要目标是从较大的数据池中选择一个小的但具有代表性的训练数据子集,使得使用该子集进行微调所获得的结果可以与使用整个数据集获得的结果相媲美甚至超过。然而,大多数现有的数据选择技术都是为小规模数据池设计的,无法满足实际SFT场景的需求。本文在两百万规模的数据集上复制了几种不依赖外部模型辅助的自评分方法,发现当处理如此大规模的数据池时,几乎所有方法都难以显著优于随机选择。此外,我们的比较表明,在SFT期间,数据选择的多样性比仅仅关注高质量数据更为重要。我们还分析了几种当前方法的局限性,解释了它们为什么在大规模数据集上表现不佳,以及为什么它们不适合这种环境。最后,我们发现按token长度过滤数据提供了一种稳定有效的方法来改进结果。这种方法,特别是在长文本数据上训练时,对于相对较弱的基础模型(如Llama3)非常有益。
🔬 方法详解
问题定义:论文旨在解决大规模监督式微调(SFT)中数据选择的问题。现有数据选择方法,如基于模型评分的方法,在小规模数据集上表现良好,但在大规模数据集上计算成本高昂,且性能提升有限,甚至不如随机选择。这些方法无法有效提取大规模数据集中最具代表性的子集,导致SFT效率低下。
核心思路:论文的核心思路是质疑现有复杂数据选择方法在大规模SFT中的有效性,并提出数据多样性比单纯追求高质量更重要。通过实验验证,随机选择策略在大规模数据集上表现出惊人的竞争力。此外,论文还探索了基于token长度的数据过滤方法,以提升模型在长文本数据上的训练效果。
技术框架:论文主要通过实验对比不同数据选择方法在大型数据集上的性能。实验流程包括:1) 构建大规模数据集;2) 实施多种数据选择策略,包括随机选择和基于自评分的方法;3) 使用选定的数据子集对LLM进行SFT;4) 评估SFT后的模型性能。论文还分析了现有方法的局限性,并提出了基于token长度的数据过滤方法。
关键创新:论文最重要的创新点在于挑战了现有数据选择方法在大规模SFT中的有效性,并指出随机选择策略的竞争力。此外,论文强调了数据多样性在SFT中的重要性,并提出了基于token长度的数据过滤方法,为大规模SFT提供了一种简单有效的解决方案。
关键设计:论文的关键设计包括:1) 使用大规模数据集(两百万规模)进行实验,以模拟真实SFT场景;2) 复制并比较多种自评分方法,以评估其在大规模数据集上的性能;3) 分析现有方法的局限性,并提出基于token长度的数据过滤方法;4) 使用Llama3等模型进行实验,验证所提出方法的有效性。具体参数设置和损失函数等细节未在摘要中提及,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在大规模数据集上,现有复杂的数据选择方法难以显著优于随机选择。基于token长度的数据过滤方法能够有效提升模型在长文本数据上的训练效果,尤其对于Llama3等相对较弱的基础模型,效果更为显著。具体性能提升数据未知。
🎯 应用场景
该研究成果可应用于大规模语言模型的预训练和微调阶段,尤其是在资源有限的情况下,可以采用随机抽样或基于token长度过滤的方法来选择训练数据,从而提高训练效率和模型性能。该研究对于降低LLM训练成本、加速模型迭代具有重要意义。
📄 摘要(原文)
Supervised fine-tuning (SFT) is crucial for aligning Large Language Models (LLMs) with human instructions. The primary goal during SFT is to select a small yet representative subset of training data from the larger pool, such that fine-tuning with this subset achieves results comparable to or even exceeding those obtained using the entire dataset. However, most existing data selection techniques are designed for small-scale data pools, which fail to meet the demands of real-world SFT scenarios. In this paper, we replicated several self-scoring methods those that do not rely on external model assistance on two million scale datasets, and found that nearly all methods struggled to significantly outperform random selection when dealing with such large-scale data pools. Moreover, our comparisons suggest that, during SFT, diversity in data selection is more critical than simply focusing on high quality data. We also analyzed the limitations of several current approaches, explaining why they perform poorly on large-scale datasets and why they are unsuitable for such contexts. Finally, we found that filtering data by token length offers a stable and efficient method for improving results. This approach, particularly when training on long text data, proves highly beneficial for relatively weaker base models, such as Llama3.