The Same But Different: Structural Similarities and Differences in Multilingual Language Modeling
作者: Ruochen Zhang, Qinan Yu, Matianyu Zang, Carsten Eickhoff, Ellie Pavlick
分类: cs.CL, cs.AI
发布日期: 2024-10-11
💡 一句话要点
利用机制可解释性探究多语言模型中语言结构的处理方式
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言模型 机制可解释性 形态句法 跨语言学习 内部电路 注意力机制 前馈网络
📋 核心要点
- 现有研究缺乏对LLM内部如何处理不同语言的形态句法异同的深入理解。
- 通过机制可解释性工具,分析LLM内部电路对不同语言中相同/不同形态句法过程的处理方式。
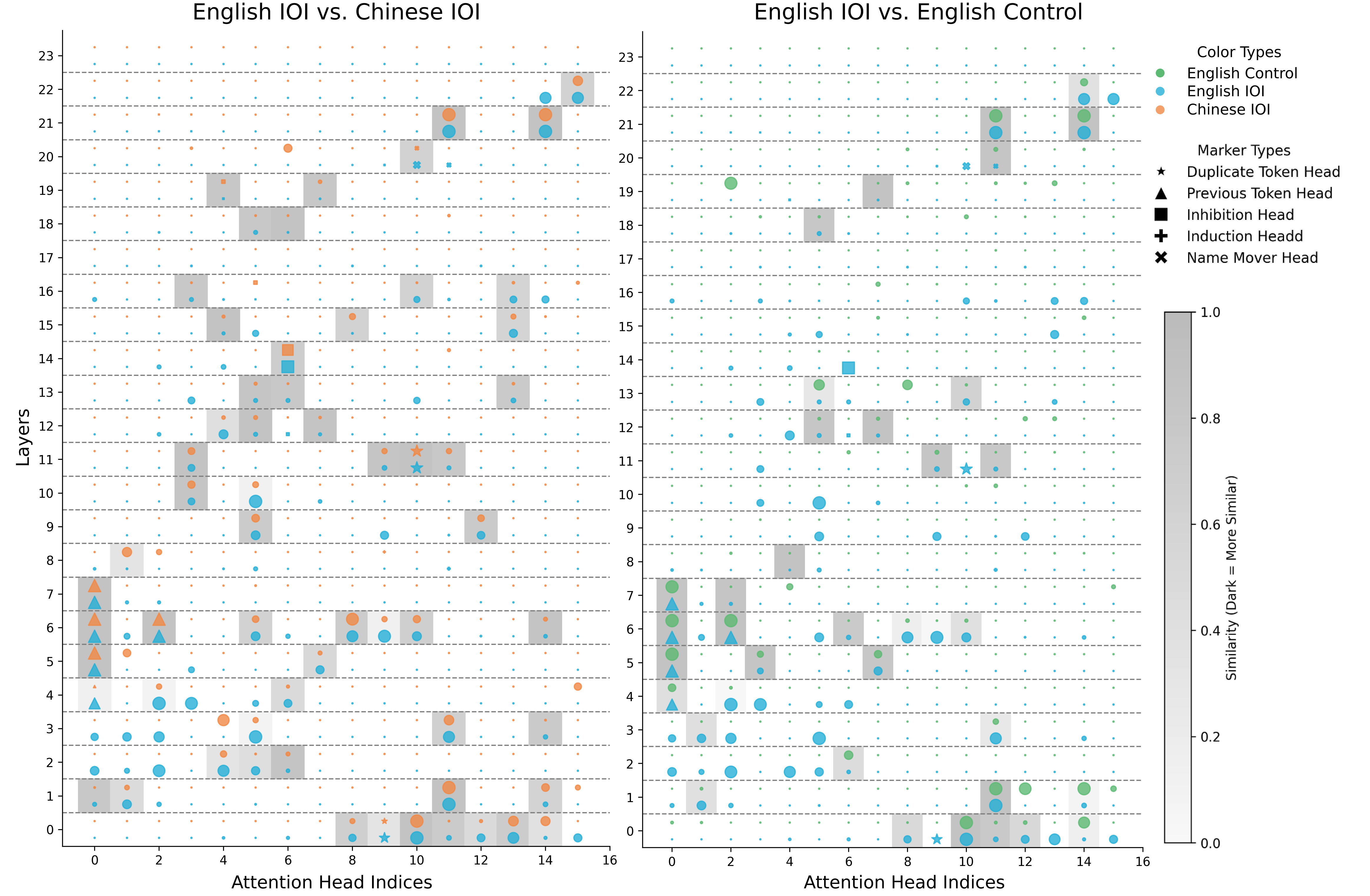
- 实验表明LLM对相同过程使用共享电路,对不同过程使用特定语言组件,揭示了其权衡策略。
📝 摘要(中文)
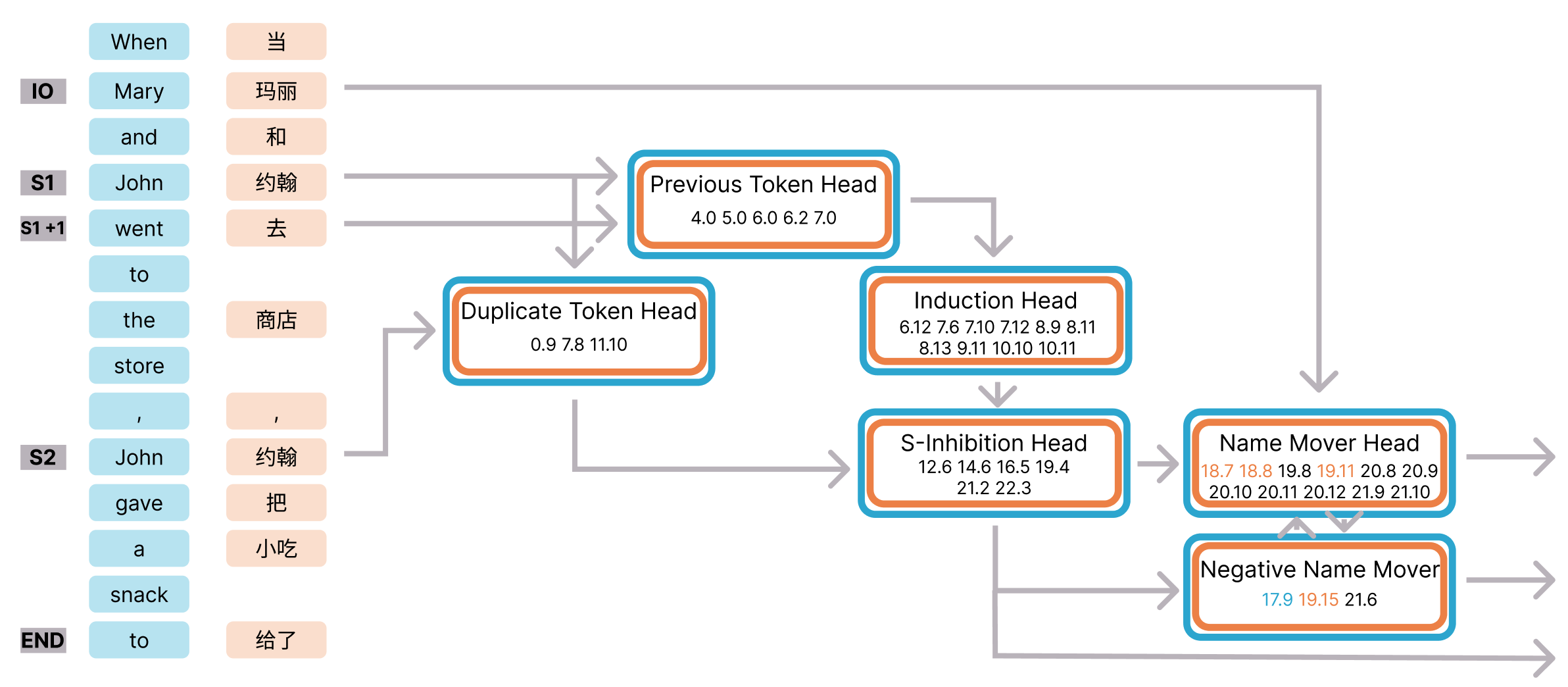
本文利用机制可解释性的新工具,研究大型语言模型(LLM)的内部结构是否与其训练语言的底层语言结构相对应。具体而言,我们探究了两个问题:(1)当两种语言采用相同的形态句法过程时,LLM是否使用共享的内部电路来处理它们?(2)当两种语言需要不同的形态句法过程时,LLM是否使用不同的内部电路来处理它们?我们使用英语和中文的多语言和单语模型,分析了两个任务中涉及的内部电路。我们发现,模型使用相同的电路来处理相同的句法过程,而与它发生的语言无关,即使是完全独立训练的单语模型也是如此。此外,我们表明,多语言模型在需要处理仅存在于某些语言中的语言过程(例如,形态标记)时,会使用特定于语言的组件(注意力头和前馈网络)。总之,我们的结果为LLM如何在同时建模多种语言时,在利用共同结构和保留语言差异之间进行权衡提供了新的见解。
🔬 方法详解
问题定义:论文旨在理解大型语言模型(LLM)如何处理不同语言的形态句法结构,特别是当两种语言共享相同的句法过程或需要不同的句法过程时,LLM的内部机制如何运作。现有方法缺乏对LLM内部电路的细粒度分析,无法解释其跨语言处理能力的来源。
核心思路:论文的核心思路是利用机制可解释性技术,深入剖析LLM的内部结构,观察其在处理不同语言的特定任务时,哪些神经元或电路被激活,以及这些激活模式是否与语言的形态句法特征相关。通过比较不同语言模型(包括单语和多语模型)在处理相同或不同句法过程时的内部表示,来揭示LLM是如何在共享结构和语言特定组件之间进行权衡的。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择具有代表性的语言(英语和中文)和任务(具体任务未明确说明,但与形态句法相关);2) 训练或使用预训练的单语和多语LLM;3) 利用机制可解释性工具(具体工具未明确说明,但可能包括注意力可视化、神经元激活分析等)分析LLM在处理特定任务时的内部表示;4) 比较不同语言模型在处理相同或不同句法过程时的内部电路激活模式,寻找共享或特定于语言的组件。
关键创新:论文的关键创新在于将机制可解释性技术应用于多语言模型的研究,从而能够更深入地理解LLM是如何学习和表示不同语言的。通过分析LLM的内部电路,揭示了其在处理共享句法过程时使用共享电路,而在处理特定于语言的句法过程时使用特定组件的机制。这种细粒度的分析为理解LLM的跨语言迁移学习能力提供了新的视角。
关键设计:论文的关键设计包括:1) 选择具有代表性的语言和任务,以便能够有效地研究LLM的跨语言处理能力;2) 使用单语和多语模型进行对比,以便能够区分共享和特定于语言的组件;3) 利用机制可解释性工具进行细粒度的内部表示分析,以便能够揭示LLM的内部电路激活模式;4) 设计合理的实验方案,以便能够验证LLM在处理相同或不同句法过程时使用不同电路的假设。具体的参数设置、损失函数、网络结构等技术细节在摘要中未提及,属于未知信息。
🖼️ 关键图片

📊 实验亮点
研究发现,LLM使用相同的内部电路来处理不同语言中相同的句法过程,即使是独立训练的单语模型也是如此。此外,多语言模型在处理特定于某些语言的语言过程时,会使用特定于语言的组件(注意力头和前馈网络)。具体的性能数据和提升幅度在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可应用于提升多语言模型的性能和可解释性。通过理解LLM如何处理不同语言的形态句法结构,可以设计更有效的多语言模型训练方法,并提高模型在低资源语言上的表现。此外,该研究也有助于开发更可靠的跨语言迁移学习技术,并为自然语言处理领域提供更深入的理论基础。
📄 摘要(原文)
We employ new tools from mechanistic interpretability in order to ask whether the internal structure of large language models (LLMs) shows correspondence to the linguistic structures which underlie the languages on which they are trained. In particular, we ask (1) when two languages employ the same morphosyntactic processes, do LLMs handle them using shared internal circuitry? and (2) when two languages require different morphosyntactic processes, do LLMs handle them using different internal circuitry? Using English and Chinese multilingual and monolingual models, we analyze the internal circuitry involved in two tasks. We find evidence that models employ the same circuit to handle the same syntactic process independently of the language in which it occurs, and that this is the case even for monolingual models trained completely independently. Moreover, we show that multilingual models employ language-specific components (attention heads and feed-forward networks) when needed to handle linguistic processes (e.g., morphological marking) that only exist in some languages. Together, our results provide new insights into how LLMs trade off between exploiting common structures and preserving linguistic differences when tasked with modeling multiple languages simultaneously.