Hybrid Training Approaches for LLMs: Leveraging Real and Synthetic Data to Enhance Model Performance in Domain-Specific Applications
作者: Alexey Zhezherau, Alexei Yanockin
分类: cs.CL
发布日期: 2024-10-11
备注: 22 pages, 7 figures
💡 一句话要点
提出混合训练方法,利用真实和合成数据提升LLM在领域特定应用中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 混合训练 合成数据 领域特定应用 数据增强
📋 核心要点
- 领域特定场景下,真实数据稀缺、噪声大,限制了LLM的性能提升。
- 提出混合训练方法,结合真实交互数据和高质量合成数据,增强模型训练的多样性。
- 实验表明,混合训练模型在特定垂直应用中表现最佳,提升了LLM的鲁棒性和上下文理解能力。
📝 摘要(中文)
本研究探索了一种混合方法来微调大型语言模型(LLM),通过整合真实世界和合成数据来提高模型性能,尤其是在生成准确且上下文相关的响应方面。通过利用结合了转录的真实交互和高质量合成会话的数据集,旨在克服稀缺、嘈杂和领域特定的真实数据的局限性。采用合成角色和场景来增强训练多样性。该研究评估了三个模型:基础模型、使用真实数据微调的模型和混合微调模型。实验结果表明,混合模型在特定的垂直应用中始终优于其他模型,在所有指标上都获得了最高分。进一步的测试证实了混合模型在各种场景中具有卓越的适应性和上下文理解能力。这些发现表明,结合真实和合成数据可以显著提高LLM的鲁棒性和上下文敏感性,尤其是在领域特定和垂直用例中。
🔬 方法详解
问题定义:论文旨在解决领域特定应用中,由于真实数据稀缺、质量不高(噪声大)而导致的大型语言模型(LLM)微调效果不佳的问题。现有方法要么依赖有限的真实数据,导致模型泛化能力不足;要么完全依赖合成数据,可能与真实场景存在偏差。
核心思路:论文的核心思路是将真实数据和合成数据结合起来进行混合训练。真实数据提供实际交互的模式,而合成数据则用于扩充训练集,增加数据多样性,弥补真实数据不足的缺陷。通过这种方式,模型既能学习到真实世界的知识,又能避免过拟合,提高泛化能力。
技术框架:整体框架包含数据准备、模型选择和训练、以及评估三个主要阶段。数据准备阶段包括收集真实交互数据并进行转录,以及生成高质量的合成会话数据。合成数据生成过程涉及定义合成角色和场景,以确保数据的多样性和相关性。模型选择和训练阶段则选择一个预训练的LLM作为基础模型,然后分别使用真实数据、合成数据以及混合数据进行微调。最后,通过一系列指标评估不同模型的性能。
关键创新:该方法最重要的创新点在于提出了一个有效的混合训练策略,巧妙地结合了真实数据和合成数据的优势。与单独使用真实数据或合成数据相比,该方法能够显著提高模型在领域特定应用中的性能和泛化能力。此外,通过精心设计的合成数据生成过程,确保了合成数据的质量和多样性,避免了引入过多噪声。
关键设计:论文中关键的设计包括合成数据的生成策略,例如如何定义合成角色和场景,以及如何控制合成数据的质量。此外,混合训练过程中,真实数据和合成数据的比例也是一个重要的参数。论文可能还涉及了特定的损失函数或正则化方法,用于平衡真实数据和合成数据的影响,防止模型过度拟合合成数据。
🖼️ 关键图片


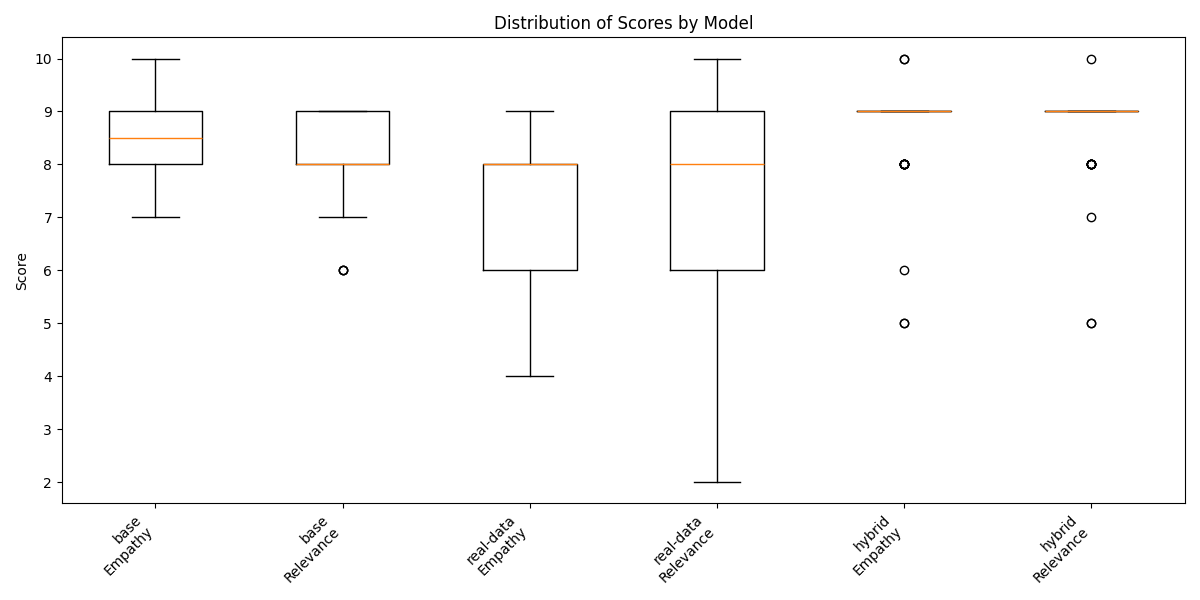
📊 实验亮点
实验结果表明,混合训练模型在特定垂直应用中始终优于仅使用真实数据或基础模型。混合模型在所有评估指标上都获得了最高分,验证了其在适应性和上下文理解方面的优越性。这些结果表明,结合真实和合成数据可以显著提高LLM的鲁棒性和上下文敏感性。
🎯 应用场景
该研究成果可广泛应用于各种领域特定的大型语言模型应用,例如智能客服、医疗诊断助手、金融分析等。通过结合真实数据和合成数据,可以有效提升模型在数据稀缺领域的性能,降低数据收集成本,加速LLM在垂直领域的落地。未来,该方法有望进一步推广到其他模态的数据,例如图像、语音等。
📄 摘要(原文)
This research explores a hybrid approach to fine-tuning large language models (LLMs) by integrating real-world and synthetic data to boost model performance, particularly in generating accurate and contextually relevant responses. By leveraging a dataset combining transcribed real interactions with high-quality synthetic sessions, we aimed to overcome the limitations of scarce, noisy, and domain-specific real data. Synthetic personas and scenarios were employed to enhance training diversity. The study evaluated three models: a base foundational model, a model fine-tuned with real data, and a hybrid fine-tuned model. Experimental results showed that the hybrid model consistently outperformed the others in specific vertical applications, achieving the highest scores across all metrics. Further testing confirmed the hybrid model's superior adaptability and contextual understanding across diverse scenarios. These findings suggest that combining real and synthetic data can significantly improve the robustness and contextual sensitivity of LLMs, particularly in domain-specific and vertical use cases.