SimpleStrat: Diversifying Language Model Generation with Stratification
作者: Justin Wong, Yury Orlovskiy, Michael Luo, Sanjit A. Seshia, Joseph E. Gonzalez
分类: cs.CL, cs.AI
发布日期: 2024-10-11 (更新: 2024-10-14)
💡 一句话要点
SimpleStrat:通过分层抽样提升语言模型生成的多样性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 多样性生成 分层抽样 大语言模型 模型推理
📋 核心要点
- 现有方法通过提高温度来增加LLM生成的多样性,但会降低生成质量,且依赖于模型概率分布的准确性。
- SimpleStrat利用语言模型自身进行分层,推理时随机选择一层并从中采样,以提升生成结果的多样性。
- 实验表明,SimpleStrat在CoverageQA数据集上,相较于GPT-4o和Llama 3,分别提升了召回率和降低了KL散度。
📝 摘要(中文)
从大型语言模型(LLM)生成多样化的响应对于规划/搜索和合成数据生成等应用至关重要,在这些应用中,多样性提供了不同的答案。先前的研究依赖于提高温度来增加多样性。然而,与普遍的看法相反,我们表明,随着温度的升高,这种方法不仅会降低单个生成的质量,而且还取决于模型的下一个token概率是否与答案的真实分布相似。我们提出了一种替代方法SimpleStrat,它使用语言模型本身将空间划分为不同的层。在推理时,随机选择一个层,并从该层中抽取一个样本。为了衡量多样性,我们引入了CoverageQA,这是一个包含多个同样合理的答案的欠指定问题的数据集,并通过测量输出分布与有效ground truth答案上的均匀分布之间的KL散度来评估多样性。由于计算专有模型的每个响应/解决方案的概率是不可行的,因此我们测量ground truth解决方案的召回率。我们的评估表明,与GPT-4o相比,使用SimpleStrat实现了更高的召回率(高出0.05),与Llama 3相比,KL散度平均降低了0.36。
🔬 方法详解
问题定义:现有方法,如提高温度,在增加语言模型生成多样性时,会降低单个生成结果的质量。此外,这些方法依赖于模型预测的下一个token概率分布与真实答案分布的相似性,这在实际中难以保证。因此,需要一种更有效、更可靠的方法来提升语言模型生成的多样性,尤其是在答案分布未知或难以估计的情况下。
核心思路:SimpleStrat的核心思路是利用语言模型本身的能力,将可能的答案空间划分为多个不同的“层”(strata)。每个层代表答案空间的一个子集,通过从不同的层中进行采样,可以有效地增加生成结果的多样性。这种方法避免了直接操纵温度等参数,从而减少了对模型概率分布准确性的依赖。
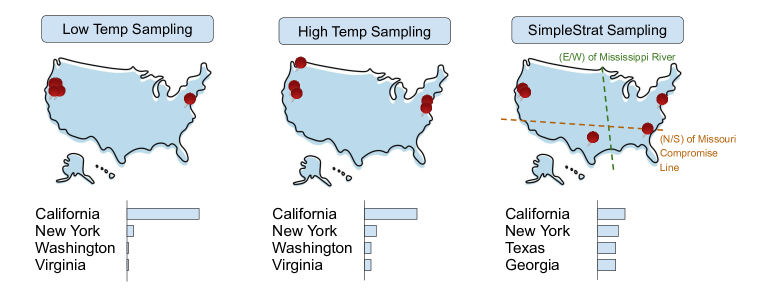
技术框架:SimpleStrat的整体流程包括两个主要阶段:分层阶段和采样阶段。在分层阶段,使用语言模型生成多个候选答案,并根据某种标准(例如,语义相似度)将这些答案聚类成不同的层。在采样阶段,首先随机选择一个层,然后从该层中抽取一个样本作为最终的生成结果。整个框架的关键在于如何有效地进行分层,以及如何保证每个层内部的答案具有一定的相似性,同时层与层之间具有足够的差异性。
关键创新:SimpleStrat的关键创新在于利用语言模型自身进行分层,而不是依赖于外部的聚类算法或人工定义的规则。这种方法能够更好地利用语言模型的语义理解能力,从而生成更具多样性和质量的答案。此外,SimpleStrat通过随机选择层进行采样,避免了对特定层的偏好,从而保证了生成结果的公平性。
关键设计:SimpleStrat的关键设计包括:1) 使用语言模型生成候选答案时,可以采用不同的prompt策略,以探索更广泛的答案空间;2) 在进行聚类时,可以采用不同的相似度度量方法,例如,基于词向量的余弦相似度或基于语义表示的相似度;3) 在选择层时,可以采用均匀分布或基于层大小的概率分布;4) 可以引入额外的过滤步骤,以去除质量较低的答案。
🖼️ 关键图片

📊 实验亮点
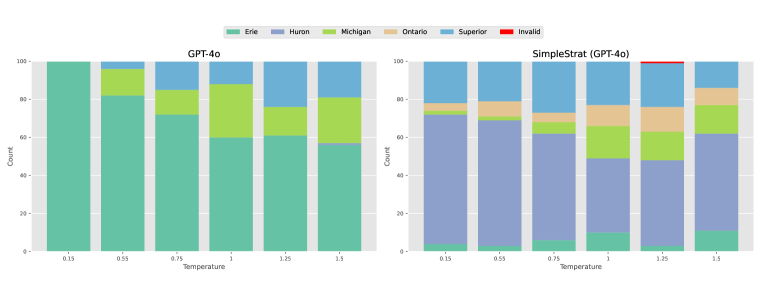
实验结果表明,SimpleStrat在CoverageQA数据集上显著提升了生成结果的多样性。与GPT-4o相比,SimpleStrat的召回率提高了0.05。与Llama 3相比,SimpleStrat的KL散度平均降低了0.36,表明其生成结果的分布更接近于均匀分布,从而实现了更高的多样性。
🎯 应用场景
SimpleStrat可应用于需要多样化输出的场景,如规划与搜索(为同一目标提供多种解决方案)、合成数据生成(扩充训练数据集,提升模型泛化能力)以及头脑风暴(激发创新想法)。该方法能提升LLM在这些场景下的实用性和创造性,具有广泛的应用前景。
📄 摘要(原文)
Generating diverse responses from large language models (LLMs) is crucial for applications such as planning/search and synthetic data generation, where diversity provides distinct answers across generations. Prior approaches rely on increasing temperature to increase diversity. However, contrary to popular belief, we show not only does this approach produce lower quality individual generations as temperature increases, but it depends on model's next-token probabilities being similar to the true distribution of answers. We propose SimpleStrat, an alternative approach that uses the language model itself to partition the space into strata. At inference, a random stratum is selected and a sample drawn from within the strata. To measure diversity, we introduce CoverageQA, a dataset of underspecified questions with multiple equally plausible answers, and assess diversity by measuring KL Divergence between the output distribution and uniform distribution over valid ground truth answers. As computing probability per response/solution for proprietary models is infeasible, we measure recall on ground truth solutions. Our evaluation show using SimpleStrat achieves higher recall by 0.05 compared to GPT-4o and 0.36 average reduction in KL Divergence compared to Llama 3.